Künstliche Intelligenz für alle

Künstliche Intelligenz für alle wollen NVIDIA und VMware gemeinsam verwirklichen. Lesen Sie in dieser aktuellen Ausgabe unseres Datacenter-Newsletters, wie die beiden Unternehmen dazu die passenden Komponenten perfekt aufeinander abgestimmt haben.
Das Cloud Center of Excellence unterstützt Sie bei der Organisation Ihrer Public-Cloud-Infrastruktur und -Services und übernimmt zudem Support- und Betriebsaufgaben wie Monitoring, Incident Management, Automatisierung der Bereitstellung sowie das Request Management. Wir zeigen Ihnen, wie das funktioniert.
In unserem Artikel State-of-the-Art-Management moderner IT-Infrastrukturen lesen Sie, wie ein modernes Systemmanagement dazu beiträgt, Geschäftsrisiken zu reduzieren und datengesteuerte Innovationen und Agilität zu fördern. Zudem stellen wir Ihnen mit HPE Greenlake eine konkrete Lösung im Detail vor.
Cisco Intersight ist eine skalierbare und konsistente Managementumgebung für Rechenzentren inklusive Multi-Cloud-Umgebungen und Anwendungsarchitekturen. Was die Lösung leistet und wie genau sie auch Ihr Unternehmen unterstützen kann, erfahren Sie ebenfalls in dieser Ausgabe.
Die Datensicherung ist ein wichtiger Baustein im Schutz gegen Cyberattacken. Doch immer häufiger wird sie selbst Ziel von Angriffen. Worauf Sie achten sollten, erfahren Sie in unserer aktuellen Backup-Kolumne.
Agile Methoden haben viele Vorteile. Doch es ist eine Kunst, beispielsweise innerhalb eines Scrum-Teams die Balance zwischen technischer Kreativität und Freiheit gegenüber der Sicherheit und Verantwortung für das Ergebnis zu wahren. Unsere Agile-IT-Kolumne zeigt auf, wo Fallstricke – und große Potenziale! – lauern.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter wurde als „EMEAR Partner of the Year“ und „Enterprise Partner of the Year“ beim Cisco Partner Summit Global prämiert. Cisco zeichnet damit die leistungsstärksten Partner in bestimmten Technologiemärkten in allen geografischen Regionen aus.
Weitere InfosComputacenter hat den Status „Amazon Web Services (AWS) Migration Competency“ erreicht. Damit wird die Erfahrung und Expertise des IT-Dienstleisters honoriert, Kunden erfolgreich bei der Migration zu AWS unterstützt zu haben.
Weitere Infos
NVIDIA und VMware haben sich vorgenommen, künstliche Intelligenz in jedes Unternehmen zu bringen. Dafür kombinieren beide Unternehmen ihre Leistungsfähigkeit im Bereich KI in der virtuellen Hybrid Cloud. NVIDIA hat mit AI Enterprise eine umfassende Software-Suite entwickelt, die KI auf VMware vSphere ermöglicht und nahezu Bare-Metal-Leistung für virtualisierte Umgebungen bietet.
Mit AI Enterprise hat NVIDIA eine Software-Suite mit KI-Tools und -Frameworks entwickelt. Sie lässt sich mit VMware vSphere einsetzen und ermöglicht es, KI-Berechnungen auf NVIDIA-zertifizierten Systemen zu virtualisieren. Dabei kommt im Prinzip die gleiche Technologie zum Einsatz wie bei VDI-Infrastrukturen. Diese vGPU-Technologie wird seit vielen Jahren weltweit erfolgreich verwendet, um virtuelle Desktops mit Grafikleistung auszustatten. Dies ist in Zeiten von Windows 10/11 unerlässlich und für alle VDI-Projekte zu empfehlen.
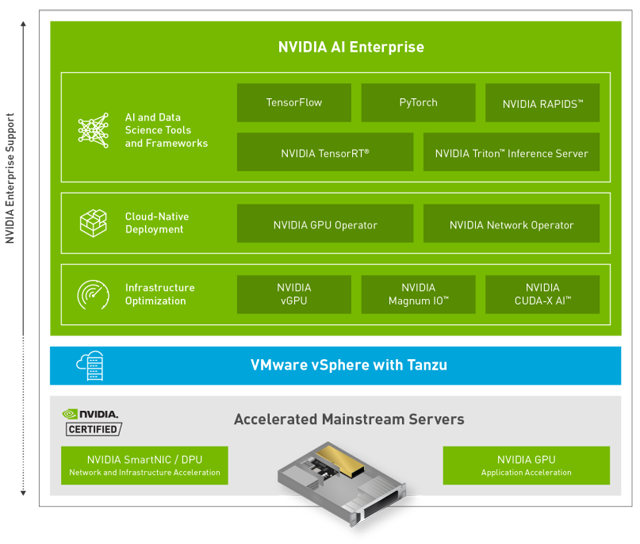
Mit AI Enterprise ermöglicht es NVIDIA IT-Experten, die VMware vSphere für die Ausführung herkömmlicher Unternehmensanwendungen nutzen, KI-Workloads einfach und kosteneffizient zu unterstützen und dabei dieselben Tools zu verwenden, die sie auch für die Verwaltung großer Rechenzentren und hybrider Clouds verwenden. Man kann also „klein“ beginnen und mit den Business-Anforderungen mitwachsen. Alle bestehenden Software-Defined-Lösungen von VMware wie vSAN und NSX-T können natürlich weiterhin verwendet werden und lassen sich perfekt kombinieren.
