Container-Plattformen im Enterprise Datacenter

Kann eine Container-Plattform eine Alternative für die klassischen Hypervisoren sein? In diesem Zusammenhang sind die Referenzarchitekturen von HPE äußerst interessant. Mehr dazu erfahren Sie in dieser aktuellen Ausgabe unseres Datacenter-Newsletters.
Nach dem ersten Boom der Cloud-Technologie liegt das Hauptaugenmerk nun auf Effizienz, Optimierung und Nachhaltigkeit, die zu Schlüsselfaktoren für den Erfolg von Unternehmen geworden sind. Wir erläutern, welche Herausforderungen dabei zu bewältigen sind und wie man das Ziel am besten erreicht.
Nach der Übernahme von VMware durch Broadcom haben sich das Produktportfolio und das Lizenzierungsmodell geändert. Dadurch kann für Unternehmen und öffentliche Organisationen eine neue IT-Strategie sinnvoll oder gar nötig sein. Eine strukturierte Vorgehensweise hilft dabei, die bestmögliche Entscheidung zu treffen. Wir geben konkrete Tipps.
Lesen Sie außerdem, welche Aufgaben ein Open Source Program Office (OSPO) übernimmt und inwiefern es wertschöpfend zu den Zielen eines Unternehmens oder zum Auftrag von Behörden beiträgt.
Unsere aktuelle Agile-IT-Kolumne beschäftigt sich mit agilen Metriken und wie man sie am besten definiert und implementiert. Und unsere Back-up-Kolumne zeigt, weshalb auch Container eine Datensicherung benötigen, welche Anforderungen diese vor allem erfüllen sollte und wie sie in der Praxis umgesetzt werden kann.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter wurde von der Information Services Group (ISG) für seine Circular Services ausgezeichnet. Diese ermöglicht den Kunden, durch Wiederverwendung, Wiedervermarktung oder Recycling einen größtmöglichen Nutzen aus ihren nicht mehr benötigten IT-Geräten zu ziehen.
Weitere InfosDie Computacenter plc. hat ihre Geschäftsergebnisse für das Jahr 2023 bekannt gegeben: Danach stieg der Umsatz in Deutschland bei Zugrundelegung konstanter Wechselkurse um 8 Prozent auf 2,028 Milliarden Britische Pfund (2022: 1,844 Milliarden Britische Pfund).
Weitere Infos
Dirk Hannemann
Seitdem Broadcom durch die Übernahme von VMware ein allgemeines Um- beziehungsweise Neudenken in Bezug auf virtuelle Umgebungen im Datacenter losgetreten hat, rücken die häufig den Cloud-Native-Applikationen vorbehaltenen Container-Plattformen in den Fokus. In diesem Artikel beleuchten wir weitere Einsatzmöglichkeiten.
Häufig werden Kubernetes und Co. noch immer den Cloud-Native-Applikationen zugeschrieben. Diese Meinung ändert sich jedoch allmählich. Vor allem wegen der diversen Hypervisor-Alternativen – im Rahmen der Broadcom-Ausrichtung – kann sich eine solche Schwarz-Weiß-Betrachtung nicht mehr halten. Aber neben der prinzipiellen Frage, ob eine Container-Plattform eine Alternative für die klassischen Hypervisoren ist oder nicht, stellt sich eine weitere: Welche Storage-Technologien setzt man unter einer Container-Plattform ein und wie wird diese gesichert? Denn eine Migration oder Transformation weg von der VM in einen Container ist im Rahmen einer ganzheitlichen operationalen Resilienz nur ein kleiner Baustein von vielen, wenn auch ein sehr wichtiger, der gern vergessen oder unterschätzt wird.
Mehr zu diesem Thema finden Sie in dieser Newsletter-Ausgabe in unserer Backup-Kolumne.
Diesen Fragen hat sich HPE schon zu Beginn der Container-Plattform-Diskussion angenommen, denn Container können „hybrid“ eingesetzt werden, also sowohl On-Premises als auch in der Public beziehungsweise Private Cloud (AWS: EKS, Google: GKE, Azure: AKS).
Werfen wir zunächst einen groben Blick darauf, wie sich eine typische Kubernetes-Landschaft darstellt.

Essenziell sind dabei jedoch zwei Komponenten: Storage und Backup im Allgemeinen und die Partnerlandschaft und Integrationen sowohl per Schnittstellen (CSI für Storage) als auch ISVs für das Backup im Speziellen. Hier gilt es, die richtige Wahl zu treffen, um eine ähnliche operationale Resilienz und Wiederherstellungsfähigkeit zu ermöglichen, wie man das aus der klassischen Hypervisor-Welt gewohnt ist.

Bei einem Wechsel zu einer Container-Plattform ist es definitiv angebracht, sich mit Herstellern wie HPE zu beschäftigen, die dieses Thema schon von Anbeginn im Blick hatten und deren Strategie sich nun für Kund:innen auszahlen könnte. Sollten Sie Fragen zu diesem Themenkomplex haben, beraten wir Sie gern persönlich. Wenden Sie sich dazu einfach an Ihre/Ihren Ansprechpartner:in bei Computacenter.

Jessica Linke
Seit der Einführung der ersten Cloud-Dienste hat sich die Technologie rasant weiterentwickelt und ist immer komplexer geworden. Nun liegt das Hauptaugenmerk auf Effizienz, Optimierung und Nachhaltigkeit, die zu Schlüsselfaktoren für den Erfolg von Unternehmen geworden sind. Doch wie erreicht man sie am besten?
In der dynamischen Welt der Informationstechnologie hat sich die Cloud-Technologie als revolutionärer Wendepunkt erwiesen, der die Art und Weise, wie Unternehmen ihre IT-Infrastruktur verwalten und nutzen, grundlegend verändert hat. Bei der Cloud-Effizienz, einem zentralen Aspekt dieser Transformation, geht es darum, das definierte Ziel von Unternehmen mit minimalem Einsatz bei der Nutzung von Cloud-Ressourcen zu erreichen. Darüber hinaus spielt die Cloud-Effizienz eine entscheidende Rolle bei der Förderung der Nachhaltigkeit, da sie dazu beiträgt, den Energieverbrauch zu reduzieren und den Elektronikschrott zu minimieren. Zudem ist die Cloud-Effizienz für Unternehmen aller Größen und Branchen von Bedeutung, da sie nicht nur erhebliche Kosteneinsparungen ermöglicht, sondern auch die Agilität und Skalierbarkeit verbessert, die für das Wachstum und die Innovation in der heutigen digitalen Wirtschaft unerlässlich sind.
