Cloud-basiertes Datenmanagement mit NetApp

Sie möchten Ihre Cloud-Speicherkosten und -Leistung optimieren und gleichzeitig Datenschutz, Sicherheit und Compliance verbessern? In dieseraktuellen Ausgabe unseres Datacenter-Newsletters erfahren Sie, wie Sie das mithilfe von NetApp Cloud Volumes ONTAP schaffen.
Mit der Robotic Process Automation lassen sich Arbeitsaufwand und Kosten der IT-Administration deutlich senken sowie Prozesse automatisieren, für die das früher undenkbar gewesen wäre. Wir stellen Ihnen reale Anwendungsfälle vor, die sich besonders für die robotergesteuerte Prozessautomatisierung eignen.
Wie gelingt eine effiziente und erfolgreiche Migration zu Amazon Web Services? Und welche Cloud-Strategie trägt am meisten zur Modernisierung Ihres Unternehmens bei? Unsere Experten liefern die Antworten.
Lesen Sie außerdem, wie Sie mit Nvidia-Komponenten und der vGPU-Technologie auch performancehungrige Anwendungen im Homeoffice sicher umsetzen können.
Unsere aktuelle Backup-Kolumne befasst sich mit dem Medienbruch im Backup – sowohl mit dem physischen als auch mit dem logischen. Und in unserer Agile-IT-Kolumne erfahren Sie, wie eine Hochverfügbarkeit moderner Cloud-nativer Applikationen erreicht werden kann.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter wurde von NetApp als Converged Partner of the Year 2020 in der EMEA-Region ausgezeichnet. Die Anerkennung in diesem Bereich spiegelt das Engagement und die Innovationskraft im Bereich der Cloud- und Datacenter-Technologien wider.
Weitere InfosComputacenter wurde von der Information Services Group (ISG) in der Studie „Cyber Security – Solutions and Services 2020“ in den Kategorien „Strategic Security Services“ und „Technical Security Services“ in Deutschland als Leader positioniert.
Weitere Infos
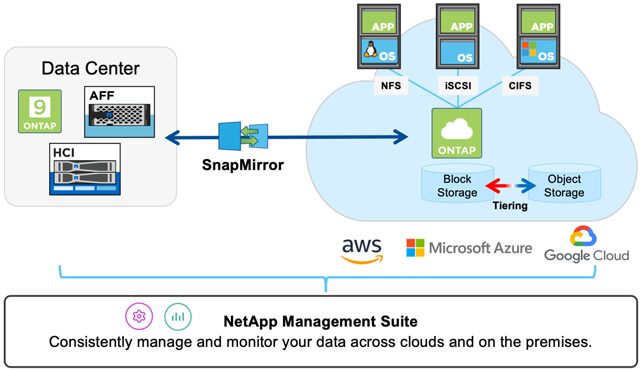
NetApp Cloud Volumes ONTAP (CVO) ist eine universelle Storage-Lösung, die sowohl mit Amazon Web Services (AWS) und Microsoft Azure als auch mit der Google Cloud Platform (GCP) hervorragend zusammenarbeitet. So können Sie Ihre Cloud-Speicherkosten und -Leistung optimieren und gleichzeitig Datenschutz, Sicherheit und Compliance verbessern.
Heutzutage benötigen IT-Abteilungen die flexiblen und effizienten Lösungen, die Cloud-Umgebungen bieten. Bei der schnellen Implementierung von IT-Ressourcen mit unterschiedlichen Auslastungsanforderungen sorgt die Cloud für eine höhere Flexibilität als „On-Premises“-Lösungen. Ressourcen werden nur noch nach Bedarf genutzt.
Die Cloud ist zum Lösungsmodell für Applikationen mit unvorhersehbaren Nutzungsspitzen oder variablen Nutzungsanforderungen geworden – sie ermöglicht die Bereitstellung und Deaktivierung von Ressourcen nach Bedarf.
In Bezug auf Daten ist die Lage etwas komplizierter. Früher unterstützten Daten das Geschäftsmodell, heute sind Daten das Geschäftsmodell. Die Art und Weise, wie Daten genutzt, gemanagt und abgerufen werden, hat sich verändert. Das Verschieben von Daten an einen anderen Ort ist nicht einfach – es wird eine Lösung benötigt, mit der sich die On-Premises- und die Cloud-Ressourcen in einer Oberfläche zusammenführen und managen lassen.
Über die Data Fabric (Verwaltung von Daten in der hybriden Cloud, unabhängig von der Infrastruktur) erzeugen Sie eine zusammenhängende Datenumgebung, die Ihnen unabhängig vom Speicherort die Kontrolle über Ihre Daten ermöglicht.
Public Cloud Provider wie Amazon Web Services (AWS), Microsoft Azure und Google Cloud bieten viele Services, darunter Infrastructure as a Service mit einer schnellen Bereitstellung von Server- und Storage-Ressourcen.
Public Cloud Provider wie Amazon Web Services (AWS), Microsoft Azure und Google Cloud bieten viele Services, darunter Infrastructure as a Service mit einer schnellen Bereitstellung von Server- und Storage-Ressourcen.
Bei der Auswahl sollten Kunden allerdings folgende Fragen bedenken:
NetApp bietet wichtige Funktionen für das Datenmanagement:
Die Datenmanagement-Software NetApp CVO bietet Kontrolle, Schutz, Flexibilität und Effizienz für Unternehmensdaten in der gewünschten Cloud. CVO basiert auf dem weltweit am meisten eingesetzten Storage-Betriebssystem ONTAP – der universellen Storage-Plattform, die Datacenter und Cloud integriert.