Die für AI Enterprise zertifizierten Systeme von nahezu allen großen Serverherstellern verfügen über eine breite Palette von NVIDIA-GPUs, darunter A100, A30, A40, A10 und T4. Somit ist es möglich, für jeden Workload-Typ die passende GPU auszuwählen. Viele Kunden starten mit der Single-Slot-„Allround“-Karte T4. Diese ermöglicht es, dass auch sogenannte Pizza-Boxen (1HE-Server) für KI-Umgebungen genutzt werden können. Wenn der Bedarf steigt, können weitere T4-GPUs in den Server eingebaut oder die Anzahl der Cluster Member erweitert werden.
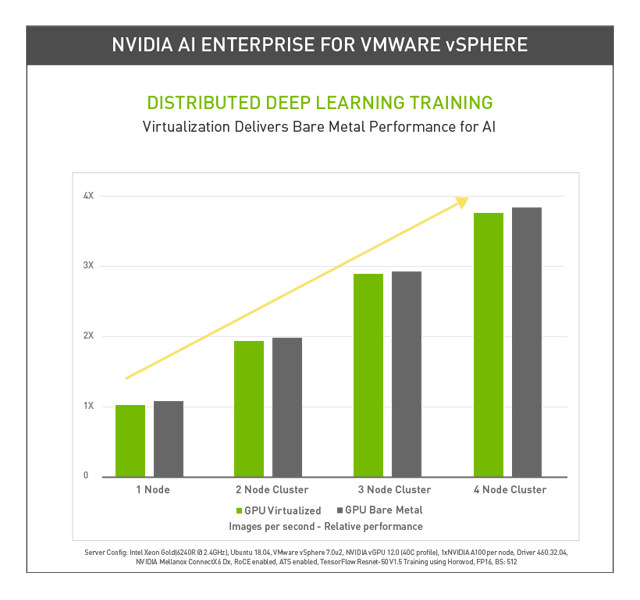
NVIDIA Enterprise AI Suite macht schnell und kostengünstig jede Kundenumgebung zum KI-aktivierten Rechenzentrum. Haben wir Ihr Interesse geweckt? Kommen Sie gern auf uns zu und wir besprechen die Möglichkeiten und die optimalen Systeme, maßgeschneidert auf Ihre Bedürfnisse.

Der Betrieb einer Public Cloud geht mit zahlreichen Verantwortungen und Aufgaben aufseiten des Kunden einher. Dazu ist eine Menge an Know-how nötig. Computacenter unterstützt Sie gern – ganz individuell nach Ihrem Bedarf.
Gemäß dem „Modell der geteilten Verantwortung“ ist ein Public Cloud Provider für die Bereitstellung von IaaS, PaaS oder SaaS verantwortlich. Der Kunde wiederum trägt die Verantwortung für die weiteren Bausteine einer Applikationsarchitektur und dafür, wie Public Cloud Services verwendet werden.
Deshalb fallen für den Kunden eine Reihe von Aufgaben an. Für die Architektur, das Design eines virtuellen Rechenzentrums sowie den Betrieb der in die Verantwortung der Kunden fallenden Module müssen die Verantwortungen und Aufgaben definiert werden.
Die Einführung eines „Cloud Center of Excellence“ (CCoE) hat sich in den letzten Jahren als effektivste Form der Organisation etabliert, diese Aufgaben zu erfüllen. Das CCoE übernimmt auch Support- und Betriebsaufgaben wie Monitoring, Incident Management, Automatisierung der Bereitstellung sowie das Request Management (Erstellen/Ändern/Beenden von virtuellen Rechenzentren/Applikationsumgebungen).