Cloud-Effizienz und -Optimierung sind entscheidende Aspekte in der modernen IT-Landschaft. Cloud-Effizienz bezieht sich auf die Maximierung des Nutzens, den Unternehmen aus ihren Cloud-Ressourcen ziehen, indem sie die Nutzung optimieren und Verschwendung reduzieren, um ihre Ziele zu erreichen. Cloud-Optimierung hingegen ist der Prozess der Anpassung und Verbesserung der Cloud-Infrastruktur und -Dienste, um die Leistung zu verbessern, Kosten zu senken und die Sicherheit zu erhöhen.
Die Vorteile der Cloud-Effizienz und -Optimierung sind somit vielfältig. Sie können auf der einen Seite zu erheblichen Kosteneinsparungen führen, da Unternehmen nur für die Ressourcen bezahlen, die sie tatsächlich nutzen. Auf der anderen Seite kann eine optimierte Cloud-Umgebung die Applikationsleistung und die Benutzer:innenerfahrung verbessern, indem sie sicherstellt, dass Anwendungen und Dienste reibungslos und effizient laufen.
Ein Beispiel für eine Cloud-Optimierung könnte eine Implementierung von automatisierten Skalierungsstrategien sein. Wenn eine Anwendung plötzlich einen Anstieg der Auslastung erfährt – man denke an einen Webshop am Black Friday –, kann eine automatisierte Skalierungsstrategie zusätzliche Ressourcen bereitstellen, um die Last zu bewältigen. Wenn die Last wieder abnimmt, werden die zusätzlichen Ressourcen automatisch heruntergefahren, um Kosten oder Ressourcen einzusparen.
Dies ist nur ein Beispiel für die vielen Möglichkeiten, wie Cloud-Effizienz und -Optimierung Unternehmen dabei helfen können, das Beste aus ihrer Cloud-Investition herauszuholen. Und damit sind nicht nur Kosteneinsparungen gemeint.
Eine Cloud-Optimierung sollte immer mit einer klaren Definition der Ziele und Anforderungen, die man mit der Optimierung erreichen möchte, beginnen. Diese Definition ist nicht fix, sondern es empfiehlt sich, sie kontinuierlich anhand neuer Anforderungen oder aufgrund einer geänderten Ausgangslage zu überprüfen.
Ein guter Ausgangspunkt für den Start wäre die Analyse der aktuellen Workloads und damit eine Identifizierung von Bereichen, in denen Verbesserungen grundsätzlich möglich sind. Ein Quick Win dieser Analyse könnte beispielsweise sein, ungenutzte Ressourcen zu identifizieren oder Optimierungspotenziale bezüglich der Speicher- und Netzwerknutzung aufzudecken.
Ein weiterer Punkt in Sachen Optimierung ist die Auswahl des Hyperscalers bezogen auf den spezifischen Anwendungsfall. Schließlich besitzen die unterschiedlichen Hyperscaler unterschiedliche Stärken, und es ist wichtig, einen Anbieter zu wählen, der die spezifischen Anforderungen am besten erfüllt.
Nehmen wir an, das Kerngeschäft eines Unternehmens ist abhängig von maschinellem Lernen und auf künstliche Intelligenz (KI) ausgerichtet. In diesem Fall könnte die Cloud eine gute Wahl sein, da die Hyperscaler starke Fähigkeiten und Dienste in diesen Bereichen bieten, einschließlich vorab trainierter Modelle und Dienste als Basis für Trainings eigener Modelle.
Es ist wichtig zu beachten, dass dies nur Beispiele sind und die beste Wahl des Hyperscalers von vielen Faktoren abhängt, einschließlich der spezifischen Anforderungen und Ziele eines Unternehmens.
Das Kostenmanagement ist ein weiterer wichtiger Aspekt der Cloud-Optimierung. Durch die Überwachung der Ausgaben und die Anpassung der Cloud-Nutzung an die Budgetanforderungen kann sichergestellt werden, dass das Beste aus den einzelnen Investitionen herausgeholt wird. Die Ressourcenallokation ist ein weiterer Schlüsselbereich. Durch die effiziente Zuweisung von Ressourcen kann sichergestellt werden, dass die Anwendungen immer die benötigte Leistung haben, ohne für ungenutzte Kapazitäten zahlen zu müssen. Die Erfahrung hat gezeigt, dass dieses Thema dezentral gelöst werden sollte. Die Verantwortung für das Management der Kosten sollte in den Bereichen des Unternehmens liegen, in denen sie auch erzeugt werden, also in den Teams, deren Workloads die Cloud-Ressourcen nutzen.
Diese Ressourcenallokation ist vor allem durch den Einsatz von Automatisierung möglich. Die Automatisierung und damit auch die Skalierung von Ressourcen sind entscheidend für eine Maximierung der Cloud-Effizienz. Durch die Automatisierung von Routineaufgaben und die dynamische Skalierung der Applikationsressourcen kann sichergestellt werden, dass die Infrastruktur immer optimal ausgenutzt wird.
Ein praktisches Beispiel könnte ein Unternehmen sein, das eine E-Commerce-Website betreibt. Durch die Analyse der Workloads wurde festgestellt, dass während der Geschäftszeiten eine hohe Nachfrage besteht, aber in den Abendstunden weniger. Daher könnte man die Infrastrukturressourcen für die Website so skalieren, dass sie während der Stoßzeiten mehr Kapazität haben und in den ruhigeren Zeiten Kosten sparen. Gleichzeitig könnte das Unternehmen durch die Automatisierung von Aufgaben wie der Datensicherung und dem Patch-Management die Betriebskosten der Applikation senken. Dies ist nur ein Beispiel, aber es zeigt, wie die Prinzipien der Cloud-Optimierung in der Praxis angewendet werden können.
