VDI by Day, Compute by Night

Sehr geehrte Damen und Herren,
die häufig vorhandene immense Rechenkapazität von GPUs bleibt streckenweise ungenutzt. Möglichkeiten, wie Rechenzentren diese zumindest zeitweise für besonders rechenintensive Workloads nutzen können, stellen wir Ihnen in der aktuellen Ausgabe unseres Datacenter-Newsletters vor.
In den Unternehmen wird die Multi-Cloud-Strategie zum Standard. Doch wie lässt sich dabei die Desaster-Recovery-Fähigkeit sicherstellen? Wir haben die Antwort.
Mit den passgenauen Services von Computacenter lassen sich Infrastrukturen einfacher als je zuvor bereitstellen, betreiben und skalieren. Wie auch Sie bei Ihrem Rapid Datacenter Deployment von den Vorteilen profitieren können, erfahren Sie in einem unserer Fachbeiträge.
Lesen Sie außerdem, wie Splunk Business Flow Ihnen dabei hilft, manuelle Aufwände bei der Identifikation und Modellierung von Prozessschritten, Gesamtabläufen und Variationen zu reduzieren.
Haben auch Sie schon mit dem Gedanken gespielt, in Ihrem Unternehmen künstliche Intelligenz zu nutzen? Der Einstieg kann ganz leicht gelingen, dank des AI-Starter-Pakets von Computacenter. Wir zeigen Ihnen, wie es funktioniert.
In unserer Backup-Kolumne beschäftigen wir uns mit den Zuständigkeiten für Backup/Restore bei Softwarelösungen, die auf Containern basieren und Paradigmen wie Micro Services verwenden. Und in unserer Agile-IT-Kolumne dreht sich dieses Mal alles um die beste Strategie zur Ausstattung zukünftiger Rechenzentren.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter ist einer der besten Ausbildungsbetriebe in Deutschland, laut einer aktuelle Studie des Wirtschaftsmagazins Capital.
Weitere InfosDas Frauenmagazin Brigitte und die Personalmarketing-Experten von Terrotory Embrace haben Computacenter erneut unter die besten Deutschen Arbeitgeber für Frauen gewählt.
Weitere Infos
Bisher nutzen wir die Möglichkeiten der Virtualisierung fast ausschließlich auf CPU-Basis. Dabei könnten beispielsweise GPUs mit ihrer immensen Rechenkapazität zu hervorragenden Ergebnissen führen, die CPUs niemals erreichen könnten. Computacenter zeigt die Möglichkeiten auf.
CPUs haben heutzutage bis zu 56 Kerne Rechenleistung, im Vergleich dazu hat das GPU-Topmodell von Nvidia 5.120 Kerne Rechenleistung. Was könnte man nur alles mit dieser GPU-Rechenleistung anfangen? Die erste Idee ist natürlich, grafikintensive Workloads damit zu adressieren. Über die Jahre hinweg hat sich dieser Bereich tatsächlich enorm weiterentwickelt. Während es zu Beginn eher um kleine CAD-Bereiche ging, wurde die Nutzung der Rechenleistung von Grafikkarten etwa im Jahr 2016 immer mehr Mainstream. Ein großer Meilenstein wurde 2018 mit der Unterstützung von VMware vMotion erreicht. Jetzt müssen GPU-aktivierte virtuelle Maschinen nicht mehr ausgeschaltet werden, wenn Admins Wartungen durchführen müssen.
Immer mehr unserer Kunden verwenden GPUs heute in ihren Rechenzentren. Tagsüber arbeiten die Mitarbeiter auf ihren VMs, nachts dagegen kann die Rechenleistung der GPUs anderweitig genutzt werden. Das spiegelt genau den Gedanken von „Any Workload, Any Time“ wider. Während tagsüber die GPUs für Grafik-Workloads (Office-Arbeitsplätze sind heutzutage leider auch grafikintensiv) verwendet werden, wird nachts auf den GPUs gerechnet. Künstliche Intelligenz (AI; vom englischen Begriff artificial intelligence), Machine Learning (ML) und Deep Learning (DL) sind hier die Schlagworte.
Für GPU-Nutzung in VMs wird die vGPU-Technologie von Nvidia verwendet. Damit ist es möglich, eine Grafikkarte in mehrere Profile aufzuteilen. Jede virtuelle Maschine kann dann einen Teil der echten Grafikkarte verwenden, womit eine sehr hohe Packungsdichte erreicht wird. Dieses Verfahren wird in erster Linie für Virtual-Desktop-Infrastukturen (VDI) und für Terminalserver angewendet. Immer mehr Kunden stellen auch ihre Terminalserver-Farmen auf GPUs um, da dadurch die User Experience erhöht wird und mehr User an einen Terminalserver angeschlossen werden können. In VDI-Umgebungen kommt man quasi gar nicht mehr um GPUs herum. Das neueste Windows 10 Release benötigt beispielsweise bis zu 44 Prozent mehr GPU-Leistung als noch Windows 7.
