HPE Synergy im Computacenter Solution Center Ratingen

Sehr geehrte Damen und Herren,
mit HPE Synergy lassen sich eine ganze Reihe brennender Themen von IT-Verantwortlichen adressieren – von Big Data über die E-Akte aus der Cloud bis hin zum Betrieb von SAP HANA. In dieser Ausgabe stellen wir Ihnen die verschiedenen Szenarien vor, die Sie sich übrigens in unserem HPE Solution Center in Ratingen live zeigen lassen können.
Die weltweit gespeicherte Datenmenge wächst rasant, da können die bisherigen traditionellen Speichertechnologien nicht mithalten. Eine Lösung könnte Object Storage sein. Lesen Sie, wie diese Speicherarchitektur funktioniert und welche Anwendungsszenarien perfekt dazu passen.
Haben Sie die Datenschutz-Grundverordnung der Europäischen Union (EU-DSGVO) bereits umgesetzt? Nicht vergessen: Stichtag ist der 25. Mai. Inwiefern Sie dabei auch die Kopien von personenbezogenen Daten im Blick behalten müssen, beantworten wir in der vorliegenden Ausgabe.
Unsere Backup-Kolumne beschäftigt sich dieses Mal mit den Fragen, ob Object Storage als Speicherarchitektur für die Datensicherung geeignet ist und ob sich das finanziell rechnet.
Die aktuelle Agile-IT-Kolumne zeigt, wie wichtig dynamisch provisionierter Speicher für Container-Plattformen ist und wie dies ganz konkret gelingt.
Lesen Sie außerdem, wie Sie mit dem West Trax Future Readiness Assessment ohne großen Zeitaufwand Ihrerseits herausfinden können, ob Ihre SAP-Landschaft für die Einsatzmöglichkeiten zukunftsweisender Technologien bereit ist.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Neue Marke "Digital Trust" bündelt Security-Lösungsangebot von Computacenter
Weitere InfosComputacenter hat die Cisco® Partner Summit Country Awards „Public Sector Partner of the Year”, „Partner of the Year” und „Enterprise Partner of the Year” erhalten.
Weitere Infos
Wir zeigen Ihnen HPE Synergy live: Im HPE Solution Center der Computacenter-Geschäftsstelle Ratingen können Kunden sich ein Bild von der Hardware, dem Aufbau und dem Betrieb des Systems machen. Parallel arbeiten die Computacenter-Consultants aus den Bereichen Flexible Workplace und Dynamic Datacenter im Solution Center und bauen Lösungen auf, welche die brennenden Themen der IT-Verantwortlichen unserer Kunden adressieren.
Das Projekt „ServiceNow & HPE OneView“ befasst sich mit einem alltäglichen Problem: Wie lässt sich ein Alarm, den OneView im Dashboard anzeigt, ins Ticketsystem überführen, in diesem Fall ServiceNow? Wir zeigen Ihnen, wie das reibungslos gelingt.
VEEAM ist gerade bei unseren Kunden mit virtuellen Infrastrukturen eine weit verbreitete Datensicherungs- und Wiederherstellungslösung.
Mit Veeam Software und HPE 3PAR in Kombination mit HPE StoreOnce wird eine hervorragende Availaiblity- und Monitoring-Lösung für Daten und Anwendungen bereitgestellt. Die StoreOnce wird über eine effiziente Catalyst-Schnittstelle angesprochen, um die Daten dedupliziert abzusichern, und bietet auch die Möglichkeit, über Cloudbank eine weitere Kopie auf eine Private Cloud (beispielsweise Scality) oder Public Cloud (beispielsweise AWS) zu schreiben.
Welcher Big Data Analytics Workload erwartet unsere Kunden morgen? Hadoop? Deep Learning? In-Memory Analytics à la Apache Spark?
Diese Frage kann heute noch niemand beantworten. Da hilft es, eine agile und flexible HPE-Big-Data-Analytics-Infrastruktur aufzubauen, die auf die heutigen und zukünftigen Business-Anforderungen jederzeit reagieren kann.