Wie bereits erwähnt, ist in der heutigen digitalen Welt die Cloud-Optimierung ein entscheidender Faktor für die Effizienz und Leistungsfähigkeit von Unternehmen. Allerdings ist sie mit einigen Herausforderungen verbunden, von denen eine der größten die Kostenkontrolle ist. Die dynamische Natur der Cloud oder auch die Komplexität einer Multi-Cloud-Strategie kann dazu führen, dass die Kosten schnell außer Kontrolle geraten, wenn sie nicht sorgfältig überwacht werden.
Ein weiteres Problem ist die Performance-Optimierung. Die Gewährleistung einer hohen Leistung bei gleichzeitiger Minimierung der Kosten erfordert ein tiefes Verständnis der Cloud- und Applikationsarchitektur. Von der Voraussetzung, dass die Applikation selbst die Möglichkeiten zu skalieren bieten muss, gar nicht zu sprechen.
Häufig unterschätzt wird auch, dass sich die Cloud-Technologie rasend schnell weiterentwickelt und es somit schwierig sein kann, mit den neuesten Trends und Best Practices Schritt zu halten. Der Mangel an Cloud-Kompetenzen und -Erfahrungen kann somit eine erhebliche Herausforderung darstellen.
Um diese Herausforderungen zu bewältigen, können Unternehmen auf eine Reihe von Tools und Diensten zurückgreifen, darunter Sicherheits- und Compliance-Management-Tools, Multi-Cloud-Management-Plattformen oder auch professionelle Dienstleistungen ihrer Partner. Tools wie unter anderem Cloudcheckr oder Apptio bieten umfassende Kostenmanagement-Funktionen, die es Unternehmen ermöglichen, ihre Cloud-Ausgaben zu überwachen und zu optimieren. Für die Performance-Optimierung können Techniken wie die Lastverteilung und das Autoscaling eingesetzt werden, um die Ressourcennutzung zu optimieren und die Leistung zu maximieren. Darüber hinaus können Infrastruktur-als-Code(IaC)-Frameworks wie Terraform zur Automatisierung und Standardisierung der Cloud-Infrastruktur beitragen, was zu einer weiteren Optimierung führt. Es ist wichtig, eine Strategie für die Cloud-Optimierung zu entwickeln, die auf den spezifischen Anforderungen und Zielen eines Unternehmens basiert.
Cloud-Optimierung und Nachhaltigkeit gehen Hand in Hand und können Unternehmen dabei helfen, ihre ökologischen Ziele zu erreichen, während sie gleichzeitig ihre Effizienz und Leistung verbessern.
So erreicht man eine hohe Energieeffizienz beispielsweise dadurch, dass man möglichst wenig physische Server benötigt und einsetzt, was den Energieverbrauch in den eigenen Rechenzentren erheblich reduziert. Eine Ressourcenoptimierung ermöglicht es Unternehmen, ihre Ressourcen effizienter zu nutzen, indem nur die benötigte Rechenleistung bereitgestellt wird. Dies führt zu einer Reduzierung von Abfällen, da weniger Hardware benötigt wird und somit der Elektronikschrott reduziert wird.
Die Skalierbarkeit und Flexibilität der Cloud tragen dazu bei, unnötigen Ressourcenverbrauch zu vermeiden. Unternehmen können ihre Kapazität je nach Bedarf erhöhen oder verringern, was zu einer effizienteren Nutzung der Ressourcen führt.
Es gibt auch eine Reihe von grünen Cloud-Initiativen, einschließlich der Nutzung erneuerbarer Energien durch die Cloud-Anbieter selbst. Diese Initiativen tragen dazu bei, den CO2-Fußabdruck der IT-Industrie zu reduzieren. Ein Beispiel hierfür ist die Microsoft Azure Cloud. Eine Studie aus dem Jahr 2018 ergab, dass die Azure-Cloud-Plattform von Microsoft um 93 Prozent energieeffizienter und um 98 Prozent CO2-effizienter als lokale Lösungen genutzt werden kann. Darüber hinaus hat sich Microsoft verpflichtet, bis 2025 100 Prozent erneuerbare Energien zu nutzen sowie im Bereich des Wassermanagements bis 2030 einen positiven Wasserfußabdruck zu erreichen, das heißt, mehr Trinkwasser aufzubereiten als zu verbrauchen. Und auch im Bereich des Abfallmanagements hat sich Microsoft Ziele gesetzt. Man möchte bis 2030 eine Zero-Waste-Zertifizierung erreichen.
Alle Cloud-Anbieter erforschen auch immer wieder effizientere Server-Kühlungsmethoden, um die Umweltauswirkungen physischer Rechenzentren weiterhin minimieren zu können, indem sie den Energieverbrauch senken und gleichzeitig eine höhere Rechenleistung ermöglichen.
In Bezug auf nachhaltige Innovationen gibt es viele spannende Entwicklungen im Bereich Cloud Computing, etwa energieeffiziente Algorithmen oder KI-gesteuerte Optimierung, die zur Förderung der Nachhaltigkeit beitragen. Ein Beispiel ist die Zusammenarbeit von Coca-Cola und AWS. Coca-Cola und AWS Professional Services implementieren AWS IoT, um neue Cleaning-in-Place-Lösungen zu entwickeln, die den Energie- und Wasserverbrauch reduzieren.
Unternehmen müssen auch regulatorische Anforderungen und Standards erfüllen, um ihre Cloud-Dienste nachhaltig zu gestalten. Dazu gehören Vorschriften zur Datensicherheit und zum Datenschutz sowie Standards für Energieeffizienz und Abfallreduzierung.
Es gibt viele Fallstudien von Unternehmen, die Cloud-Technologien erfolgreich genutzt haben, um ihre Nachhaltigkeitsziele zu erreichen. Diese Beispiele zeigen, dass die Cloud nicht nur eine kosteneffiziente, sondern auch eine umweltfreundliche Lösung sein kann.
Die Cloud-Technologie entwickelt sich ständig weiter und bringt neue Trends und Innovationen hervor, die die Effizienz und Nachhaltigkeit verbessern. Einige der aktuellen Trends in der Cloud-Effizienz umfassen folgende Bereiche:
In der Welt der Cloud-Technologie ist die Effizienz das Herzstück der Optimierung. Die Herausforderungen in den Bereichen Kostenkontrolle, Performance-Optimierung, Sicherheit, Compliance und Multi-Cloud-Management können durch den Einsatz von spezialisierten Tools und Techniken bewältigt werden. Darüber hinaus spielt die nachhaltige und energieeffiziente Nutzung der Cloud eine immer wichtigere Rolle.