Das Betriebsmodell muss sich an der Art der Bereitstellung von IT-Services in der Public Cloud orientieren. Ebenso wichtig ist es, dass sich die Aufgaben an den Services orientieren und nicht an technologischen Bausteinen (beispielsweise Server, Storage, Netzwerk). Das Team in der Gesamtheit verantwortet die Betriebsaufgaben, das tiefe Know-how über die Public Cloud Services eines Providers sollte bei allen Mitarbeitern im Team vorhanden sein. Eine Spezialisierung sollte nur für höherwertige, nicht generell verwendete Services erfolgen.
Computacenter unterstützt Kunden beim Aufbau eines CCoE oder übernimmt die Aufgaben eines CCoE als Partner. Dazu haben wir ein eigenes CCoE aufgebaut und ein modulares Angebot erstellt, das unsere Kunden jederzeit ganz oder teilweise in ihr eigenes Support- und Betriebskonzept für Public Cloud integrieren können.

Es ist an der Zeit, die Verwaltung von Daten und Infrastruktur zu verändern. Unternehmen möchten das Potenzial ihrer Daten nutzen, um die digitale Transformation voranzutreiben, doch fragmentierte Tools, manuelle Prozesse und Infrastruktursilos schaffen Geschäftsrisiken und behindern datengesteuerte Innovationen und Agilität. Ein wesentlicher Teil der Lösung: ein modernes Systemmanagement.
Die klassischen Tools in großen IT-Umgebungen sind komplex. Sie erfordern häufig einen eigenen Betriebsprozess, um die Verfügbarkeit und Stabilität zu gewährleisten. In verteilten Umgebungen (die sich von den eigenen Rechenzentren über die Edge- bis hin zur Cloud-Infrastruktur erstrecken) multipliziert sich der Aufwand (und damit die Kosten) mit Anzahl der Betriebsstätten. Für diese Umgebungen braucht es neue Ansätze für einen vereinfachten Betrieb, damit Unternehmen schneller transformieren können. Aber auch kleinere Umgebungen können profitieren.
In einer aktuellen Studie von ESG geben 93 Prozent der befragten IT-Entscheidungsträger an, dass die Komplexität der Speicherung und des Datenmanagements die digitale Transformation behindere. Dieselbe Studie berichtet, dass eine bessere Datennutzung bei fast allen Unternehmen eine Top-10-Priorität ist (und für 67 Prozent eine Top-5-Priorität!).
Und obwohl die Komplexität der Datenverwaltung bereits ein Thema ist, glauben 59 Prozent der Unternehmen, dass die Komplexität in die falsche Richtung tendiert. (Quelle: HPE, ESG-Marktforschung unter IT-Entscheidungsträgern, April 2021)
Im Betrieb eines innovativen und modernen Rechenzentrums ist das Spektrum des IT-Managements heute nicht mehr auf Fehleralarmierung, Firmware- und Treiber-Updates beschränkt. In den für den Geschäftserfolg kritischen IT-Infrastrukturen stehen darüber hinaus Anwendungsüberwachung, Log-Management und -analyse sowie Leistungsüberwachung im Fokus. Die Systemverwaltung und die Automatisierung von IT-Prozessen, um das Konfigurationsmanagement und die Einhaltung von Compliance-Vorgaben effizient zu unterstützen und umzusetzen, sind nicht weniger kritisch.
Unsere Spezialisten kennen den Markt genau und haben die Produkte verschiedener Hersteller im Blick. Sie diskutieren mit Ihnen die Anforderungen und stellen passende Lösungsszenarien vor, darunter herstellerspezifische Lösungen wie beispielsweise die von Hewlett Packard Enterprise, die wir nachfolgend näher vorstellen.
Dem Server- und Storage-Hersteller Hewlett Packard Enterprise (HPE) ist das Spektrum der Anforderungen hinsichtlich des Systemmanagements bekannt und die Lösungen wurden kontinuierlich weiterentwickelt. Rückblickend und exemplarisch sind der HPE System Insight Manager (HPE SIM), proaktive Fehlermeldungen und das Integrated Lights Out Board für die Fernwartung der Server genannt.
Den HPE SIM hat inzwischen HPE OneView abgelöst. Mit HPE Infosight sind die proaktiven Fehlermeldungen über den Anwendungs-Stack hinweg machbar und durch künstliche Intelligenz unterstützt. HPE Greenlake bringt cloud-like Abrechnungsmodelle und Systemmanagement für „On-Premises-Hardware as a Service“ ins Rechenzentrum.
HPE Greenlake ist das stetig wachsende Angebot von HPE für eine Umstellung des IT-Betriebs von Investitionsausgaben (CAPEX) hin zu Betriebsaufwendungen (OPEX).