Wir zeigen auf Red Hat Openshift 3.6 Cluster unter anderem folgende Projekte:
Auf drei HPE-Apollo-4530-Servern läuft ein Hortonworks HDP 2.6 Cluster, welcher rund 300 GB Twitter-Daten und 1TB teragen-Daten enthält.
Die Kommunikation der Spark2-Worker-Container in Openshift zu den HDFS-Knoten auf den Apollos läuft über ein 40-GBit/s-Netzwerk
Wir zeigen auf HPE Server mit nVidia Tesla M60 GPUs, wie man High Performance Virtual Desktops mit hohen Ansprüchen an Rechenleistung und Rendering (3D-CAD, Simulation) bereitstellen kann. Wir demonstrieren Ihnen die Lösung auf Basis von Microsoft Hyper-V Server 2016 & RFX mit RDSH und RDVH unter dem Motto „Flexible Workplace meets Dynamic Datacenter – Gemeinsam Gas geben“.
Durch VMware Horizon View mit GPU-Unterstützung können auch Applikationen mit hohen Grafikanforderungen virtuell zur Verfügung gestellt werden. Dies ermöglicht zum einen flexiblen Zugriff von unterschiedlichsten Endgeräten und Lokationen und zum anderen eine erhöhte Datensicherheit, da diese im Unternehmen verbleiben können.
Bei der Hybrid Container Application Platform handelt es sich um einen Show-Case für das universelle Deployment der Redhat-Openshift-Container-Plattform auf verschiedene Compute-Plattformen. Unter diesen Plattformen ist neben VMware vSphere 6 insbesondere die HPE Synergy zu nennen.
Diese kann – voll automatisiert per Ansible Playbooks und die OneView REST API – über den OneView ImageStreamer mit einem individuell konfigurierten Server Profile ausgestattet werden. Das Synergy Server Profile wird anschließend in den bestehenden Openshift Cluster als neuer Compute Node integriert.
Was hat Tauchen mit SAP HANA zu tun? Nicht ohne Grund betreibt Computacenter das SAP HANA Solution Lab auf HPE Synergy. Leistungsstarke Servertechnologie von HPE und End to End Services von Computacenter sind die perfekte Value Story für jedes Unternehmen. Wir zeigen im Deep Dive, wie intelligente Automatisierung Ihrer IT Operation neue Freiräume schafft und die Qualität im Betrieb erhöht.
Es liegt auf der Hand, dass E-Akten-Systeme und Cloud-Technologien gemeinsam einen effizienten Betrieb und optimalen Service ermöglichen. Amazon, Google, Microsoft, Redhat – all diese Unternehmen machen es vor. Mit wenigen Klicks kann sich ein Nutzer registrieren und anschließend diverse Services bestellen, die innerhalb von Minuten als Gesamtlösung zur Verfügung stehen. Hierzulande kämpft der Betrieb der Behörden noch mit aufwendigen Bestellprozessen und teils manueller Installation. Im Solution Center zeigen wir, wie eine Cloud-Management-Plattform als Portal für die Bestellung und Verwaltung des E-Akten–Services funktioniert. Ein Orchestrator steuert die automatisierte Installation und Konfiguration der bestellten Software. Abrechnungs- und Genehmigungsprozesse sind dabei ebenfalls abbildbar.
Den Mittelpunkt des Computacenter HPE Solution Centers bildet die Hardware Platform HPE Synergy. HPE Synergy ist die Composable Infrastructure von Hewlett Packard Enterprise (HPE) und der Nachfolger des erfolgreichen Bladesystems c7000. Wir zeigen den Aufbau sowie das Management der Infrastruktur und demonstrieren, was Synergy von konventionellen Infrastrukturen unterscheidet und was nicht. Neben HPE
Synergy zeigen wir die Integration mit HPE Storage und die HPE-Apollo-Systeme.