Unternehmen erkennen zunehmend, dass eine effiziente Nutzung der Cloud-Ressourcen nicht nur Kosten spart, sondern auch einen positiven Einfluss auf die Umwelt hat. Gern unterstützen wir Sie bei Vorhaben dieser Art. Nehmen Sie dazu einfach Kontakt zu Ihrem Ansprechpartner beziehungsweise zu Ihrer Ansprechpartnerin bei Computacenter auf.

Thomas Munser
Die Übernahme von VMware durch Broadcom im vergangenen November zog Änderungen im Produktportfolio und Lizenzierungsmodell nach sich. Dadurch kann für Unternehmen und öffentliche Organisationen eine neue IT-Strategie sinnvoll oder gar nötig sein. Eine strukturierte Vorgehensweise hilft dabei, die bestmögliche Entscheidung zu treffen.
Mit dem Übergang vom traditionellen Lizenzmodell mit unbefristeten Lizenzen (Perpetual Licenses) zu einem Abonnementmodell mit Core-basierter Lizenzierung wurden neue Wege beschritten. Diese Veränderungen haben Auswirkungen auf die Art und Weise, wie Kund:innen ihre VMware-Produkte nutzen und verwalten können.
Darüber hinaus wurde das Produktportfolio von VMware einer umfassenden Anpassung unterzogen. Einige Produkte, darunter VMware Horizon für virtuelle Desktop-Infrastrukturen, wurden komplett ausgelagert und das Geschäft an Investoren verkauft. Dieser Schritt hat bei VMware-Kund:innen zu Unsicherheiten geführt, da sie sich nun mit neuen Herausforderungen und möglichen Änderungen in ihrer IT-Infrastruktur auseinandersetzen müssen.
Es ist entscheidend, dass VMware-Kund:innen sich über die aktuellen Entwicklungen informieren und gegebenenfalls ihre Strategien anpassen, um ihren IT-Betrieb weiterhin effizient und erfolgreich aufrechtzuerhalten. Die Zusammenarbeit mit erfahrenen IT-Berater:innen und Dienstleister:innen kann dabei helfen, die richtigen Entscheidungen zu treffen und eine reibungslose Transition zu gewährleisten. Insgesamt ist es wichtig, dass Kund:innen von VMware die Veränderungen als Chance begreifen, um ihr Unternehmen zukunftssicher aufzustellen und innovative Technologien optimal zu nutzen.
Vor dem Hintergrund dieser Veränderungen sind eine Betrachtung der installierten Basis (Produkte, Laufzeiten des Supports für unbefristete Lizenzen und so weiter) und die Einordnung dieser in das neue Produktportfolio (welche unbefristete Lizenz kann durch welche Subskription abgelöst werden) notwendig. Aber auch der Abgleich mit der unternehmenseigenen IT-Strategie (wie passt das neue Portfolio auf die IT-Strategie des Unternehmens) und die mögliche Betrachtung von Alternativen (andere Hersteller als Ablöse für Teile der VMware-Produkte) sind zu empfehlen.
Betrachtet man das „alte“ VMware-Portfolio (Stand Oktober 2023), ist aber festzustellen, dass VMware in den letzten Jahren ein komplexes Software-Portfolio mit Lösungen für die verschiedensten Bereiche aufgebaut hat:
Die Frage nach VMware-Alternativen ist also gar nicht mit einem Produkt oder einer Lösung zu beantworten. Vielmehr gilt es wie bereits erwähnt genau zu analysieren, welche Produkte beziehungsweise Lösungen betrachtet werden sollen.
Die drei großen Bereiche, die sich heute bei einer Vielzahl von Unternehmen und Behörden im Einsatz befinden, sind:
Betrachtet man nun mögliche Alternativen, so ist festzustellen, dass egal, welche der drei oben genannten Lösungen zum Einsatz kommen, die Abhängigkeiten zu anderen Produkten, Lösungen und Betriebsabläufen und nicht zuletzt auch im Hinblick auf das Wissen der Menschen im Betrieb enorm sind. Es empfiehlt sich eine strukturierte Vorgehensweise entlang eines Fragenkatalogs.
Zunächst sollten ganz allgemeine Fragestellungen und mögliche Risiken betrachtet werden:
Mit einem Wechsel einer bestehenden Plattform ist zudem eine Migration der Workloads notwendig. Auch in diesem Kontext sind einige Punkte zu hinterfragen:
Technologische Fragestellungen schließen sich an und müssen gegebenenfalls mit weiteren Fachabteilungen oder Dienstleister:innen abgestimmt werden – je nach Betriebsmodell:
Nach der allgemeinen und technologischen Betrachtung ist auch die Fragestellung der Wirtschaftlichkeit nicht außer Acht zu lassen. Hier stellen sich ebenfalls einige Fragen, die mit in die Gesamtbetrachtung einfließen:
Unabhängig von der Betrachtung möglicher Alternativen für einen Hypervisor, einer HCI-Lösung oder einer Hybrid-Cloud-Lösung muss man sich vor Augen halten, dass Technologien sich stetig weiterentwickeln. So hat sich die Server-Virtualisierung ab Anfang der 2000er Jahre bis heute zunehmend als Standard für den Betrieb von Applikationen entwickelt. Die direkte Abhängigkeit von einer Applikation zu einem Server wurde dabei aufgebrochen. Die Container-Technologie entwickelt sich nun seit Ende der 2010er Jahre zunehmend und könnte der neue Standard für den Betrieb von Applikationen werden. Hierbei wird nun die direkte Abhängigkeit von einer Applikation zu einem Server und einem Betriebssystem aufgebrochen.
Insgesamt gibt es eine Vielzahl von alternativen Produkten und Technologien zu den verschiedenen VMware-Produkten, die je nach den individuellen Anforderungen und Budgets in Betracht gezogen werden können. Bevor jedoch ein Wechsel von VMware und seinen Technologien in Erwägung gezogen wird, ist es wichtig, die potenziellen Auswirkungen und Herausforderungen sorgfältig zu prüfen. Ein solcher Schritt erfordert eine gründliche Planung, um sicherzustellen, dass die neue Lösung den Bedürfnissen des Unternehmens entspricht und ein reibungsloser Übergang möglich ist. Letztendlich sollte die Entscheidung für oder gegen einen Wechsel gut durchdacht sein, um langfristige Erfolge zu gewährleisten.