Kunden nutzen CVO für unterschiedlichste Use Cases, immer mit dem Fokus auf:
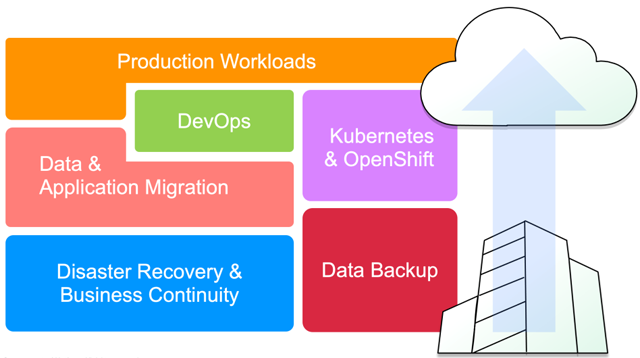
CVO bietet eine Daten-Storage-Lösung für viele unterschiedliche Workloads wie Disaster Recovery, Entwicklungs- und Testumgebungen bis hin zu cloudbasierten Applikationen, die einen hochverfügbaren, unterbrechungsfreien Betrieb erfordern, wie beispielsweise Business-Applikationen für die Produktion und Fileservices.
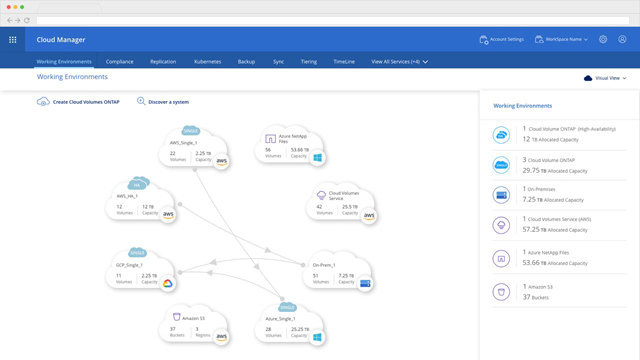
Die kostenfreie Cloud Manager Software ist eine zentrale Managementumgebung für ONTAP-basierte Dienste. Das Tool unterstützt Kunden bei der Installation, Ressourcenzuweisung und Provisionierung von Daten im täglichen Betrieb und automatisiert das Verschieben von Daten in die und aus der Cloud.
Die Lösung bietet einen Überblick über die von den einzelnen Cloud-Volumes-ONTAP-Instanzen genutzten Ressourcen und Kosten. Anhand dieser Informationen können Sie die kostengünstigste Umgebung ermitteln und entscheiden, wann der Zeitpunkt gekommen ist, Workloads zu verschieben. Die wichtigsten Vorteile von Cloud Manager im Überblick:
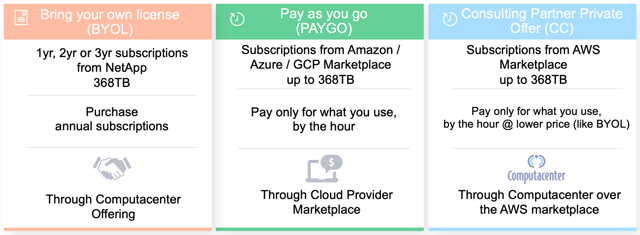
Cloud Volumes ONTAP bietet zwei Storage-Verbrauchsmodelle:
Nutzungsbasiertes Modell:
Beim nutzungsbasierten Modell kann Storage direkt aus dem Marketplace des Cloud Providers erworben werden. Die Abrechnung erfolgt auf Stundenbasis. Das Nutzungsmodell ist insbesondere für kurzfristige Applikationsanforderungen beziehungsweise Umgebungen geeignet, die nach Bedarf erweitert oder reduziert werden müssen.
BYOL-Modell:
Das Bring-Your-Own-License-Modell (BYOL) ist eine von NetApp erworbene Lizenz. Diese wird in Ihrer Cloud-Volumes-ONTAP-Instanz installiert. BYOL-Abonnements können für einen Zeitraum von einem Jahr, zwei oder drei Jahren erworben werden. Für deterministischere Applikationen beziehungsweise Applikationen, die über einen längeren Zeitraum genutzt werden, bietet sich das Abonnementmodell an.
Jedes Verbrauchsmodell bietet diverse Optionen, zum Beispiel eine kleinere nutzungsbasierte Lösung mit 2 TB oder ein größeres Abonnementmodell mit bis zu 368 TB Bruttokapazität.
Computacenter kann Ihnen je nach Anforderungsprofil das passende Verbrauchsmodell anbieten – im AWS Marketplace gibt es zusätzlich die Möglichkeit, den kaufmännischen Vorteil des BYOL-Modells mit der Flexibilität des nutzungsbasierten Modells in einer Consulting Partner Private Offer (CPPO) zu verbinden.
Selbstverständlich können sie aus allen Preismodellen wählen, von kostenfreien Testversionen, Abrechnungen auf Stunden-, Monats-, Jahres-, Mehrjahres- und BYOL-Basis, von Pay-per-Use bis hin zu langfristigen Nutzungsverträgen.
Computacenter kann für Sie den optimalen Preis erzielen, indem wir NetApp-Produkte als sogenannte „Private Offer“ in den AWS Marketplace einstellen. Und wenn Sie noch viele andere Lösungen vom AWS Marketplace verwenden möchten, richten wir für Sie einen kompletten „Private Marketplace“ ein, in dem sie die zentrale Kontrolle über die Nutzung der Angebote haben.
NetApp bietet eine Vielzahl an Optionen zur Ermittlung der geeignetsten Infrastruktur für Ihre Applikations- oder Geschäftsanforderungen. Diese reichen von On-Premises-Umgebungen mit All Flash FAS und softwaredefiniertem ONTAP Select Storage bis hin zu Cloud-Umgebungen mit Cloud Volumes ONTAP Software.
NetApp bringt die Einfachheit und Flexibilität der Cloud in Ihr Datacenter und Ihre Unternehmensdaten und Apps in die Public Cloud.