AI, Machine Learning und Deep Learning sind die großen Themen unserer Zeit. Doch was genau steckt eigentlich dahinter?
Der Begriff AI stammt aus den 1960er-Jahren, wo die ersten Schachspiele am Computer erfunden wurden. Wir spielten gegen einen Rechner und hatten für damalige Begriffe 3D-Anzeigen im Spiel. In den 1990er-Jahren wurde der Begriff Machine Learning geprägt. Bestes Beispiel dafür ist unser E-Mail-Spamfilter. Gegen 2010 hat sich der Begriff Deep Learning durchgesetzt. Damit bezeichnen viele Leute die Bilderkennung durch Rechner. Damit ein Computer erkennt, ob auf einem Bild eine Katze oder ein Hund zu sehen ist, benötigt man Millionen von Datensätzen, um ein solches System zu trainieren. CPUs sind dafür leider viel zu langsam, womit wir wieder bei den GPUs wären.
Heutzutage generieren immens viele Systeme Daten, angefangen bei Edge- oder IoT-Instanzen über autonome Fahrzeuge bis hin zu Big-Data-Systemen. All diese Datenquellen und Informationen müssen ausgewertet und analysiert werden. Dazu verwendet man leistungsstarke GPUs. Die Anforderungen an solche Projekte sind gewaltig. Die eingesetzten Tools verfügen über sehr spezielle Konfigurationen, müssen extrem agil einsetzbar sein, gleichzeitig aber Enterprise-Ready betreibbar sein und ein einheitliches Management besitzen. Ein sehr gut umgesetztes Beispiel dafür ist die Nvidia GPU Cloud, kurz NGC. Abgestimmte AI-Libraries mit GPU-beschleunigten Containern, installiert in Stunden anstelle von Wochen, können On-Premises oder in der Cloud ausgerollt werden.
Tagsüber nutzen wir also die GPUs für Desktops und Terminalserver und nachts quasi die ungenutzten Ressourcen für AI, ML und DL. Es gibt eine Menge verschiedener Grafikkarten von Nvidia für die einzelnen Anforderungen, darunter zwei GPU-Typen, die sich für beide Workloads hervorragend eignen: die T4-GPU (Single Slot) und die V100-GPU (Dual Slot).
Für das Scheduling der verschiedenen Workloads können VMware-Bordmittel genutzt werden. Tagsüber laufen die VDI- und Terminalserver-VMs auf den GPUs, werden abends heruntergefahren und dann die AI-, ML- und DL-Workload-VMs gestartet. Und so weiter. Ein Problem bleibt jedoch: Die einzelnen VMs müssen heruntergefahren werden. Das ist heutzutage nicht mehr zeitgemäß.
Ein besserer Ansatz ist der Einsatz von Workload-Managern oder intelligenten Scripting-Lösungen. Diese ermöglichen es, lastabhängig die ungenutzten VMs in den Suspend-Modus zu versetzen und die dann freigewordenen Ressourcen für die AI-VMs zu verwenden. Somit werden die GPUs im Rechenzentrum 24/7 verwendet -> Any Workload, Any Time.
Möchten Sie mehr zum Thema erfahren? Ihr Ansprechpartner bei Computacenter informiert Sie gern!

Im Jahr 2020 sollen laut Analysen von IDC bereits 66 Prozent der Unternehmen in der Region EMEA eine Multi-Cloud-Strategie implementiert haben. Das bedeutet, unternehmenskritische Applikationen sind nicht nur in einem eigenen Datacenter angesiedelt, sondern verteilen sich über diverse On-Premises- und Hyperscaler-Plattformen. Doch wie lässt sich hierbei die Desaster-Recovery-Fähigkeit sicherstellen?
Will man herausfinden, ob bei einer Multi-Cloud-Strategie eine Fähigkeit zu Desaster Recovery (DR) vorliegt, ist eine zentrale Sicht auf Business-Applikationen notwendig, die wahlweise On-Premises oder bei einem oder mehreren Hyperscalern (AWS, Azure, andere) betrieben werden. Jede dieser Applikationen besteht aus einer Reihe von Services, die in Summe die Business-Applikation ausmachen. Das umfasst beispielsweise Web Application Services, Datenbanken und File Shares, die als Transferverzeichnisse verwendet werden. In modernen Applikationen können aber auch weitere Micro Services und native Hyperscaler-Services additiv verwendet werden.
Daher ist es notwendig, einen Business Service mit seinen technischen Komponenten in einer logischen Einheit (Virtual Business Service) zusammenzufassen und zu verwalten. Dabei können alle Komponenten entweder auf Basis einer Infrastruktur (Beispiel: im eigenen Datacenter oder bei einem Hyperscaler) betrieben werden oder es wird eine hybride Umgebung verwendet, die sich auf eigene Datacenter und / oder einen oder mehrere Hyperscaler verteilt.