Ein Innovationsprojekt – aufgesetzt als Proof-of-Concept(PoC)-Projekt – kann bei der Entscheidungsfindung gut unterstützen, denn egal, wie die Ergebnisse ausfallen, gelangt man so immer zu einem hilfreichen Resultat. Entweder führt der PoC zu einem positiven Ergebnis, was eine mögliche neue Lösung angeht, oder zu der wertvollen Erkenntnis, dass die getestete Lösung nicht zum eigenen Unternehmen passt.
Computacenter verfügt über umfassende Kenntnisse und Erfahrungen im Bereich der Virtualisierungstechnologien und kann Unternehmen und Behörden daher bei einem Wechsel zu neuen Lösungen effektiv unterstützen. Mit einem starken Team von Expert:innen und einer bewährten Methodik bietet Computacenter maßgeschneiderte Beratung, Implementierung und Support-Services, um sicherzustellen, dass der Technologiewechsel reibungslos und erfolgreich verläuft. Kund:innen können sich darauf verlassen, dass Computacenter sie auf ihrem Weg begleitet und sie dabei unterstützt, ihre Ziele zu erreichen und ihr volles Potenzial auszuschöpfen. Wir freuen uns auf Ihre Kontaktaufnahme!

Norbert Steiner
Die Einführung eines Open Source Program Office (OSPO) in Unternehmen und Behörden hat eine hohe Relevanz und ist notwendig. Aber welcher konkrete Nutzen kann eigentlich aus einem OSPO bezogen werden und rechtfertigt er die damit verbundenen Kosten?
Ein normaler Arbeitstag in der IT-Administration: Eine Aufgabe wird automatisiert und dazu wird ein Playbook geschrieben beziehungsweise eine Automation erstellt. Dazu wird eine auf Open Source basierte Lösung wie Ansible oder Terraform verwendet. Jetzt muss bei der Erstellung des Playbooks ein Softwarepaket (bezeichnet als Artefakt, hier zum Beispiel PyPi) bezogen werden und der interne oder externe Administrator oder Berater findet es auf PyPI – Der Python Package Index. Aber dürfen diese Artefakte von dem im Internet erreichbaren Repository (oder einfacher ausgedrückt: Server) bezogen werden?
Eine andere Abteilung entwickelt Software beziehungsweise eine App für das Smartphone, die dann millionenfach verteilt wird. In dem Rahmen sind Software-Artefakte von Maven notwendig und auch hier findet sich im Internet ein Repository wie das Maven Repository. Auch hier stellt sich die Frage – darf ich diese Artefakte aus dem Internet herunterladen, in die App einbauen und dann millionenfach verteilen?
Die Antwort auf die Frage „Dürfen wir?“ kann nicht lauten: Die Administratoren und Entwickler:innen wissen, was sie machen, und können das selbst einschätzen. Das hat eine ähnliche Qualität wie „Die sollen das Auto selbst bauen – Sicherheitstests sind aufwendig und die Ingenieure haben das schon im Griff.“
Wen also können diese Menschen im Unternehmen oder in der Behörde fragen, um eine verbindliche Antwort zu bekommen? Das OSPO.
Das Open Source Program Office oder Kompetenzzentrum ist die zentrale Anlaufstelle im Unternehmen und in der Behörde, wo Themen rund um Open Source zusammengefasst und entschieden werden. Da diese Entscheidungen weitreichend sind und auch Aspekte des Risikomanagements sowie strategischer Ziele umfassen, muss das OSPO als Stabsstelle und mit einem Auftrag der Unternehmens- oder Behördenführung ausgestattet und dauerhaft finanziert sein.
Das bedeutet jedoch eine signifikante und dauerhafte Investition in ein OSPO-Team und das nur, um die Frage „Dürfen wir?“ zu beantworten. Das ließe sich sicherlich auch mit einer einfachen Richtlinie bewerkstelligen, die einmal jährlich aktualisiert wird.
Auch wenn die Frage „Dürfen wir?“ einfach klingt, sind bei der Beantwortung eine Reihe von Aspekten einzubeziehen. Hier sind vier typische Fragen skizziert, die betrachtet werden sollten:
Dieser Fokus blendet aber Aspekte im Kontext Open Source aus, die strategisch zugunsten des Unternehmens oder der Behörde genutzt werden können.
Das lässt sich an zwei Beispielen skizzieren:
Hierzu gibt es bereits eine Reihe von erfolgreichen Projekten, in denen Open-Source-Bestandteile verwendet werden, um konkreten Nutzen für die Unternehmensstrategie und Erfolg zu etablieren. Diese sind häufig branchenspezifisch etabliert und existieren im Bereich Finance (FinOps), Automotive (Software Defined Vehicle als Beispiel), Telcos und Edge und finden sich unter der Schirmherrschaft der Linux Foundation oder Eclipse Foundation.
Tatsächlich sind viele Modelle (Inner Loop / Outer Loop, Community-of-Practice, Contributor/Maintainer Ladder, andere) verfügbar, um zu lernen, wie moderne und effektive Softwareentwicklung und Automatisierungen etabliert und genutzt werden können. Jeder dieser Aspekte ist einen eigenen Artikel oder Workshop wert.
Zusammengefasst ist festzuhalten: Das OSPO ist eine wertvolle und notwendige Stabsstelle im Unternehmen und in den Behörden. Es darf aber nicht als Kostenfaktor betrachtet werden, der zum Thema Risikomanagement und Richtlinien Dokumente erstellt. Vielmehr ist das OSPO ein Bestandteil der Innovation und unterstützt das Unternehmen und Behörden, die Vorteile von Open Source – also Technologien, Arbeitsweisen und übergreifende Standards und Kooperationen – zu nutzen, um wertschöpfend zu den Zielen des Unternehmens oder zum Auftrag der Behörden beizutragen.
Haben Sie noch Fragen zu diesem Thema? Ihr Ansprechpartner beziehungsweise Ihre Ansprechpartnerin bei Computacenter hilft Ihnen gern weiter.