Mit Computacenter haben Sie einen Lösungspartner, der Sie bei Ihren Aufgaben und Herausforderungen in hybriden Architekturen berät, die Lösungen implementiert und auch betreut. Außerdem können Sie NetApp-Produkte über Computacenter zu attraktiven Konditionen beziehen.
Haben wir Ihr Interesse geweckt? Dann schauen Sie doch einmal unter https://cloud.netapp.com/ontap-cloud vorbei.
Sie möchten nicht nur Ihre Storage-Ressourcen in der Public Cloud optimieren, sondern auch Ihre Compute-Ressourcen? Auch dafür haben wir mit „SPOT by NetApp“ eine Lösung, mit der Sie im Durchschnitt mehr als 70
Prozent Ihrer laufenden Cloud-Kosten einsparen können: https://spot.io/
Selbstverständlich stehen Ihnen Ihre Ansprechpartner bei Computacenter und bei NetApp zur Verfügung – gern auch für eine Live-Demo. Kommen Sie einfach auf uns zu.

Bei der IT-Automatisierung geht es darum, mithilfe von Softwaretools wiederkehrende IT-Aufgaben zu verwalten – mit nur minimalem Eingriff seitens der IT-Administratoren. Diese können sich somit anderen Aufgaben widmen, statt Routinejobs zu erledigen. Mit der Robotic Process Automation lassen sich Arbeitsaufwand und Kosten nochmals deutlich senken sowie weitere Prozesse automatisieren, für die das früher undenkbar gewesen wäre.
Die Robotic Process Automation (RPA, zu Deutsch: robotergesteuerte Prozessautomatisierung) hilft dabei, die Wirtschaftlichkeit sämtlicher Prozesse und zugehöriger Tasks und somit letztlich auch des Unternehmens zu steigern. Das erreicht sie, indem sie die kostspieligsten Phasen der Bereitstellung, des Designs und der Entwicklung sowie der Wartung von IT-Prozessen vereinfacht. Zu diesem Zweck werden verschiedene Ansätze verfolgt, beispielsweise die Vereinfachung der RPA-Programmierung (gemäß der RPA-Tendenz Low Code) oder die Entwicklung des Selbstlernens und der kognitiven Automatisierung.
Durch die Nutzung von Process Mining, Task Mining, der Verarbeitung natürlicher Sprache (NLP), der optischen Zeichenerkennung (OCR) und des maschinellen Lernens wird die Kategorie der automatisierbaren Prozesse und Tasks erweitert. Die RPA-Anwendungsbereiche werden über Supportfunktionen hinaus auf komplexere Vorgänge wie End-to-End-Kundendienst mit Chatbots, Durchführung von KYC-Überprüfungen (Know Your Customer) über handschriftliche Kundeneingaben oder gescannte Dokumente erweitert.
Da RPA immer intelligenter, ausgefeilter und breiter anwendbar wird, wird sie auch zur Verbesserung des Leistungsniveaus von IT-Abteilungen eingesetzt. Die robotergesteuerte Prozessautomatisierung wird somit den IT-Betrieb im Laufe der Zeit verändern.
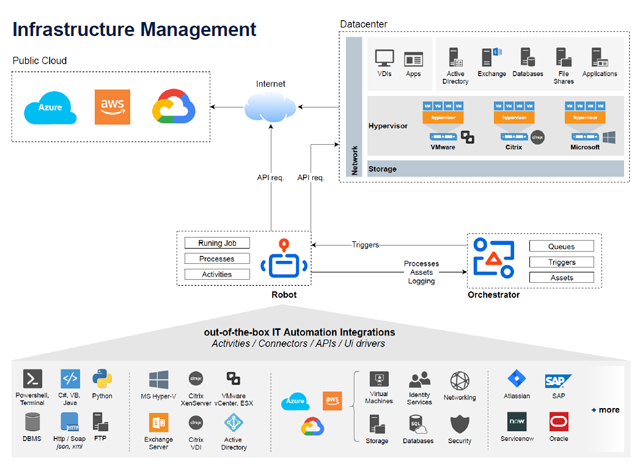
Die Verwendung von RPA zur Änderung des IT-Betriebs führt zu einer Steigerung der Prozessqualität, einer Verkürzung der Servicebereitstellungszeit und Wiederherstellungszeit, zu einer Steigerung der Produktivität der IT-Ressourcen und infolge all dieser Maßnahmen zu einer allgemeinen Verbesserung der betrieblichen Effizienz. In der folgenden Liste finden Sie sowohl Back- als auch Front-End-Prozesse.
1. Backup- und Patch-Management
Dies sind routinemäßige, sich wiederholende Aufgaben, die eine sorgfältige Behandlung erfordern, ohne dass sie Mitarbeitern, die sie manuell ausführen, ein Gefühl der Erfüllung oder Arbeitszufriedenheit verschaffen (häufig im Gegenteil!). Ihr Unternehmen kann jedoch nicht ohne sie auskommen. Dies ist also eine typische Art von Prozess, der von den Schultern der Mitarbeiter entfernt und der RPA-Technologie zugewiesen werden kann.
3. Benutzerverwaltung
Durch die Nutzung von Bots in der IT-Abteilung für Aktivitäten wie beispielsweise die Kontoerstellung oder die Erstellung von E-Mail-Adressen werden die Vorteile in die Personalabteilung übertragen. Besonders bei der Übernahme von Unternehmen oder der Neueinführung von Anwendungen und der zugehörigen Benutzerkonfiguration können diese Vorteile voll ausgespielt werden. Nach dem Sammeln von Benutzerprofilinformationen für die Kontoerstellung können Softwareroboter, die mit Zugriff auf das ITSM-Tool ausgestattet sind, diese gemäß den HR-Vorlagen strukturierten Informationen verwenden und eine Serviceanforderung zur Benutzeranlage generieren.