Für eine DR-Fähigkeit ist für solche Virtual Business Services eine Automation erforderlich, weil ein Desaster Recovery für die relevanten Business Services zwingend notwendig ist. Dazu gehören Failover- und Failback-Maßnahmen sowie DR-Tests beziehungsweise Simulationen mit einem aussagekräftigen Nachweis der DR-Fähigkeit für Auditoren und Prüfer. In dem Rahmen ist auch zu definieren, wo eine DR-Fähigkeit für die Business Services bereitgestellt werden soll. Hierzu sind Entscheidungen im Unternehmen zu treffen, ob die Anforderungen bezüglich einer ausreichenden Entfernung erfüllt sind oder ob ein alternativer Infrastruktur-Provider (zweiter Hyperscaler oder hybrides Modell aus On-Premises und Hyperscaler) erforderlich ist, um die DR-Fähigkeit zu erreichen.
Neben den organisatorischen Rahmenbedingungen und der Definition der notwendigen Notfallkonzepte ergibt sich hier bereits eine Reihe von Anforderungen an eine Technologie zur Steuerung der DR-Fähigkeit. Die Anforderungen umfassen:
An dieser Stelle wird nicht die Motivation für eine Desaster–Recovery-Strategie behandelt. Unternehmen werden durch Auflagen von Regulierungsbehörden und durch rechtliche Vorgaben dazu angehalten, eine Business-Continuity-Strategie zu etablieren, fortlaufend weiterzuentwickeln und zu testen. Das reicht von aktuellen Notfallkonzepten und Abläufen bis hin zu jährlichen DR-Tests. Einige Facetten hiervon haben wir bereits in einer früheren Ausgabe des Datacenter-Newsletters betrachtet. In dieser Ausgabe möchten wir uns stattdessen der Umsetzung einer Multi-Cloud-DR-Strategie auf Basis konkreter Lösungen widmen.
Einen Einstiegspunkt hierzu liefert der „Market Guide for IT Resiliency Orchestration“ (ITRO) von Gartner (ID G00373628 vom 19.10.2018). Unter anderem werden hier die technischen Anforderungen für ITRO-Lösungen in sieben Kategorien unterteilt, die die eingangs aufgeführten Anforderungen an eine entsprechende Lösung reflektieren:
Weiterhin werden die Lösungen am Markt in vier Kategorien aufgeteilt:
Bei der Auswahl der geeigneten Lösungen sind die Anforderungen des jeweiligen Unternehmens und vor allen Dingen auch die Service Levels, speziell die Recovery Point and Time Objectives (RTO / RPO), relevant.
Gerade bei Großunternehmen mit einem breiten Spektrum an Applikationen und einer ausgeprägten Multi-Cloud-Strategie werden singuläre Lösungsansätze und spezialisierte Produkte für einige wenige Use Cases zu einem Engpass.
Im Rahmen der Desaster-Recovery-Service-Beratungsmethodik zeigt sich in den diversen Kundenprojekten, dass eine ITRO-Lösung ein hohes Maß an Flexibilität liefern muss, damit die diversen Business Services mit dem jeweiligen technischen Stack integriert werden können.
Dies rückt in den entsprechenden Projekten die Lösungen im Bereich „Multi Data-Mover Support for Replication“ in den Vordergrund. In keinem Projekt ist eine singuläre Lösung beispielsweise nur für den Hypervisor ausreichend, da immer weitere Replikationsverfahren integriert werden müssen. Dabei sollte unter dem Begriff Multi Data-Mover auch die Anforderung an unterschiedliche RTOs / RPOs berücksichtigt werden. So können die primären Applikationen über eine möglichst zeitnahe Replikation (bei der BSI-Vorgabe von 200 Kilometern ist eine synchrone Replikation technisch nicht umsetzbar) abgesichert werden, während nachgelagerte Anwendungen über eine Datenreplikation beispielsweise auf der Backup-Ebene abgesichert werden können.
Eine Applikation mehrfach abzusichern, ist jedoch nicht sinnvoll. Wenn eine Datenbank bereits eine Replikation durchführt (Microsoft SQL Server mit AlwaysOn als Beispiel), dann macht es keinen Sinn, diese durch eine weitere Replikation abzusichern und mehr Daten als erforderlich zu übertragen. Also sollte eine ITRO-Lösung entsprechend flexibel mit diversen Data Movern umgehen können.
Eine zweite zentrale Komponente neben der Replikation der Daten ist eine integrierte Workflow-Funktionalität in der ITRO-Lösung, um die Steuerung der komplexen DR-Abläufe durchzuführen.