Norbert Steiner
Seit vielen Jahren stehen agile Metriken als notwendige Grundlage einer Messbarkeit in der Diskussion. Einerseits werden Metriken als Kontrolle empfunden – als Indikator der Team-Performance und Möglichkeit zum Vergleich. Andererseits suchen Teams Orientierung, auf welches Ziel sie hinarbeiten sollen und wie sie den Fortschritt nachvollziehen können.
Im Jahr 1994 veröffentlichte die Standish Group den Chaos Report. Dieser initiierte eine Diskussion, wie Softwareprojekte erfolgreicher abgeschlossen werden können – denn die Daten besagten, dass weniger als 17 Prozent der Softwareentwicklungsprojekte im Zeitplan und im Budget abgeschlossen wurden. Das führte, naheliegenderweise, zu der Frage, wie Softwareentwicklung besser gesteuert werden könne.
Daraus ergaben sich zwei Strömungen, die sich grob wie folgt skizzieren lassen:
Diese zwei sehr konträren Sichtweisen finden sich auch heute in den Diskussionen um agile Metriken wieder. Die Teams in der Softwareentwicklung sollen messbare Ergebnisse liefern. Aber dient die Messbarkeit nur der Kontrolle oder unterstützt sie das Team dabei, den richtigen Weg zu beschreiten, um eine hohe Qualität, Kundenzufriedenheit und Produktivität zu erreichen?
Im Rahmen der DevSecOps-Methodik und -Forschung hat sich ein breites Spektrum an Metriken etabliert. Ein kleiner Auszug für agile Metriken:
Es existieren sehr viele Konzepte und Ideen zur Messbarkeit – wichtig ist jedoch, zunächst festzulegen, ob diese der Kontrolle oder der Anleitung dienen sollen.
Das Ziel muss sein, den Teams einen Leitstern zu geben – die Richtung aufzuzeigen und dem Team in seiner Verantwortung den Freiraum zu geben, den passenden Weg zu finden und über Feedback und Fehler zu lernen.
Damit ist eine Auswahl an Metriken erforderlich, welche das Zielbild Leitstern unterstützen und nicht das Gefühl vermitteln, einer Erfolgskontrolle zu unterliegen, die zudem dem Vergleich zwischen Teams dient.
Der Wert einer Software bestimmt sich aus der Sicht der Anwenderinnen und Anwender. Sie und ihre Zufriedenheit sind unser Leitstern. Wie aber kann Zufriedenheit von Benutzer:innen gemessen werden?
Um das zu verdeutlichen, nehmen wir als Beispiel ein Game. Die Nutzer:innen wollen sich auf das Game konzentrieren, sich darüber freuen und mit Bekannten und anderen Gamer:innen darüber reden können. Der Leitstern ist in diesem Vergleich also ein:e glückliche:r Gamer:in.
Was aber versauert jeder/jedem Gamer:in den Tag?
Hieraus ergeben sich bereits vier Aspekte, auf die sich das Team konzentrieren kann, um den Leitstern „glückliche Gamer:innen“ zu erreichen und sich selbst als Team daran zu orientieren.
Die vier Aspekte sind Resilienz, Adoption, Velocity und Error Rate (RAVE). Die jeweiligen Teams können die RAVE-Aspekte als Kriterien für zufriedene Kund:innen anlegen. Dazu werden aus den diversen Frameworks die richtigen Metriken für den jeweiligen Leitstern ausgewählt und verwendet, um dem Ziel beziehungsweise dem Leitstern fortlaufend näher zu kommen. Daraus ergibt sich eine Ausrichtung der Teams auf den Leitstern und nicht auf extern vorgegebene und eher pauschalisierte Metriken und Kriterien.
Agile Metriken und eine Erfolgsorientierung sind relevant und notwendig. Dazu sollten Teams ihren Leitstern formulieren und die Metriken und Messbarkeit auf ihn ausrichten. Die RAVE-Aspekte können dazu als Anleitung dienen. Die Teams sind heute selbstorganisiert und verantwortlich, ihren Leitstern zu erreichen. Dann ist es sinnvoll, dass Teams auch die Metriken für sich definieren und messen, um die fortlaufende Ausrichtung an den Leitstern sichtbar und transparent zu gestalten.
Wünschen Sie eine Beratung zu agilen Metriken oder konkrete Unterstützung bei deren Implementierung in Ihrer Organisation? Ihr/Ihre Ansprechpartner:in bei Computacenter hilft Ihnen gern weiter.

Dirk Hannemann
Es ist relativ einfach, Workloads von virtuellen Maschinen (VMs) auf Container- oder KubeVirt-Plattformen umzuziehen und dort laufen zu lassen. Selten wird jedoch daran gedacht, eine Backup- und Restore-Architektur auf der neuen Plattform einzurichten und Abhängigkeiten zu anderen Services zu berücksichtigen. Das kann verheerende Folgen für das gesamte Eco-System und das Unternehmensgeschäft nach sich ziehen.
Die Verbreitung der Container-Technologie nimmt mit erstaunlicher Geschwindigkeit zu. Der globale Markt für Anwendungs-Container wurde im Jahr 2018 auf 1,5 Milliarden US-Dollar geschätzt und wird laut einem neuen Bericht von Grand View Research und anderen Analyseunternehmen bis 2025 voraussichtlich 8,2 Milliarden US-Dollar erreichen, mit einer durchschnittlichen jährlichen Wachstumsrate von 26,5 Prozent während des Prognosezeitraumes.
Dieses Wachstum ist darauf zurückzuführen, dass sich containerisierte Anwendungen leicht portieren und in unterschiedlichen Umgebungen einsetzen lassen – schließlich verpacken Container die Anwendungen mit praktisch allem, was sie zur Ausführung benötigen (Konfigurationsdateien, Abhängigkeiten und so weiter) und isolieren sie für die Bereitstellungsumgebung. Dadurch können containerisierte Anwendungen problemlos in verschiedenen Umgebungen wie lokalen Desktops, virtuellen und physischen Servern, Entwicklungs-, Test- und Produktionsumgebungen sowie privaten oder öffentlichen Clouds ausgeführt werden. Container können sogar mehrere Umgebungen sowohl vor Ort als auch in der Cloud oder in Multi-Cloud-Umgebungen umfassen.