Im Zuge der Greenlake-Anforderungen wurden und werden SaaS-Angebote entwickelt, die das Systemmanagement drastisch vereinfachen. Teils schon Realität und teils noch Vision:
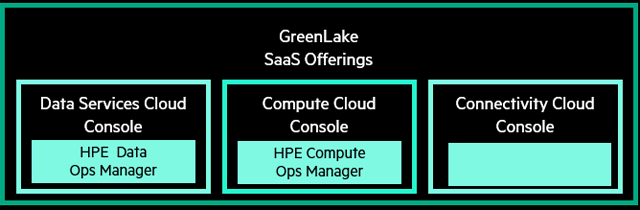
Die Data Services Cloud Console beseitigt die Komplexität, mit der Daten- und Infrastrukturmanagement heute noch behaftet sind. Es handelt sich um ein Software-as-a-Service(SaaS-)basiertes Portal, das über den HPE Data Ops Manager eine Reihe von Services bereitstellt, um das Datenmanagement mit den Speichersystemen von HPE (zum Beispiel HPE Alletra) über den gesamten Datenlebenszyklus hinweg zu vereinheitlichen und Innovationen für datengesteuerte Anwendungen und Erkenntnisse zu beschleunigen.
Die Compute Cloud Console ist der Zugang zum HPE Compute Ops Manager für einen einheitlichen Compute-Betrieb als Service. Sie bietet einen funktionalen Mehrwert für die Verwaltung Ihrer HPE-IT-Umgebung in drei Schlüsselbereichen:
Vereinfachtes Compute-Management
Mühsame Tätigkeiten wie Firmware- und Software-Updates werden durchgängig automatisiert. KI-gesteuerte und prädiktive Analysen helfen, Schwachstellen und Engpässe zu identifizieren, erhöhen die Stabilität, vermeiden Ausfälle und führen zu besseren Geschäftsergebnissen.
Cloud-Agilität im Compute-Lebenszyklus
Die Compute Cloud Console bietet Ihnen ein nahtloses „As-a-Service“-Management von Edge bis zur Cloud. Sie werden in die Lage versetzt, auf jedes Gerät von überall aus zuzugreifen, auf die Remote-Standorte ebenso wie auf die Edge-Systeme bis hin zu den Rechenzentren. Da es sich um eine Cloud-Anwendung handelt, haben Sie sofortigen Zugriff auf neue Dienste, Funktionen und Fehlerbehebungen, sobald diese verfügbar sind – ohne zusätzlichen Aufwand für Sie. Der Betrieb der eigenen on-premises Systemmanagement-Umgebung entfällt.
Beschleunigte Innovation durch Optimierungen und Automatisierung
Die Eliminierung manueller Arbeit bei der Bereitstellung von Servern, die automatisch erkannt und konfiguriert werden, führt zu besserer Effizienz und mehr Betriebszeit. Die Workload-optimierten Einstellungen sorgen für ein auf die Applikation abgestimmtes Verhältnis von Serverleistung und dem Einsatz von Energiesparoptionen.
Informieren Sie sich über den HPE Compute Ops Manager und erfahren Sie, wie diese As-a-Service-Lösung, die über HPE GreenLake bereitgestellt wird, Ihr IT-Management modernisieren kann.
HPE startet ein exklusives Programm für den HPE Compute Ops Manager, das nur auf Einladung zugänglich ist. Weitere Informationen erhalten Sie über Ihren Ansprechpartner bei Computacenter.

Der Trend geht zu immer komplexeren IT-Infrastrukturen. Doch damit wird es zunehmend schwierig, die unterschiedlichen Systeme und Komponenten zu verwalten, zu überwachen und zu steuern. Ein modernes Systemmanagement entlastet die IT-Abteilungen und spart letztlich Geld.
Die Zeit der on-premises Systemmanagement-Lösungen ist sicherlich noch nicht vorbei, doch moderne und komplexe IT-Infrastrukturen werden nicht nur in einem Rechenzentrum aufgebaut, sondern beinhalten sowohl Private-Cloud-Plattformen – beispielsweise auf Colocation-Flächen – als auch Public Cloud Services. Zudem müssen sich IT-Verantwortliche verstärkt mit Container-Technologien und Micro Services auseinandersetzen und diese aus der internen IT betreiben. All diese neuen Technologien und die zunehmend automatisierten Bestandssysteme müssen unter einen Visualisierungs- und Management-Layer gebracht werden, denn nur das, was man erfassen und messen kann, kann man auch steuern. Eine neue Art von übergreifendem Systemmanagement vereint all diese Funktionseinheiten.
Der Begriff Systemmanagement bezieht sich auf die zentrale Verwaltung der IT in einem Unternehmen. Das Konzept umfasst eine breite Palette von Teilsystemen, die für die korrekte Verwaltung von IT-Systemen erforderlich sind. Bei homogenen Umgebungen mit ähnlichen Serverarchitekturen ist das einfach. Die großen Hardwarehersteller bringen häufig ihre eigenen Elementmanager-Tools und Applikationen mit, die es den IT-Fachkräften ermöglichen, die Umgebung optimal zu verwalten.