Dabei geht es um wesentlich mehr als eine reine Sequenzierung von Start-Stop-Abläufen bei einem Failover. Gerade in einem Multi-Cloud-Kontext sind die Infrastruktur-Services (DNS, Identity Management, Routing, …) zu berücksichtigen und anzupassen (Beispiel: Failover von Azure nach AWS). Auch sind oft individuelle Ressourcen und Komponenten einzubinden, die zwingend eine hohe Anpassbarkeit der Workflows und Abläufe bis hin zu individuellen Schritten und Skripten erfordern. Somit ist die Workflow Engine und deren Anpassbarkeit eine zweite zentrale Komponente der ITRO-Lösung.
Eine konkrete Lösung ist das Produkt Veritas Resiliency Platform (VRP). VRP ist seit über fünf Jahren am Markt und setzt auf der langjährigen Erfahrung von Veritas im Kontext Hochverfügbarkeit und Desaster-Recovery-Fähigkeit auf. Das umfasst auch die spezifische Integration der eigentlichen Business Services und das entsprechende Applikations-Know-how.
Frühzeitig hat Veritas hier auf eine Integration von Open-Source-Software gesetzt. Eine integrierte Kernkomponente von VRP ist jBPM. Hierbei handelt es sich um eine flexible Business-Process-Management-Lösung, mit der flexible Workflows und Automation abgebildet werden können. Parallel dazu unterstützt Veritas diverse externe Data Mover von Storage-Anbietern (Dell EMC, NetApp, HPE, Hitachi, IBM), Hypervisor-Lösungen (VMware vSphere, Microsoft Hyper-V und Hyper-V-Replika sowie KVM und Openstack) bis hin zu Applikationen (Oracle, Microsoft SQL Server). Zudem unterstützt die Lösung zwei eigene Replikationsverfahren (virtualisierungsbasiert mit Konvertierung zu Hyperscaler-Lösungen und der eigenen Datensicherungslösung NetBackup).
Damit bietet Veritas von den bestehenden Lösungen am Markt die höchste Flexibilität in Bezug auf Replikation und Orchestrierung.
VRP unterstützt ebenfalls die Gruppierung von Business Services in Virtual Business Services und DR-Simulationen mit einem aussagefähigen Audit-Dokument, um eine granulare DR-Fähigkeit in der Multi-Cloud zu erreichen.
Vereinbaren Sie gern einen Termin, um sich die Veritas Resiliency Platform vorführen zu lassen. Darüber hinaus informieren wir Sie gern weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Desaster-Recovery-Strategie – aber auch allgemein zu Datensicherung und Archivierung. Rufen Sie am besten gleich an!

Im Zeitalter der Cloud muss die Bereitstellung von IT-Services immer schneller erfolgen – On-Premises-Infrastrukturen bilden da keine Ausnahme, weil sie in direktem Wettbewerb mit Cloud-Angeboten stehen. Auch Flächen-Rollouts von Servern oder Switchen zu verschiedenen Niederlassungen sollten so schnell und reibungslos wie möglich ablaufen. Computacenter hat eine Gruppe von Services entwickelt, die all das ermöglicht.
Anwender und Fachabteilungen wollen Infrastrukturdienste einfach und flexibel für ihre Projekte nutzen. Die Entwicklung und Nutzung hybrider Cloud Services ist heutzutage ein optimaler Ansatz, um On-Premises-Kapazitäten im eigenen Rechenzentrum mit Ressourcen (IaaS) oder Mehrwertdiensten (PaaS / SaaS) aus den Public Clouds nutzbar zu machen und in die IT-Bereitstellung zu integrieren.
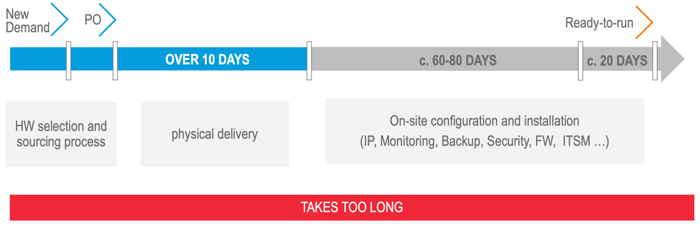
Die Herausforderungen hierbei sind vielfältig. Der Projektverlauf beinhaltet einen hohen zeitlichen Aufwand von der Beschreibung der Anforderung über die Konzeption (Grob- und Feinkonzept) und die Erstellung einer beauftragbaren Stückliste (BoM) bis hin zur eigentlichen Inbetriebnahme. Dabei entstehen häufig hohe Projektkosten aufgrund aufwendiger Prozesse und der Koordination vieler Ansprechpartner und Erbringungseinheiten.