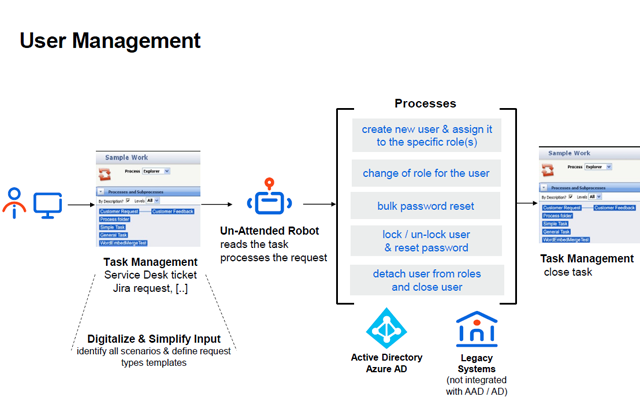
Das tägliche manuelle Senden von Hunderten von E-Mail-Benachrichtigungen kann den Workflow ernsthaft stören. Das Gute an den Benutzerbenachrichtigungsprozessen ist, dass sie mithilfe vorgegebener Regeln ausgeführt werden, die auf strukturierte Informationen angewendet werden. Daher ist eine End-to-End-Automatisierung (über unbeaufsichtigte Roboter) eine praktikable Option.
Ein Taskplaner kann einen Bot dazu veranlassen, sich beim ITSM-Tool anzumelden, um die ausstehenden Fälle zu erfassen und die erforderlichen Berichte auszuführen (beispielsweise E-Mails senden, die auf Benutzereinstellungen zugeschnitten sind, Überwachungsberichte senden, Ticketstatus aktualisieren). Wie in den vorherigen Anwendungsfällen werden Ausnahmen, wenn sie auftreten, an Service-Desk-Mitarbeiter gesendet, oder sogar sofort gelöst. Die Automatisierung verkürzt die Verarbeitungszeiten, verbessert die Servicequalität und ermöglicht es den Mitarbeitern, sich auf höherwertige Aufgaben zu konzentrieren.
5. Incident Management
Nicht alle Incidents erfordern menschliches Eingreifen von Experten. Mit einem automatisierten Diagnosedienst können Softwareroboter die Probleme auswählen, die mithilfe einfacher, regelbasierter Algorithmen behoben werden können, und nur diejenigen an Fachexperten weiterleiten, die komplexere Entscheidungen erfordern. Angesichts der Verfügbarkeit virtueller IT-Mitarbeiter rund um die Uhr reduziert die Automatisierung die durchschnittliche Lösungszeit und die Reaktionszeiten erheblich und erhöht so die Kundenzufriedenheit.
6. Netzwerkunterstützung
Netzwerktechnologien wie Load Balancer oder Firewalls erfordern eine ständige Überwachung und Messung. Softwareroboter können die Netzwerkleistung verwalten und sofortige Updates und Optimierungen ausführen, wenn sich Verbesserungsmöglichkeiten ergeben. Ihre konsistenten, dauerhaften und fehlerfreien Betriebsmodi stellen sicher, dass in der IT-Automatisierung alle Vorteile der Netzwerkoptimierung genutzt werden.
7. Softwareinstallationen
RPA bietet die Möglichkeit, selbst komplexe Systeme mit miteinander verbundenen Bestandteilen durch die grundlegendsten Aktionen mit nur einem Klick zu installieren. Mit der IT-Automatisierung sind wir also buchstäblich nur einen Klick von der Softwareinstallation entfernt.
8. Überwachung der Benutzererfahrung
Die Automatisierung dieses Prozesses wird durch die Tatsache ermöglicht, dass RPA menschliches Verhalten nachahmt. Da Bots die Erfahrungen von Mitarbeitern und Kunden simulieren können, ermöglichen sie kontrollierte Tests von Softwareanwendungen. Die direkten Nutznießer sind die Kunden, deren Benutzererfahrung verbessert wird und die von der qualitätsgesicherten Bereitstellung neuer Softwareversionen profitieren. Dies wird sich zum Vorteil des Unternehmens auswirken, das langfristig Gewinne erzielen und seinen guten, personenzentrierten Ruf festigen wird.
Haben Sie Fragen zu IT-Automatisierung im Allgemeinen oder zu Robotic Process Automation im Speziellen? Die Experten bei Computacenter beraten Sie gern. Melden Sie sich am besten gleich bei Ihrem Ansprechpartner.

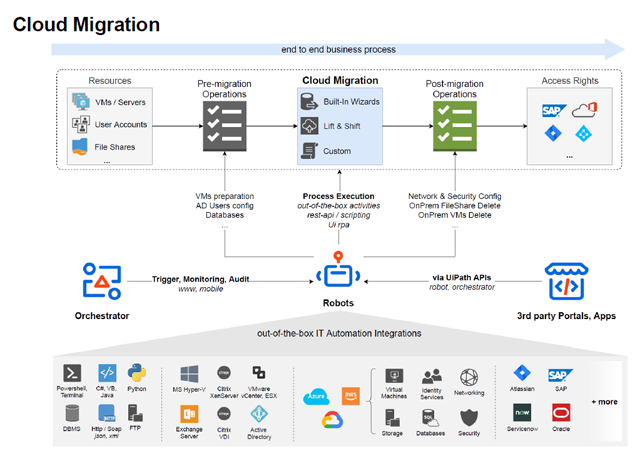
Die Vorteile der Cloud sind inzwischen wohlbekannt. Doch wie lassen sich Applikationen am besten in die Cloud migrieren? Welche Strategie trägt am meisten zur Modernisierung des Unternehmens bei? Und wie können Sie sicherstellen, dass die Maßnahmen erfolgreich zu Ende geführt werden? Computacenter liefert die Antworten und begleitet Sie auf Wunsch bei jedem Schritt.