Heterogene Systeme beziehungsweise komplexe IT-Infrastrukturen stellen solche Point-Solution-Werkzeuge vor ernsthafte Herausforderungen. Ein einzelnes Tool ist möglicherweise gar nicht imstande, denselben Umfang an Daten von den verschiedenen Modellen der Systemhardware zu sammeln, zudem werden für die Verwaltung im täglichen Betrieb zusätzliche Elementmanager anderer Hardwareanbieter benötigt. Und so hat man schnell einen Zoo an Applikationen und Tools installiert, damit man die Infrastruktur überhaupt verwalten und nutzen kann.
Die Verwaltung von IT-Systemen ist für die Organisation und den Betrieb eines Unternehmens unerlässlich. Ein gutes Systemmanagement ist das Rückgrat einer IT-basierten Organisation. Wenn es effektiv umgesetzt wird, erleichtert es die Bereitstellung von IT-Komponenten und sorgt dafür, dass sich die Mitarbeiter schneller anpassen und produktiver sind.
In den letzten Jahren hat die Einführung neuer Technologien – wie IoT, Edge Computing oder 5G – es Unternehmen ermöglicht, technologisch exponentiell zu wachsen. Aber wenn sie dies tun, werden auch ihre IT-Anforderungen steigen. Dann ist es besonders wichtig, alle Anlagen zu überwachen und zu schützen und sich an die Geschwindigkeit der Hyperkonnektivität anzupassen. Eine einzige Sekunde Ausfallzeit kann ein Unternehmen beeinträchtigen und einen hohen Verlust verursachen.
Das Systemmanagement umfasst ein breites Spektrum von IT-Funktionen oder Teilbereichen, die auf die Wartung oder Verbesserung von Infrastruktur, Netzwerk, Anwendungen, Diensten und Betriebssystemen abzielen. Das Systemmanagement überwacht viele IT-Anforderungen, wie zum Beispiel (aber nicht nur):
Wie eingangs erwähnt, bringen die großen Hardwarehersteller häufig ihre eigenen Tools mit. Aber auch hier findet ein Wandel statt. Es wird darauf geachtet, nicht nur die eigene Hardware optimal zu unterstützen, sondern es wird zunehmend partnerschaftlich eine gesamtheitliche Lösung erarbeitet.
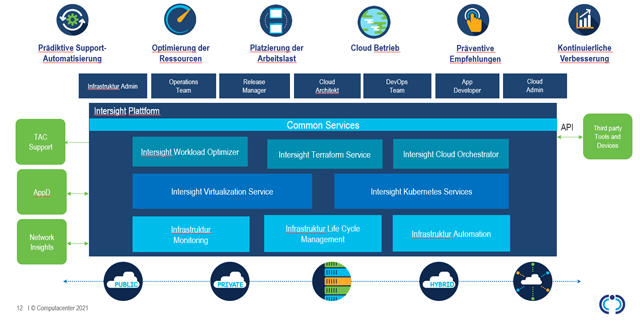
Cisco hat mit der Lösung „Intersight“ eine skalierbare und konsistente Managementumgebung für Rechenzentren inklusive Multi-Cloud-Umgebungen und Anwendungsarchitekturen entwickelt, die das Unternehmen fortlaufend erweitert und weiterentwickelt.
Mit Cisco Intersight erhalten die Kunden alle Vorteile der SaaS-Bereitstellung und des vollständigen Lifecycle-Managements von verteilten Servern mit Intersight-Anbindung. Speichersysteme von Drittanbietern in Rechenzentren, Remote-Standorten, Zweigstellen und Edge-Umgebungen werden ebenso integriert. So können Sie verteilte Umgebungen auf eine Weise analysieren, aktualisieren, reparieren und automatisieren, die mit den Tools früherer Generationen nicht möglich war. Als Ergebnis kann Ihr Unternehmen erhebliche TCO-Einsparungen erzielen und Anwendungen zur Unterstützung neuer Geschäftsinitiativen schneller bereitstellen.
Aufgrund seines modularen Aufbaus ermöglicht Intersight einen iterativen Ansatz bei der Einführung, um so die Vorteile eines zentralisierten Systemmanagements für die eigene Infrastruktur nutzbar zu machen.
Es gibt verschiedene Möglichkeiten, die zum Erfolg führen.