Bei der Beschaffung entstehen weitere Herausforderungen, wenn zum Beispiel der Einsatz von Converged-Infrastruktursystemen mit verschiedenen Herstellern und Lieferanten geplant wird. Dabei müssen neben den verschiedenen Bestellwegen und Ansprechpartnern auch die Anlieferungen von verschiedenen Herstellern terminlich koordiniert werden.
Bei der Implementierung der Umgebungen können weitere Gegebenheiten auftreten, die die notwendigen Arbeiten erschweren oder verzögern. Fehlende Assembling-Flächen im Rechenzentrum oder an Co-Location-Standorten sowie Staub und Brandlast durch die Umverpackungen im Rechenzentrum sorgen für zusätzliche Aufwände – sowohl zeitlich als auch kostenseitig. Mögliche verdeckte Transportschäden und unterschiedliche Firmware-Stände der Komponenten – mitunter innerhalb einer Lieferung – sind zusätzliche Herausforderungen, die entstehen können.
Mit dem Rapid Datacenter Deployment ermöglicht Computacenter seinen Kunden, IT-Services wesentlich schneller bereitzustellen.
Mithilfe unserer modularen Dienstleistungen ist es möglich, auch bei kleinen Infrastrukturprojekten eine hohe Wertschöpfung zu generieren und typische Probleme, wie sie in der Einleitung skizziert wurden, zu beseitigen oder abzumildern. Dank unserer Services lässt sich beispielsweise der Zeitraum der Infrastrukturbereitstellung deutlich verkürzen. Auch die anschließende Softwareinstallation unterstützen wir mit unseren Services – bis hin zur vollständig automatisierten Softwareinstallation, dem sogenannten Zero Touch Deployment.
Neben einer schnelleren IT-Bereitstellung für Private-Cloud-Rechenzentren berücksichtigen wir auch den Rollout in Niederlassungen oder Filialen mit IT-Infrastruktur. Immer wieder führen wir Projekte im Bereich Rechenzentren und Vernetzung durch, in denen Niederlassungen neu ausgestattet oder erneuert werden. Auch hier gelten die Grundzüge klassischer Rollout-Projekte, wie sie am Arbeitsplatz üblich sind – aber es gibt auch Besonderheiten, die berücksichtigt werden müssen.
Das Service Framework „Rapid Datacenter Deployment“ besteht aus vielen einzelnen und individuell kombinierbaren Modulen innerhalb von vier Phasen eines typischen Infrastruktur-Lifecycles:
Mithilfe unserer modularen Services können Sie die Transformation der IT hin zum Service Provider optimal vollziehen. Die Bereitstellung von Services wird zeitlich optimiert und mit hoher Qualität und Zuverlässigkeit ermöglicht. Zur Nutzung dieser Services bedarf es keiner besonderen Voraussetzungen. Gemeinsam mit unseren Experten setzen wir auf die bestehende Umgebung und schon vorhandene Prozesse auf und entwickeln gemeinsam mit Ihnen eine Roadmap zur Nutzung von Rapid Datacenter Deployment Services sowie alle notwendigen begleitenden Services. Durch die einzeln zu kombinierenden Module ist der Service individuell an Ihre Situation anpassbar.

Mit unseren Services lassen sich Infrastrukturen einfacher als je zuvor bereitstellen, betreiben und skalieren. Mit jedem neu hinzugefügten Server steigt aber auch der Konfigurations- und Verwaltungsaufwand erheblich. In diesem Zusammenhang spielt „Infrastructure as Code (IaC)“ eine zentrale Rolle. Es handelt sich dabei um einen modernen Lösungsansatz, bei dem sämtliche benötigten Schritte zum Aufsetzen von Infrastruktur und zum Durchführen von Softwarebereitstellungen im Quellcode hinterlegt werden. Konfigurationsänderungen an Infrastrukturkomponenten wie Servern, Betriebssystemen und Netzwerkdiensten werden nicht mehr direkt auf den jeweiligen Systemen, sondern über spezielle Automation Tools vorgenommen. Der entscheidende Vorteil liegt darin, dass sich so Systemkonfigurationen testen, versionieren und automatisiert replizieren lassen.
In unserem nächsten Newsletter erfahren Sie mehr zum Thema. Selbstverständlich steht Ihnen darüber hinaus Ihr Ansprechpartner bei Computacenter jederzeit für eine Beratung zur Verfügung.

Splunk Business Flow hilft dabei, digitalisierte Prozesse und deren einzelne Schritte auf Basis von Logs oder Events aus unterschiedlichsten Systemen als Gesamtabläufe darzustellen, Laufzeiten, Variationen und Anomalien zu identifizieren und so die Prozesse zu optimieren. Der besondere Clou: Durch eine intuitive Oberfläche ist die Prozessanalyse auf Basis von detaillierten Daten auch für „Nicht-Programmierer“ ein Kinderspiel.