Es gibt viele Gründe dafür, Anwendungen in die Cloud zu migrieren. Die daraus resultierenden Kostensenkungen sind für die meisten Unternehmen verlockend genug. Die Entscheidung zugunsten effizienterer Cloud-Lösungen eröffnet jedoch nicht nur die Möglichkeit, Kosten einzusparen, sondern erlaubt ein höheres Maß an geschäftlicher Agilität. Die Steigerung der Mitarbeiterproduktivität und der operativen Belastbarkeit gelten als die wahren Werte, die eine Cloud nachhaltig liefern kann. Die Cloud verändert die Art und Weise, wie Fachabteilungen und ganze Unternehmen geführt werden, und gilt als Wegbereiter für Unternehmen, global zu werden, neue Produkte auf den Markt zu bringen und Geschäftsprozesse zu modernisieren.
Um alle Vorteile einer Cloud-Migration zu nutzen, ist ein gewisser Zeit- und Arbeitsaufwand erforderlich. Doch niemand muss mehr bei null starten. Von den Erfahrungen der Unternehmen, die diesen Weg bereits beschritten haben, lassen sich mehrere Erfolgsprinzipien und Best Practices für eine Migration ableiten.
Der Umzug in die Cloud ist eine große Veränderung und im Geschäftsleben bleiben große Veränderungen nur bestehen, wenn sie unterstützt werden durch feste Verpflichtungen in den Führungsebenen. Das Buy-in aller Schlüsselpersonen ermöglicht einen erfolgreichen Start in das Projekt und verringert das Risiko, dass Ergebnisse nicht den Erwartungen entsprechen. Um das Buy-in für die Cloud-Migration zu fördern, identifizieren wir stets konkrete Ziele mit den Kunden, sodass jeder in der Organisation Unterstützung leisten kann. Konkrete Benchmarks und ein konzentrierter Fokus ermöglichen es Unternehmen, nicht mehr nur über Migration zu sprechen, sondern diese auch wirklich umzusetzen!
Unternehmen müssen vor allem auch intern beweisen, dass sich die Reise in die Cloud lohnt. Beginnen Sie deshalb mit der Identifizierung einer oder mehrerer Anwendungen, die sich schnell und einfach migrieren lassen und Ihrem Unternehmen dadurch sichtbare Vorteile bieten.
Mobilisieren Sie nach frühen Erfolgsgeschichten Ihre Organisation mit einem detaillierten Migrationsplan und einem verfeinerten Business Case. In dieser Phase werden Sie Lücken in der Cloud Readiness Ihres Unternehmens aufdecken, den Schwerpunkt auf die Erstellung einer Baseline in der Cloud (Landing Zone) legen und die Entwicklung Ihrer Cloud-Fähigkeiten erweitern. Bedenken Sie: Gute Cloud-Kenntnisse sind rar und sehr gefragt. Der bewährte Ansatz besteht darin, sowohl Ihr Team schnell und effizient zu qualifizieren als auch externe Unterstützung durch ausgezeichnete Partner zu integrieren. Dadurch vermeiden Sie Verzögerungen im Prozess und erhalten das Momentum zum Erreichen Ihrer Ziele aufrecht.
Es gibt mehrere Möglichkeiten, eine Applikation zu migrieren. Dennoch folgen Migrationen normalerweise einem von sieben Grundmustern, bekannt als die 7 Rs von AWS. Gern erarbeiten wir bei Computacenter gemeinsam mit Ihnen eine detaillierte Strategie, um für jede Ihrer Applikationen das beste Migrationsmuster zu definieren und die Modernisierung Ihrer Unternehmens-IT schrittweise zu fördern.
Computacenter hilft bei der Neugestaltung (Refactor) von Applikationen und unterstützt beim Aufbau zeitgemäßer Entwicklungstechnologien wie Serverless Computing, Microservices, Containern und CI/CD-Pipeline mit integriertem Security Testing (DevSecOps). Auch im Bereich des Lizenzmanagements beraten wir Kunden auf ihrem Weg in die Cloud und helfen, die richtigen third-party und SaaS-Lösungen auszuwählen und effizient einzukaufen.
Sprechen Sie uns an, wenn Sie die Vorteile der Public Cloud nutzen möchten und eine umfassende Lösung für Ihren Weg in die Cloud suchen. Wir bieten Ihnen konkrete Antworten.

Aufgrund der Corona-Pandemie boomt das Arbeiten im Homeoffice. Damit sind jedoch große Herausforderungen an die Technik verbunden: Die Mitarbeiter sollen voll arbeitsfähig sein und auch die Kommunikation mit Kollegen und Kunden soll störungsfrei funktionieren – und das alles mit der nötigen Sicherheit für das Unternehmensnetzwerk. Mit Nvidia-Komponenten und der vGPU-Technologie lassen sich auch performancehungrige Anwendungen sicher umsetzen.
In Zeiten der Pandemie arbeiten sehr viele Leute von zu Hause aus. Zahlreiche Unternehmen wurden von der Homeoffice-Thematik jedoch völlig überrascht. Bei einigen unserer Kunden war es praktisch unmöglich, von zu Hause oder von unterwegs aus zu arbeiten. Jeder Mitarbeiter hatte einen stationären Desktop-PC im Büro und es gab keine Remote-Einwahlmöglichkeiten. Bei einigen Kunden war es aufgrund von politischen Entscheidungen nicht möglich, vom Homeoffice aus zu arbeiten. Dann kam Corona …
Wie kann man in einer solchen Lage schnell und problemlos eine große Menge Remote Desktops ausrollen und den verschiedenen Leistungsanforderungen gerecht werden? Bei vielen Kunden wurden Virtual-Desktop-Infrastructure(VDI)-Projekte aus dem Boden gestampft. Natürlich kann man sehr schnell virtuelle Maschinen mit Windows 10 betanken und dann kann es losgehen – aber sind diese Maschinen dann auch so leistungsstark wie der PC im Büro? Die Herausforderungen heutzutage lauten immer seltener nur „Office-Tätigkeiten“. Bei vielen gehören zum täglichen Arbeiten auch Internetrecherchen, Videos anschauen, Podcasts anhören, Blogs schreiben und so weiter.