Um Systemmanagement-Projekte erfolgreich abschließen zu können und damit die Lösung möglichst langfristig im Einsatz bleiben kann, sollten im Vorfeld die gewünschten Ziele und Verantwortlichkeiten klar definiert und festgelegt werden. Die Praxis zeigt, dass die Technik beherrschbar ist, große Probleme ergeben sich jedoch immer wieder bei der Umsetzung von organisatorischen Zielen. Aus technischer Sicht ist es zum Beispiel wichtig, dass die Lösung skalierbar ist und sich einfach an veränderliche Gegebenheiten anpassen lässt. Zudem ist für erfolgreiches Systemmanagement die Akzeptanz des IT-Teams unabdingbar. Umfassendes Systemmanagement muss als Vorteil und Erleichterung verstanden werden. Organisation und Arbeitsabläufe in den IT-Abteilungen müssen darauf abgestimmt werden.
Computacenter kann Ihnen als Partner zur Seite stehen, um gemeinsam erfolgreich eine Systemmanagement Lösung zu implementieren. Aufgrund unserer hersteller- und lösungsübergreifenden Expertise können wir Sie sowohl bei der Tool-Auswahl als auch bei der Implementierung mit unserem Know-how unterstützen und stehen bei Fragen an Ihrer Seite. Melden Sie sich am besten gleich bei Ihrem Ansprechpartner bei Computacenter.

Angriffe auf die IT-Infrastrukturen nehmen deutlich zu, eines der ersten Ziele ist häufig die Datensicherung. Doch dem steigenden Risiko steht ein wachsendes Sicherheitsbewusstsein der Unternehmen gegenüber. Das zeigt sich in der zunehmenden Anzahl an Anfragen und Projekten in diesem Bereich. Ein Statusbericht.
An dieser Stelle könnten zahlreiche Zitate und Details aus der Presse stehen, wie beispielsweise „Hacker verschlüsseln Daten: Mehr als 100 Behörden erpresst“ (tagesschau.de) oder „Sechs Ransomware-Gruppen attackieren 2021 mehr als 290 Unternehmen“ (zdnet.de). Das Problem ist, diese Liste ließe sich sehr lange fortführen.
Die Kernaussage ist: Gezielte und intelligente Angriffe nehmen zu und die Hacker haben erkannt, dass die Datensicherung ein wichtiges erstes Angriffsziel darstellt. Aber auch Unternehmen und Behörden identifizieren die Datensicherung zunehmend als einen wichtigen Baustein im Schutz gegen Cyberattacken.
Dabei ist die Datensicherung aus zwei Blickwinkeln heraus zu betrachten:
Lange Jahre lebte die Datensicherung gefühlt ein Schattendasein. Einerseits war die Datensicherung ein Versicherungsschutz, der nur im Schadensfall erforderlich wurde. Andererseits ist die Datensicherung kosten- und pflegeintensiv, da sie Schnittstellen in alle IT-Systeme besitzt und erhebliche Datenvolumen absichern muss – vom eigenen Rechenzentrum bis zu den diversen Clouds und Software-as-a-Service-Angeboten wie beispielsweise Microsoft 365 oder Salesforce.
Schutz der Datensicherung gegen einen Angriff
Durch die zunehmende Bedrohungslage rückt die Datensicherung jetzt verstärkt in das Bewusstsein der Aufsichtsbehörden und Unternehmen. Allein in den letzten Monaten haben sich die Anfragen gehäuft, wie die Datensicherung gegen Ransomware geschützt werden kann.
Die Diskussionen sind vielfältig. Zwei exemplarische Punkte sind:
Geht es nur um den Schutz der eigentlichen Backup-Daten – oder auch dem Schutz der Backup-Regeln wie Aufbewahrungsfristen und Exclude-Bereiche, die in der Software eingestellt werden?
Die Datensicherung dient einem technischen Schutz – dafür ist eine Aufbewahrungsfrist von bis zu vier Wochen angemessen. Nun könnte es sein, dass eine Angriffssoftware sich in die IT-Systeme und deren Datensicherung einschleicht und länger als vier Wochen inaktiv wartet. Soll dann die Ransomware-Absicherung deutlich länger gehen? Andererseits kann mit alten Ständen kein sinnvolles Recovery erfolgen, da die Systemstände sich fortlaufend weiterentwickeln. Damit ist das nur eine scheinbare Option.
Diese Liste an Punkten, die es zu bedenken gilt, lässt sich erweitern um Themen wie eine starke Zwei-Faktor-Authentifizierung für die Datensicherung, die Anbindung an Cyber-Defense-Systeme zum Erkennen und Reagieren auf Angriffe (Detektion & Reaktion), der Einsatz sicherer Netzwerkprotokolle (also keine Sharing-Protokolle wie NFS oder SMB) mit Verschlüsselung oder der strikten Trennung zwischen den Administrationsteams für die Primär- und Backup-Daten. Und all diese Punkte beziehen sich nicht nur auf die Daten im eigenen Rechenzentrum. Auch die Daten in der Cloud und an Außen- und Produktionsstandorten gehören in den Fokus – weil Hackerangriffe auch die Produktions-IT im Visier haben.