Mit steigendem Digitalisierungsgrad der Geschäftsprozesse in Unternehmen entstehen neue Herausforderungen bei der Steuerung und Optimierung des Geschäfts mithilfe kritischer KPIs wie Prozesslaufzeiten oder Konvertierungsraten. Oft ist es wegen heterogener Systemlandschaften oder fehlender Digitalisierung schwierig, eine Ende-zu-Ende-Transparenz in komplexe Transaktionen und Abläufe zu bekommen. Traditionelle Ansätze beschränken sich zudem auf historisierte Daten, ohne den Unternehmen die Möglichkeit zu bieten, auch aktuelle Prozessvariationen abzubilden.
Process Mining ist eine Methode der Geschäftsdatenanalyse. Damit lassen sich automatisiert Muster erkennen, Laufzeiten berechnen und Prozessschritthäufigkeiten identifizieren. Auf diese Weise hilft Process Mining dabei, die Prozesse im Unternehmen zu verstehen und so zu verbessern. Die in den unterschiedlichen Systemen gespeicherten einzelnen Schritte eines Prozesses werden anhand überlappender Merkmale zusammengefügt und der Prozess in seiner Gesamtheit visualisiert. Process Mining ermöglicht es so, in Daten enthaltenes, implizites und ansonsten verborgenes Prozesswissen zu heben.
Die Ziele bestehen oft darin, die Prozesse über verschiedene Organisationseinheiten und Gesellschaften hinweg zu harmonisieren sowie sie in Bezug auf Durchlaufzeiten, Prozesskosten und Prozessstabilität zu optimieren.
Beispiele:
Splunk Business Flow setzt auf Splunk Enterprise als zentrale Datenplattform auf, welches bereits alle relevanten Quellen beinhaltet. Business Flow hilft als Process-Mining Lösung, Transparenz in die digitalisierten Prozesse zu bringen. Durch Automatismen werden aus Logs und Events Muster erkannt, was manuelle Aufwände bei der Identifikation und Modellierung von Prozessschritten, Gesamtabläufen und Variationen reduziert. Gleichzeitig werden Metriken wie Laufzeiten je Schritt oder Häufigkeiten bestimmter Prozessschrittkombinationen bestimmt. Analysten erhalten diese Daten in einer intuitiven Oberfläche visualisiert aufbereitet. Darüber können sie beispielsweise eigene Variationen modellieren und in direkter Gegenüberstellung zu kritischen Pfaden analysieren, um Optimierungspotenzial bei kritischen Prozessschritten zu erkennen, ohne explizite Abfragen programmieren zu müssen.
Neugierig? Sprechen Sie uns einfach an und wir stellen Ihnen die Lösung gern im Detail vor.

Künstliche Intelligenz ist in aller Munde und es gibt zahlreiche Ideen für Anwendungen – doch wie fängt man eigentlich konkret an? Ganz einfach: mit dem AI-Starter-Paket von Computacenter.
Unser AI-Starter-Paket haben wir in Zusammenarbeit mit unseren Partnern entwickelt. Es umfasst Hardware, Software sowie Dienstleistungsangebote. Die Lösung richtet sich insbesondere an die Fachabteilungen, welche sich mit Analytics und AI beschäftigen, jedoch wenig IT-Know-how besitzen.
Um AI-Lösungen zu erstellen, werden Infrastruktur, Software und Services benötigt. Der Aufbau einer Lösungsarchitektur kann aufgrund der vielen Abhängigkeiten sehr komplex sein. Hinzu kommt die Herausforderung einer hohen Agilität der Frameworks, da unterschiedliche Data Scientists, Data Engineers und ML Engineers unterschiedliche Umgebungen benötigen, die jedoch möglichst auf einer Plattform abgebildet werden sollen.
Eine weitere Herausforderung besteht oft darin, dass die zentrale IT-Infrastruktur der Fachabteilung die benötigten Ressourcen nicht zeitnah zur Verfügung stellen kann. Außerdem geht häufig viel Zeit bei der internen Abstimmung der konkreten Anforderungen verloren.
Eine einfache und schnelle Lösung bietet unser AI-Tower-Starterpaket, ein mobiles System, das alle Funktionalitäten beinhaltet, die zur Erstellung von Analytics- und AI-Projekten benötigt werden. Die gesamte Lösungsarchitektur ist bereits vorinstalliert und vorkonfiguriert, sodass Sie direkt mit der Entwicklung ihrer AI-Lösung beginnen können. Sie erhalten zudem ein umfangreiches Dienstleistungspaket, das Sie beim Aufbau Ihres Analytics-und-AI-Projekts optimal unterstützt.

Reicht die „AI in a Box“ nicht mehr aus, können über ein T-Shirt-Sizing schnell Plattformen definiert werden, die über eine solche Testphase hinaus genutzt werden sollen und eine erste Vorproduktion oder Produktionsumgebung abbilden können.