Wenn man im Homeoffice arbeitet, ist die Kommunikation mit Kollegen und Kunden der entscheidende Punkt! Immer seltener greifen Mitarbeiter zum Telefon. Collaboration-Plattformen werden immer häufiger zum zentralen Arbeitsmittel. Audio Calls sind bei vielen Kunden das höchste der Gefühle, Videokonferenzen praktisch undenkbar. Aber warum eigentlich?
Was brauchen wir, um diese Anforderungen erfüllen zu können? Wir wollen von überall arbeiten, wann wir wollen / können / dürfen und von jedem Gerät aus. Wer möchte denn neben seinem Privatgerät noch einen weiteren PC im heimischen Büro aufbauen müssen? Warum nicht vom privaten Rechner oder Tablet auf den virtuellen Desktop im Unternehmen zugreifen? Ohne VPN, ohne Sicherheitsbedenken, ohne Schnickschnack! Aber trotzdem mit voller Leistung, mit Skype, Web-Ex, Teams und Zoom!
Wie das gehen soll? Mit Nvidia und der vGPU-Technologie! Dafür werden in die VMware ESXi Server im Rechenzentrum Grafikkarten von Nvidia verbaut und diese dann aus den virtuellen Desktops angesprochen. Das klingt zu einfach? Dann mal langsam und Schritt für Schritt:
Für den Betrieb von VDI oder Terminalservern werden spezielle Datacenter-GPUs von Nvidia benötigt, die sogenannten Karten der Tesla-Serie. Diese sind für den Einsatz im Rechenzentrum konstruiert worden und je nach Einsatzspektrum gibt es verschiedene Modelle: Nvidia M10, T4, V100 oder RTX GPUs. Die Nvidia M10 GPU beispielsweise ist eine Doppelslot-Karte mit 4 GPUs und insgesamt 32 GB dediziertem Grafikspeicher. Dieser Grafikspeicher, auch Frame Buffer genannt, kann später von den virtuellen Maschinen angesprochen werden.
Aber so weit sind wir noch nicht: Nachdem die passenden GPUs in den Servern verbaut wurden, müssen die dazugehörigen Host-Treiber installiert werden. Diese stellt Nvidia für nahezu allen aktuellen Hypervisor zur Verfügung. Anschließend werden die GPUs für den passenden Modus konfiguriert. In unserem Fall: Virtualization Mode mit vGPU. Als Nächstes wird der beziehungsweise werden die beiden Nvidia-Lizenzserver installiert. Dies kann entweder ein Windows- oder ein Linux-System sein.
Darauf wird OpenJDK installiert und im Anschluss daran der Flexnet-basierte Nvidia-Lizenzserver. Die MAC-Adressen dieser Lizenzserver müssen bei Nvidia im Lizenzportal eingetragen werden, damit die Lizenzen für die vGPU-Nutzung darauf erstellt werden können. Jeder gestartete virtuelle Desktop, der sich am Lizenzserver meldet, erhält eine vGPU-Lizenz. Es gibt verschiedene Arten von vGPU-Lizenzen, je nachdem, wie viel GPU-Leistung (FrameBuffer, Anzahl der Monitore oder die Auflösung 4K, 5K und 8K) benötigt wird. Dazu bekommt jede virtuelle Maschine im Hypervisor ein Nvidia-vGPU-Profil zugewiesen.
Zum Abschluss muss nur noch der Nvidia-Grafikkartentreiber innerhalb der Windows-10-VM installiert werden. Nun haben wir eine VDI VM, die einen Teil einer echten High-Performance-GPU im Server verwendet. Damit können die Benutzer alle Arten von Multimedia-Inhalten nutzen, an Videokonferenzen teilnehmen und haben das Gefühl, an einem vollwertigen Arbeitsplatz zu sitzen, nur eben virtuell. Und das von überall, wann immer sie wollen und an jedem Endgerät.
Haben wir Sie neugierig gemacht? Möchten Sie das Thema vGPU konkret für Ihre Umgebung betrachten? Kommen Sie auf uns zu und wir vereinbaren eine Remote Session (natürlich aus einer Nvidia vGPU VDI VM) und wir zeigen Ihnen gern das gesamte Potenzial. Soll es ein PoC-Projekt werden? Kein Problem! Wir können Ihnen auch Leih-GPUs von Nvidia zur Verfügung stellen.

Seit Jahren kommt in vielen Backup-Gesprächen mit Kunden der Begriff des Medienbruchs auf. Oft wird postuliert, dass ein Medienbruch wichtig sei. Was aber ist überhaupt ein Medienbruch und existieren dazu konkrete Vorgaben?
Recherche beginnt oft mit einer Internetsuche. Wikipedia sagt zum Thema Medienbruch als Sicherheitselement (das Backup soll ja die Daten gegen Verlust und Beschädigung schützen), dass ein virtueller oder physischer Medienbruch möglich sei. Dabei werden getrennte Geräte (physisch) oder Kanäle (virtuell) genutzt. Ein Beispiel dazu ist ein Smartphone und getrennt davon ein Gerät für die Sicherheitscodes.
Allerdings wird an dieser Stelle kein Bezug auf das Thema Backup/Restore genommen, sodass wir als Nächstes den Bitkom-Leitfaden zum Thema Backup/Recovery aus dem Jahr 2016 heranziehen.
Hier wird der Begriff Medienbruch, unterteilt nach logischem und physischem Medienbruch, aufgeführt – aber es steht keine klare Definition zur Verfügung. Und weitere Quellen (NIST 800.53, ISO 27001, BSI IT-Grundschutzkompendium 2020) greifen den Begriff Medienbruch nicht auf.