Damit gehört der Schutz der Datensicherung auf den Prüfstand und wird zunehmend von den Aufsichtsbehörden in Neufassungen aufgegriffen – wie auch die Notfallvorsorge.
In den Dialogen mit unseren Kunden findet sich dabei eine Mischung aus bestehenden und seit Langem etablierten Sichtweisen, einer seitens der Hersteller durch die eigene vorhandene Funktionalität getriebene Diskussion und einer gewissen Scheu, die Sicherheitsanforderungen – worauf die meisten Punkte in der Auflistung oben abzielen – konsequent anzugehen.
Für den Schutz der Datensicherung ist es wichtig, aus dieser Mischung einen fundierten und gesunden Maßnahmenkatalog abzuleiten und umzusetzen. Nur einzelne Bausteine allein – ohne operatives Modell sowie eine Kontrolle darüber – reichen nicht aus.
Nutzen der Datensicherung zum Recovery nach einem Angriff
Die Anforderungen seitens der ISO 27001 oder des BSI-IT-Grundschutzkompendiums sind klar: Regelmäßige Wiederherstellungsübungen sind notwendig. Auf die Frage, ob und wie häufig solche Wiederherstellungsübungen durchgeführt werden, erfolgen verschiedene Antworten wie „regelmäßige operative Restores erfolgen und dienen als Übung“ zu „Betanken von Testsystemen als Übung“ bis hin zu fehlenden Ressourcen für die Durchführung der Restore-Tests. Aber allen Aussagen ist gemeinsam, dass Übungen im Scope des jeweiligen Teams und der betreuten Anwendung – also der Datenbanken des Typs X oder des E-Mail-Systems – liegen.
Ransomware-Angriffe zielen aber auf die komplette IT-Infrastruktur und nicht auf einzelne Systeme ab. Und fast kein Kunde führt Wiederherstellungsübungen oder Planungen durch, die sich auf eine große Menge an unterschiedlichen IT-Systemen und deren Restores konzentrieren.
In diesem Kontext muss auch eine intensive Automation in Betracht gezogen werden. Das Wiederherstellen einer großen Anzahl an Systemen ist ein Automations- und Workflow-Problem. Wenn es schon möglich ist, IT-Systeme bestehend aus Betriebssystemen und den installierten Applikationen – ohne die Daten der Applikationen – umfänglich automatisiert und auf Basis der Herstellersoftware frisch aufzusetzen – dann ist bereits ein großer Schritt zu einem skalierbaren Recovery-Verfahren erfolgt.
Für ein erfolgreiches Recovery sollten deshalb Infrastructure- und Configuration-as-Code-Ansätze mit der Datensicherung der sich täglich ändernden Daten verknüpft werden, um schnelle skalierbare Recoveries durchführen zu können.
Der Schutz der Datensicherung gegen Ransomware und das Nutzen der Datensicherung zum Recovery nach einem Angriff sind keine Themen, die nur das Backup betreffen und isoliert betrachtet werden können. Um einen bestmöglichen Schutz zu erreichen, müssen neben den eigentlichen Schutzverfahren auch die Technik sowie Betriebskonzepte berücksichtigt werden. Durch Automationsverfahren lässt sich eine systemübergreifende Skalierbarkeit der Datensicherung erreichen, die einen hohen Nutzen mit sich bringt.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zum Datenmanagement und zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

Agile Arbeitsweisen und die Ideen hinter Methoden wie Scrum bringen interessante Diskussionen auf: Wird agil gearbeitet, wenn Scrum-Artefakte wie Daily Standup bemüht werden? Lässt sich mit Scrum tatsächlich die Effizienz steigern? Eindrücke aus einem breiten Spektrum an Gesprächen und Erfahrungen.
Der Scrum-Prozess liefert als Ergebnistypen sogenannte Product Increments (Inkremente). Das Ergebnis wird von einer Rolle Scrum Developer erstellt und am Ende des Sprints im Sprint Review vorgestellt. Das Inkrement ist ein neues Feature oder eine Produkteigenschaft, die während des Sprints erstellt wurde. Nach der Scrum-Logik kann ein Inkrement potenziell sofort in Produktion gebracht werden.
Bei einem Produkt wie einem Auto bedeutet das, dass der Kunde sofort mit diesem neuen Feature losfahren kann. Aber wollen wir mit dem neuen Feature wirklich sofort unsere große Urlaubsreise antreten?