In jedem Projekt zeigt sich: Die Grundlage für eine erfolgreiche Umsetzung von AI Use Cases ist eine Qualifizierung, welche Use Cases den Reifegrad haben, erfolgreich umgesetzt zu werden, und auch nur diese in einen PoC beziehungsweise in die Produktion zu überführen.
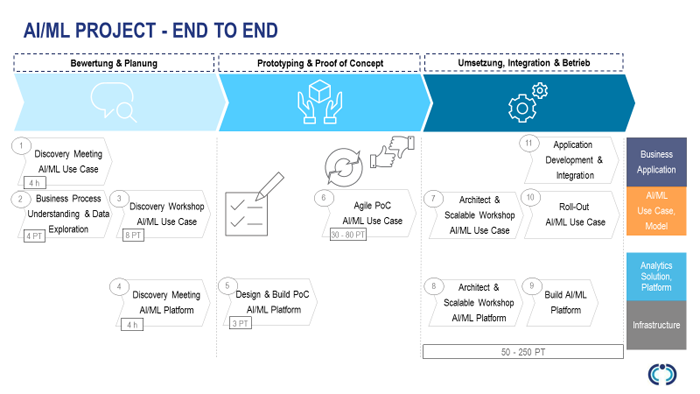
Für diese Umgebungen muss dann eine an die Produktion angepasste skalierbare Architektur entworfen und implementiert werden. Darüber hinaus ist oft eine Integration des AI-Modells in die kundenspezifische Applikationslandschaft notwendig.
Fazit: Bei einem Analytics- und AI-Projekt sollte man schon früh anfangen, die AI Use Cases zu priorisieren und zu qualifizieren!
Haben wir Ihr Interesse geweckt? Dann vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie im Bereich AI zu informieren.

Zunehmend bauen Kunden neue Softwarelösungen basierend auf Containern mit Kubernetes und verwenden Paradigmen wie Micro Services. Sobald diese Anwendungen die Produktionsreife erreichen, kommt die Anforderung nach einem Backup/Restore auf. Aber wie sind hier eigentlich die Zuständigkeiten?
Grundlage für das Zuordnen von Zuständigkeiten ist die Frage, was konkret zu sichern ist und welches Team ein Backup/Restore benötigt. Dazu sind vorab ein paar Begriffe und technische Aspekte zu klären.
Sinnvollerweise würden die Zuständigkeiten zwischen drei Einheiten beziehungsweise Teams verteilt. Die Teams sind:
Basierend auf diesem Modell empfiehlt sich eine Verteilung der Zuständigkeiten wie folgt:
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

Viele Unternehmen haben heutzutage einen Virtualisierungsgrad von 90 Prozent oder mehr erreicht. Parallel wird, getrieben durch moderne Softwareentwicklung, der Einsatz von Container-Technologien und Kubernetes zunehmend populär. Und Openstack als Enabler für Private Clouds ist in vielen Kundengesprächen präsent. Da stellt sich die Frage: Mit welcher Ausrichtung sollen die zukünftigen Datacenter ausgestattet werden?
Virtualisierung ist heute in den Rechenzentren die Plattform für die Applikationen, welche fortlaufend mit einer planbaren Last betrieben werden. Hierbei handelt es sich um die Kernsysteme wie Messaging, Datenbanken, Directory und File Services sowie die fachspezifischen Applikationen. Diese werden auf Virtualisierungs-Cluster aufgesetzt und laufen kontinuierlich für mehrere Jahre. Openstack ist ein Open-Source-Projekt, welches auf bestehende Hypervisor (KVM, vSphere, andere) aufsetzt und einen Satz von APIs für Softwareentwickler bereitstellt – mit dem Ziel, schnell viele virtuelle Systeme bereitzustellen und bei Bedarf auch wieder zu deaktivieren. Das Ziel sind hier Scale-out-Architekturen, in denen Workloads on-demand abgebildet werden.
Dazu ist vor vielen Jahren der Vergleich Haustier versus Nutztier (das Zitat „pets vs. cattle“ wird Tim Bell zugeordnet) herangezogen worden. Während klassische Virtualisierungsarchitekturen auf eine Scale-up-Architektur ausgelegt sind, ist Openstack als eine Scale-out-Architektur entwickelt worden. Das Ziel einer solchen Scale-out-Architektur ist, dass von potenziell Dutzenden bis Hunderten Servern jederzeit einzelne Systeme ausfallen können und der Service beziehungsweise die Applikation(en) weiterhin verfügbar sind.
Allerdings können solche Scale-out-Modelle nicht allein auf Virtualisierungs- oder Infrastrukturebene abgebildet werden. Das eigentliche Applikationsdesign muss dafür adaptiert werden. Das erfordert eine Re-Architektur der Anwendungen.