Damit basiert die folgende Auslegung des Begriffs Medienbruch auf Gesprächen mit Kunden und Anbietern von Backup-Lösungen.
Zugegeben, diese Auslegungen werfen weitere Fragen auf. Sind getrennte Medien verschiedene Speichermedien in einem Storage-System, zwei Speichersysteme eines Herstellers in zwei Brandbereichen oder Lösungen verschiedener Hersteller in zwei Brandbereichen?
So lautet die Überschrift zu dem Punkt CON.3.A12 aus dem IT-Grundschutzkompendium des BSI. Darin findet sich die Anforderung, dass die Backup-Datenträger räumlich getrennt aufbewahrt werden sollen. In den Umsetzungshinweisen des BSI wird diese Anforderung noch einmal verschärft. Dort heißt es, die Backup-Datenträger müssen räumlich getrennt und, wenn möglich, in einem anderen Brandbereich aufbewahrt werden.
Analoge Definitionen finden sich beispielsweise in der NIST 800.53 CP.9.
Bezogen auf die eingangs geführte Diskussion zum Thema Medienbruch kann festgehalten werden, dass die Backup-Datenträger brandtechnisch getrennt von den Primärdaten vorgehalten werden müssen. Das ist auch in unseren Projekten sowie in den Kundengesprächen und den Empfehlungen der Anbieter von Backup-Lösungen üblicherweise der Konsens.
Die Ablage der Backup-Daten erfolgt grundsätzlich auf getrennten Geräten und Medien, die in einem anderen Brandabschnitt zu den Primärdaten aufgestellt sind.
Der physische Medienbruch
Es liegt nahe, die Daten zwischen den beiden Brandbereichen synchron oder annähernd synchron zu spiegeln. Dann stehen die Primärdateien zum einen auf dem normalen Fileserver und zum anderen als Kopie in einem zweiten Brandbereich zur Verfügung. Versehen mit einer Versionierung (Backups stellen verschiedene Versionen für einen Restore auch älterer Stände bereit), die technisch beispielsweise über Speicher-Snapshots umgesetzt werden, wäre damit die Anforderung erfüllt.
Allerdings merkt das BSI in den Umsetzungshinweisen eindeutig an, dass eine solche Datenspiegelung keinen Backup darstellt. Inkonsistenzen und logische Fehler werden durch die Spiegelung unmittelbar übertragen und gefährden die Integrität und Verfügbarkeit der Backup-Datenträger.
Also muss eine Trennung der Backup-Datenträger von einem gespiegelten Speichersystem erfolgen. Ein Medienbruch für den Backup-Datenträger besteht dann in der Speicherung der Backup-Daten auf einem vom Primärspeicher und von den gespiegelten Instanzen des Primärspeichers unabhängigen System in einem von den Primärdaten getrennten Brandbereich.
Bedeutet das zwangsläufig, dass Lösungen getrennter Hersteller oder explizit Bandmedien zum Einsatz kommen müssen?
Basierend auf den Aussagen in den Dokumenten des BSI, NIST und der ISO ist diese Schlussfolgerung nicht nachvollziehbar, denn sie wird nicht vorgegeben. Aber es ist eine verbreitete Interpretation, dass ein Medienbruch das Beschreiben von Bandmedien mit dem Backup erfordert. Während die Verwendung von Bandmedien als Offline-Kopie im Kontext Ransomware- oder Desaster-Recovery-Vorsorge durchaus sinnvoll sein kann, geben die aufgeführten Quellen sie jedoch nicht vor. Daher ist sie nicht zwingend erforderlich.
Der logische Medienbruch
Wenn anstelle der im vorherigen Abschnitt aufgeführten Spiegelung ein Replikationsverfahren genutzt wird, welches die Backup-Daten auf ein getrenntes Speichersystem schreibt und keine Abhängigkeiten zu dem Spiegelungsverfahren der Primärspeicherumgebung aufweist, dann kann dies als logischer Medienbruch ausgelegt werden.
Tatsächlich werden solche Verfahren in der Praxis gerade bei großen Datenbeständen verwendet. Mittlerweile haben viele Kunden dateibasiert Petabyte an Daten als File Services auf Network-Attached-Storage(NAS)-Systemen abgelegt. Das Übertragen dieser Daten auf Backup-Medien (Band, Deduplication Appliances) sowie ein Restore der Daten ist in Bezug auf Kosten und Zeitdauer aufwendig und Restores von mehreren Hundert Terabyte würden Wochen dauern.
Speziell in diesen Umgebungen, aber auch bei sehr großen Datenbanken, ergänzen oder ersetzen speicherbasierte Verfahren und ein logischer Medienbruch die Backup-Strategien.
Voraussetzung für solche Backup-Strategien müssen organisatorische und technische Schutzmaßnahmen sein, die beispielsweise ein Vier-Augen-Prinzip und eine strikte Trennung der Administration von Primär- und Backup-Daten umsetzen. Backups werden zunehmend das erste Angriffsziel von Ransomware-Attacken (Beispiel) und haben somit einen erhöhten Schutzbedarf.
Diese Kolumne greift aktuelle Kundenprojekte auf, in denen die beschriebenen Inhalte aktiv angegangen werden. Und zwar nicht im Kontext der zentralen Datensicherung – welche in vielen Fällen die Kriterien und Definitionen berücksichtigen –, sondern im Kontext der parallelen Backup-Workflows, die in allen Unternehmen existieren (siehe letzte Backup-Kolumne).