Sich grundsätzlich mit einem Wechsel in der Infrastrukturlandschaft zu beschäftigen, ergibt durchaus Sinn. Dabei können Anpassungen vorgenommen werden, die das Eco-System flexibler gestalten und die Auslastung entsprechend der Workloads optimieren. So können Ressourcen auf den traditionellen Infrastrukturen besser genutzt und mit neuen Technologien verknüpft werden. Eine hybride Gesamtlösung wird somit nicht nur zwischen On-Premises- und Cloud-Plattformen Realität, sondern auch im reinen On-Premises-Umfeld, indem hier unterschiedliche Infrastrukturtechnologien zum Einsatz kommen.
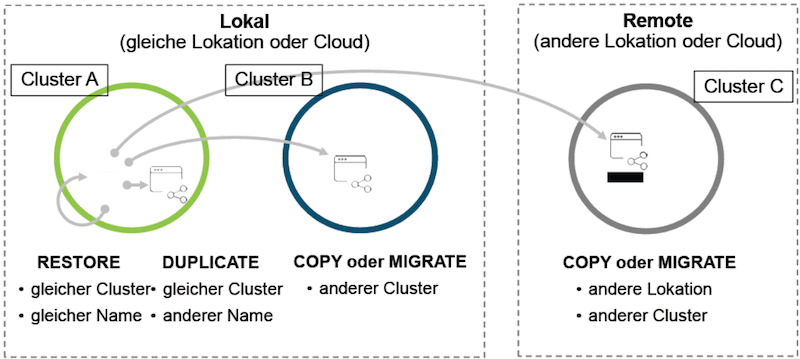
Hat man sich nun entschieden, VMs in Containern neu zu designen, zu migrieren, zu transformieren, zu refaktorisieren oder gar auf der grünen Wiese zu starten, stellen sich unweigerlich einige Fragen:
Um diese Fragen zu beantworten, werfen wir am besten einen detaillierteren Blick in die Möglichkeiten zur Sicherung von Container-Plattformen, speziell Kubernetes.
Es gibt mindestens vier gute Gründe, warum eine Datensicherung für Container-Umgebungen wie Kubernetes, OpenShift oder Docker und die damit verbundenen Anwendungen erforderlich ist:
Wichtige Schlüsselanforderungen, die für den Schutz containerisierter Anwendungen zu beachten sind:
Nähert man sich nun praktisch der Sicherung von Containern oder VMs in Containern, ist es wichtig zu verstehen, dass Container anders behandelt werden und für die Sicherung andere Mechanismen und oft auch andere Tools zum Einsatz kommen als bei virtuellen Servern.
Es gilt:
Container sind von Natur aus nicht mit physischen Servern oder virtuellen Maschinen verbunden. Eine der größten Herausforderungen beim Schutz von Containern ist die Verwaltung dieser dynamischen Bereitstellung. Das Ziel des Container-Schutzes ist die schnelle Wiederherstellung der vollen Betriebsfähigkeit (operationale Resilienz) von Anwendungen und nicht die Sicherung ihrer Daten oder Konfigurationen.
Schaut man sich, wie unten dargestellt, die High-Level-Komponenten einer Container-Infrastruktur an, erkennt man schnell, dass hier weniger „Standards“ und auch weniger bekannte Player vorherrschen als in klassischen Hypervisor-Landschaften. Viele der Applikationen kommen aus dem Cloud-Native-Umfeld und auch die Container-Plattformen an sich haben (noch) keinen marktbeherrschenden Hersteller hervorgebracht, da prinzipiell das meiste auf Open-Source-Technologie aufsetzt.
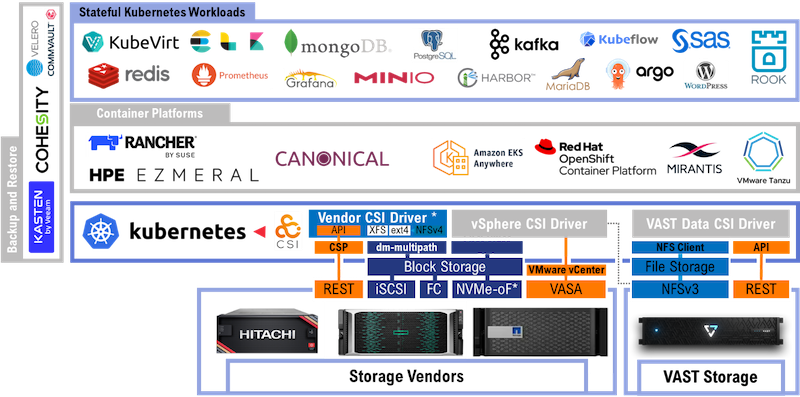
Speziell Anforderung Nummer 3 stellt die meisten Tools vor Herausforderungen. Unter Umständen sind die Umsetzung und das Management deutlich aufwendiger. Was bei den klassischen Hypervisoren schon Standard ist, muss sich im KubeVirt-Kontext erst noch entwickeln. Schaut man sich die aktuellen Dokumentationen hierzu an (s. beispielsweise die Links am Ende dieses Artikels), wird in der Regel darauf verwiesen, dass VMs in Containern nicht in Backup Mode versetzt werden. Jedoch sind viele Applikationen in der Lage, einen Storage Snapshot, den man per CSI hinzuziehen kann, für eine ausreichende Zeit konsistent und ohne negative Auswirkungen zu überdauern.
In den Dokumentationen ist im Vergleich zu klassischen Hypervisor-Infrastrukturen weniger von SAN Storage als vielmehr von SDS (Software Defined Storage) im Primär-Storage als auch im Object Storage im Sekundärbereich (wie zum Beispiel Backup Repositories) die Rede. Diese Entwicklung im Kontext Backup ist umso interessanter, da auch die klassischen Backup-Software-Hersteller vermehrt auf den Einsatz von Object Storage im Backup aufmerksam machen und in diese Richtung drängen (hier besonders Veeam mit Kasten).
Natürlich sind Open-Source-Lösungen wie beispielsweise velero durchaus am Markt vertreten, sie passen aber selten zu den Enterprise-Anforderungen. Das gilt vor allem dann, wenn es um zentrales Management und Reporting geht – im Kontext NIS2 oder NIST2 eine nicht zu missachtende und unterschätzende Disziplin.