Natürlich trifft das Scrum-Team im Vorfeld Vereinbarungen über die Definitions of Done (DoD). Wann ist ein neues Feature oder Inkrement fertiggestellt und nutzbar? An diesem Punkt tritt jedoch häufig ein allzu menschliches Verhalten zutage: Wir wollen ein technisches Feature erstellen und liefern – eine gelungene Funktion, die Mitmenschen anspricht und Freude bereitet. Nun wird Scrum aber zunehmend dazu verwendet, IT-Infrastrukturen im Kontext Cloud und Container aufzubauen und zu betreiben.
Also werden im Sprint Features entwickelt, die von den Kunden beziehungsweise Applikationsteams aktiv genutzt werden, um auf deren Basis Software für das Unternehmen zu entwickeln und zu betreiben. Das kann von Webshops über Webauftritte bis hin zur Produktionssteuerung reichen. Und wenn der IT-Unterbau ein neues Feature liefert, dann muss es in das Error Budget der Applikation passen, das heißt, es muss sich im Rahmen der geforderten Verfügbarkeit bewegen.
Das führt bei einem Sprint Review zu Fragen, ob neben der technischen Funktionalität sichergestellt sei, dass das Inkrement sicher ist und sich aktiv meldet, wenn es ein Problem hat. Und auch, ob das erfolgreich getestet wurde.
Bleiben wir einmal beim Thema Test. Natürlich geht es dabei darum, zu prüfen, ob das technische Feature funktioniert – aber aus welcher Sichtweise? Hat der Scrum Developer es nur aus der IT-Sicht betrachtet oder hat er sich auch die Person des Applikationsteams oder Kunden hineinversetzt, um die Eigenschaften selbst zu testen?
Die Reaktionen auf solche Fragen sind sehr breit gefächert. Sie reichen von Unverständnis – „das technische Feature ist fertig und kann an den Betrieb übergeben werden“ (was im Gedanken von DevOps nicht existieren sollte) – zu Verständnis – „wir haben es getestet, aber wir hatten noch keine Zeit, uns die Kundensicht anzuschauen“. Und dazwischen gibt es viele Abstufungen.
Es entsteht der Eindruck, dass Scrum oder agile Methoden als Freiheit verstanden werden – als Freiheit des Teams, sich selbst zu organisieren, die Themen, die im Sprint bearbeitet werden, auszuwählen und ansonsten die guten technischen Ergebnissen vorzustellen und sich dafür loben zu lassen. Aber die Verantwortung hinter dem Inkrement – schließlich fahren wir damit in den Urlaub – und das konsequente Testen, das dazugehörige Team-Review und das Abklopfen der potenziellen Sicherheitslücken sowie das Umsetzen von Anforderungen aus der IT-Sicherheit passen nicht zu dieser Freiheit.
Das betrifft natürlich nicht nur das Developer-Team. Auch Rollen wie Product Owner oder Scrum Master müssen sich hin und wieder selbst reflektieren. So liegt das Produkt-Backlog in der Verantwortung des PO. Wenn also in den Gesprächen Fragen dazu aufkommen, was eigentlich die geplanten und priorisierten Aufgaben sind, dann sind hier die Zuständigkeit und die Verantwortung eindeutig geregelt.
Die Rechnung ist einfach: Die Scrum-Artefakte kosten Zeit und sind sauber vorzubereiten. Einen PO mit einem Anteil von 20 Prozent der Arbeitszeit einzusetzen, kann nicht funktionieren. Genauso wenig wie ein Developer, der zu 30 oder 40 Prozent ausgeliehen ist, seinen Aufgaben vollumfänglich nachkommen kann.
Die Methode funktioniert, wenn neben der Freiheit die Verantwortung und Identifikation mit dem Inkrement und der Funktion und Qualität existieren und ein starker Fokus daraufgelegt wird.
Es ist eine Kunst, ein Scrum-Team aufzubauen und die Balance zwischen technischer Kreativität und Freiheit verbunden mit Sicherheit und Verantwortung für das Ergebnis hinzubekommen. Vielleicht muss die verantwortliche Person einmal nachts von einem dringenden Support-Call geweckt werden – damit das nächste Inkrement nicht nur technisch brilliert, sondern auch dem eigenen Qualitätsanspruch genügt. Und der eigene Anspruch sollte identisch zu dem des Teams sein – allein zu feiern, macht schließlich keinen Spaß.
Welches Fazit lässt sich aus diesen Eindrücken und Erlebnissen ziehen? Es ist wichtig, sich selbst und das Team regelmäßig zu hinterfragen und mit dem Ergebnis transparent umzugehen. Denn gemeinsam feiern zu können, ist das schönste Ergebnis – und zum Feiern braucht es zufriedene Kunden.