In Interviews und Workshops werden immer auch Backups erfasst, welche die Anforderungen der geeigneten Aufbewahrung von Backup-Datenträgern nicht erfüllen. Daher ist es sinnvoll und wichtig, hierauf das Augenmerk zu richten und die Sicherheit der Unternehmensdaten und von personenbezogenen Daten über klar definierte, implementierte und getestete Backups umzusetzen.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zum Datenmanagement und zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

Zunehmend entwickeln und betreiben Unternehmen moderne Applikationen basierend auf Cloud-nativen Applikationsprinzipien. Darüber hinaus kommen agile Prozesse sowie Container und Kubernetes als Technologien zum Einsatz. Mit dem Übergang in die Produktion muss eine Hochverfügbarkeit erreicht werden. Wir erklären, wie das gelingt.
Hochverfügbarkeit (HA aus dem Englischen für High Availability) und Desaster-Recovery(DR)-Fähigkeit sind Disziplinen, die jedes regulierte Unternehmen beherrscht und in regelmäßigen DR- und Wiederherstellungstests nachweisen muss. Dazu werden jährlich Testszenarien durchgespielt und dokumentiert, wie es die BaFin beispielsweise bei Banken und Versicherungen explizit fordert.
Für etablierte IT-Systeme und Applikationen sind der Service HA/DR und Aufgaben wie
primär im Infrastruktur-Betrieb angesiedelt. Es kommen Technologien wie Datenspiegelung, Cluster-Lösungen und Verfahren wie beispielsweise VMware HA zum Einsatz, um die Verfügbarkeit der Applikationen sicherzustellen.
Entwicklungsteams nutzen gern Technologien wie Kubernetes und Container sowie Function as a Service (FaaS oder Serverless), welche technologisch auch Container für eine Ausführung der Algorithmen nutzen. Diesen Technologien ist es zu eigen, dass ein Design-to-Fail-Prinzip umgesetzt wird.
Betrachten wie hierzu Kubernetes als die etablierte Lösung zur Orchestrierung von Containern. Selbstverständlich wird Kubernetes für unternehmenswichtige Applikationen hochverfügbar implementiert und betrieben. Allerdings besteht das Designprinzip darin, dass Kubernetes den gewünschten Zustand – auf Englisch: Desired State – nach einer Störung wiederherstellt. Das heißt, die Störung darf eintreten (Ausfall einer Server- oder VM-Instanz oder eines Brandbereichs) und Kubernetes orchestriert die verbleibenden Ressourcen, um den gewünschten Zustand wieder zu erreichen.
Für die Applikation erfordert dies eine Scale-out-Architektur als Cloud-natives Applikations-Kriterium, bei der mehrere Instanzen der Applikation und derer Bausteine (im Kontext Micro-Service-Modelle) auf getrennten Servern und Brandbereichen verteilt sind.
Da die Entwicklung und das sogenannte Deployment der Applikationen die Aufgabe der Applikationsteams und der Entwickler sind, wird die Verfügbarkeit zur Eigenschaft der Applikation – unter Nutzung der Wiederherstellungsmechanismen von Kubernetes nach einer Störung. Das bedeutet eine enge Abstimmung der Applikationsteams mit dem Plattformteam für die Cloud-native Applikationsumgebung.
Moderne Anwendungen, die auf Cloud-nativen Prinzipien basieren, implementieren unter Nutzung von Abstraktionsebenen wie Kubernetes eine HA/DR-Fähigkeit als Bestandteil der Applikationen. Das Applikations- und das Plattformteam stellen betrieblich die HA/DR-Fähigkeit sicher. Was wird also von der seitens der Infrastruktur-Services implementierten HA/DR-Fähigkeit verwendet?
Exakt diese Frage sollte beim Aufbau einer technischen Plattform und beim Aufsetzen der Betriebsprozesse beantwortet und klar formuliert werden. Die möglichen Antworten sind vielfältig und hängen von unternehmensspezifischen Anforderungen und Gegebenheiten ab.
Exemplarisch soll ein technischer Punkt diese Diskussion veranschaulichen. Typischerweise werden in Deutschland kritische Daten über zwei räumlich getrennte Brandbereiche (Erreichen der Betriebsredundanz) gespiegelt. Kubernetes, welches selbst nach Cloud-nativen Prinzipien aufgebaut ist, nutzt eine zentrale Komponente für den laufenden Betrieb – den Key/Value-Store etcd. Etcd verwendet ein integriertes Replikationsverfahren (Latenz < 5 ms) und nutzt drei Instanzen, um jeweils über eine Mehrheit (Quorum) die Funktionalität sicherzustellen.
Konsequent wäre erstens, dass etcd nicht den synchron gespiegelten Storage nutzt, da es bereits auf Applikationsebene Daten spiegelt. Zweitens, dass die drei Instanzen sinnvollerweise in drei Rechenzentren oder Verfügbarkeitszonen verteilt sind.
Diese und weitere Fragestellungen treten grundsätzlich in Projekten auf, wo wahlweise containerbasierte Infrastrukturen oder Cloud-native Applikationsplattformen implementiert werden. Daraus sollten sich Architekturvorgaben für moderne Applikationen sowie Testkriterien und Regeln ergeben.
Wichtig dabei ist: Cloud-native setzt keinen Hyperscaler voraus, da es ein Architekturprinzip ist. Damit können Cloud-native Applikationen auch in Rechenzentren der Unternehmen betrieben werden.
Aber hier müssen die Cloud-nativen Anforderungen (elastisches Scale-out, dynamisches Starten und Stoppen von Applikationen je nach Arbeitslast, sofortiges Provisionieren von Ressourcen über API und Automation und so weiter) im Rechenzentrum umgesetzt werden. Diese Hürde ist gerade in etablierten Organisationen sehr komplex – und keine technische Herausforderung.
Computacenter unterstützt Sie gern dabei, die passenden Antworten auf diese und weitere Fragen zu finden und anschließend eine auf Sie zugeschnittene Architektur für die modernen Cloud-nativen Applikationen zu etablieren, umzusetzen und zu betreiben. Wenden Sie sich bei Interesse einfach an Ihren Ansprechpartner bei Computacenter.