Was jedoch immer geht, ist eine agentenbasierte Sicherung innerhalb der VM im Container, wie man es schon immer auf physischen Maschinen praktiziert hat. Aber das wäre buchstäblich ein Zurück zu den Anfängen – und wer will das heutzutage noch?
Einige Hersteller haben sich dieser Problematik sowohl von Backup-Software-Seite als auch von Storage-Integrations-Seite angenommen. Hier einige Beispiele:
Am Beispiel HPE sieht man, dass hier CSI-Treiber verwendet werden, damit eine Backup-Schnittstelle auf Storage-Ebene Snapshots sowohl der Container als auch der KubeVirt-VMs erstellen kann. Die Andockstelle für eine Backup-Integration muss aber vom Operator gebaut oder zur Verfügung gestellt werden, um die Funktionen nutzen zu können.
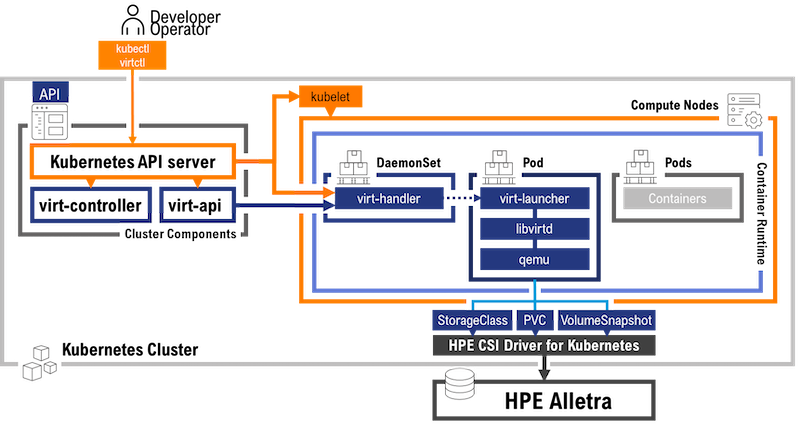
Veeam Kasten nutzt die oben beschriebenen Möglichkeiten eines CSI-Treiber-Storage-Snapshots für eine Sicherung sowohl der Standard-Container als auch der KubeVirt-VMs.
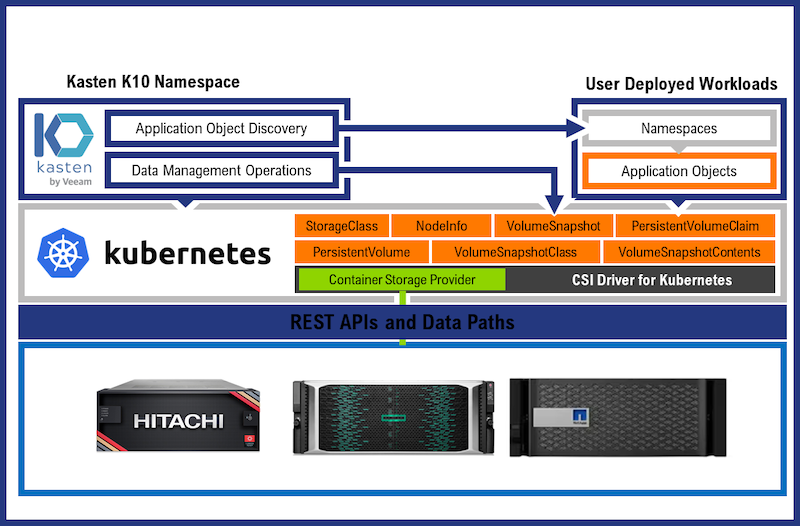
Commvault als Backup-Software-Anbieter nimmt sich der Sicherung von Containern folgendermaßen an: Media Agents bewegen die Container-Daten zu den unterstützten Backup Devices und Access Nodes stellen die Verbindung zu den Container Clustern her.

Anders als bei der Hypervisor-Welt, in der es einen klaren Marktführer gibt, sind Container-Plattformen noch sehr heterogen aufgestellt, wenn es um eine generelle Sicherung geht – und noch spezieller, wenn man sich Stateful Container und VMs im Container mit Applikationen wie zum Beispiel MS SQL oder gar SAP/HANA anschaut. Beim letzteren Beispiel stellt sich aber allgemein die Frage, ob dies überhaupt supported wird und wenn ja, für welche Größe und welchen Workload. Das muss die Zukunft zeigen.
Aber auch ein Wechsel zu einem anderen Hypervisor als VMware muss im Rahmen von Backup/Restore-Funktionalitäten genauer betrachtet werden:
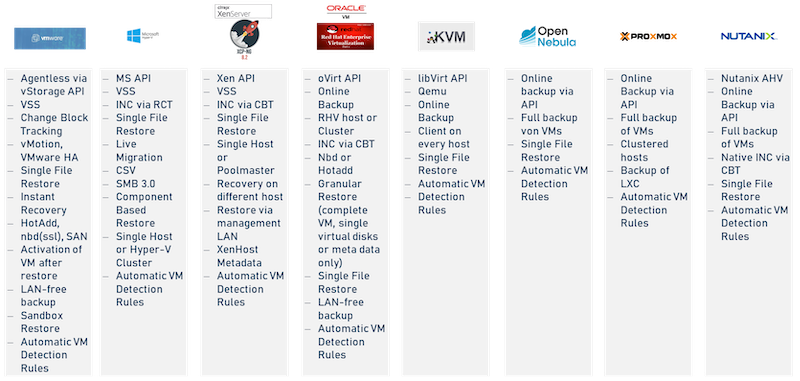
Aktuell arbeiten aber sowohl Hypervisor- als auch Backup-Software-Hersteller mit Hochdruck daran, für den Bereich Backup/Restore paritätische Verhältnisse zum Markführer zu schaffen, um einen etwaigen Wechsel nicht am Backup scheitern zu lassen, was unseres Erachtens eine extrem wichtige Rolle spielt – vor allem im Zusammenhang mit NIS2, DORA und so weiter.
Gern beraten wir Sie ausführlich zu den Möglichkeiten der Container-Sicherung. Wenden Sie sich dazu einfach an Ihre/Ihren Ansprechpartner:in bei Computacenter.