Das spiegelt sich in verschiedenen Modellen für eine moderne Softwarearchitektur wider. Beispiele sind:
Um dies greifbar zu machen: Bei einer Scale-out-Architektur muss, um gegen einen Ausfall abgesichert zu sein, die Applikation beziehungsweise deren Bausteine immer mindestens zwei Mal gestartet werden und sich gegenseitig absichern – sinnvollerweise verteilt auf zwei Brandbereiche.
Dabei ist die Abgrenzung wichtig, dass hier keine Lösung auf der Ebene der Infrastruktur gemeint ist – also weder ein Cluster, noch VMware-HA-Modelle oder Ähnliches – sondern die eigentlichen Applikationen und die hausintern entwickelte Software. Das bedeutet: Die Softwareentwicklung und der Applikationsarchitekt sind für die Verfügbarkeit der Applikation verantwortlich. Nicht die Infrastruktur.
Entwicklungsteams, die in Richtung dieser Paradigmen neue Applikationen implementieren, verwenden hier mehrheitlich Container-basierte Lösungen verbunden mit Kubernetes. Einer der Vorteile ist, dass es für jeden Applikationsbaustein (Micro Service) ein oder mehrere Container-Images gibt, die von der Entwicklung bis zur Produktion unverändert durchgereicht werden und von denen sehr einfach und effizient beliebig viele Instanzen (identische Kopien) gestartet werden können. Kubernetes übernimmt dabei die Orchestrierung und stellt sicher, dass die gewünschte Anzahl der Kopien und die räumliche Verteilung eingehalten werden.
Das Modell ist wesentlich flexibler und einfacher umzusetzen, als dies auf der Ebene der Virtualisierung möglich ist.
Zusammengefasst lässt sich festhalten:
Unternehmen aller Couleur digitalisieren ihre Produkte und Angebote. Softwareentwickler sind das Öl der Digitalisierung und innerhalb sowie außerhalb der IT eine begehrte und knappe Ressource. Der Bedarf an neuen Lösungen basierend auf agilen Modellen und den oben genannten Paradigmen wächst massiv – und führt zu einem exponentiell steigenden Bedarf nach den technischen Plattformen. Dies ist an der Adaption von Container-Technologien und Kubernetes zu erkennen. Während im Jahr 2015 erste Unternehmen und einzelne Teams in diesem Bereich starteten, ist 2019 fast jeder Kunde von Computacenter in diesem Bereich aktiv und nutzt die Lösungen entweder bereits produktiv oder plant, dies zeitnah umzusetzen.
Auf dem Weg hat sich – was sich auch aus den Use Cases ergibt – Openstack in den allermeisten Fällen nicht durchgesetzt. Derzeit laufen viele Exit-Strategien aus Openstack-Projekten, da die Softwareentwickler in der Praxis direkt auf Container-Technologien aufsetzen und diese Architekturen auch sehr einfach ohne Openstack implementiert werden können.
Dies spiegelt sich in vielen Ankündigungen (Beispiele sind unter anderem Project Pacific von VMware und die IBM Aquise von Red Hat und der Plattform Openshift) und Kundenentscheidungen wider. Kubernetes ist der De-facto-Standard, auf dem Kunden die Plattform für moderne und agile Softwareentwicklung aufsetzen. Dabei sind die Architekturen auf ein hybrides Modell – vom eigenen Rechenzentrum für sensitive Daten bis hin zu Hyperscalern – ausgelegt und bieten eine durchgängige Entwicklungs- und Produktionsplattform.
2019 hat das bereits Kunden dazu veranlasst, eine Container-First-Strategie aufzusetzen, mit denen Cloud-native Applikationen entwickelt und betrieben werden.
Die Welt besteht nicht nur aus Nutztieren. Haustiere werden uns weiterhin begleiten und wir werden auch in den nächsten Jahren Applikationen haben, die noch direkt auf physischen oder virtuellen Systemen laufen werden. Daher wird es – zumindest in den nächsten Jahren – keinen Trend zu einer singulären technischen Plattform geben.
Auch wenn wir dediziert die modernen Container-basierten Applikationen betrachten: Container und Kubernetes sind technische Vehikel wie der Motor im Auto. Um aber für Entwickler und DevOps-Teams die Plattform effizient und wirtschaftlich zu halten, ist die gesamte Architektur – also das ganze Auto – entscheidend. Und wie wir Autofahrer nicht täglich unter die Motorhaube schauen, wollen Entwickler sich oft nicht mit Kubernetes und Containern auseinandersetzen, sondern mit den neuen Business-Applikationen und Lösungen. Somit muss die Strategie deutlich über die technische Plattform hinausgehen.
Computacenter steht Ihnen gern jederzeit bei Fragen und auch für eine Live-Demo zu den neuen Technologien und Best Practices zur Verfügung. Wenden Sie sich bei Interesse einfach an Ihren Ansprechpartner bei Computacenter.