Wir freuen uns, Ihnen die Lösungen vorzustellen und mögliche Einsatzszenarien in Ihrem Unternehmen zu besprechen. Rufen Sie gleich an!

Laut Analysten wie Gartner und IDC wird die weltweit gespeicherte Datenmenge bereits im Jahr 2020 die gigantische Größe von 50 Zetabyte erreichen. Doch die bisherigen traditionellen Speichertechnologien sind nicht dafür ausgelegt, solch riesige Datenmengen effizient zu speichern. Object Storage könnte die Lösung sein. Computacenter stellt die Speicherarchitektur vor und zeigt geeignete Anwendungsszenarien.
Seit 2012 ist das Volumen im Bereich „unstrukturierter Daten“ um durchschnittlich 30 bis 40 Prozent pro Jahr gewachsen. Die IT-Abteilungen stehen dadurch vor einer echten Herausforderung. Zwar sinken auch die Preise für Speicherinfrastrukturen pro Terabyte, aber mit 25 Prozent pro Jahr nicht ganz so rasant wie das Datenvolumen auf der anderen Seite zunimmt. In Zeiten von gleichbleibenden oder sinkenden IT-Budgets für die Standard-IT steht deshalb der Bereich Speicherung von Daten in einem besonderen Fokus.
Wachstumstreiber für die „unstrukturierten Daten“ sind die Anwendungsbereiche Internet of Things (IoT), Video, Audio, soziale Netzwerke. Unternehmen speichern heute Informationen für zukünftige, heute nicht absehbare Anwendungsfälle. Diese Informationen stammen aus den unterschiedlichsten Quellen und dienen letztendlich dem Zweck, aus Daten Informationen zu extrahieren. Im Kontext der Digitalisierung wird damit oft vom Öl des 21 Jahrhunderts gesprochen.

Die bisherigen traditionellen Speichertechnologien wie Block Storage und File-Systeme sind nicht dafür konstruiert, riesige Datenmengen mit mehreren Milliarden Dateien oder Datensätzen effizient und in beliebiger Größe zu speichern. Die technische Lösung für diese Anforderungen kann der Einsatz von Object Storage darstellen. Diese Technologie ist speziell für die Aufbewahrung von Milliarden Datenobjekten und für Kapazitäten von bis zu mehreren Exabytes entwickelt worden.
Object Storage avanciert dabei neben Block und File Storage zu einer neuen, dritten Speicherarchitektur. Sie ist modern, softwarebasiert, universell einsetzbar, verfügbar und wirtschaftlich skalierbar. Im Vergleich zu den anderen beiden Speicherarchitekturen benötigt sie im Einsatz einen deutlich geringeren Betriebsaufwand.
Anwender nutzen heute schon verbreitet Object-Storage–Technologien, ohne dies explizit zu wissen. So werden heutzutage Videos von Streaming-Plattformen wie Amazon Prime oder Netflix auf Object-Storage-Systemen gelagert. In der Regel basieren die Cloud-Storage-Angebote der Public Cloud Provider ebenfalls auf Object Storage.
Während Block-Speicherarchitekturen nur von wenigen Serversystemen im Rechenzentrum zugreifbar sind, steht beim File Storage der gemeinsame Zugriff von IT-Systemen im Fokus. Durch die hierarchische Baumstruktur eines File-Systems ergeben sich bei der gleichzeitigen Nutzung Herausforderungen hinsichtlich der Skalierung solcher Systeme. Object Storage kommuniziert über eine Standard-Web-Schnittstelle und benötigt dafür keine gesonderte Übertragungstechnologie wie FibreChannel, iSCSI, NFS oder SMB. Neben den eigentlichen Daten werden immer auch beschreibende Metadaten zu Object mitgespeichert. Hierbei ergibt sich die Möglichkeit, den sonst unstrukturierten Daten semistrukturierte Metadaten hinzuzufügen. Zusätzliche Informationen, wie zum Beispiel die Anzahl von Replikaten oder Dokumentengültigkeiten, sind hier wertvolle Zusätze für ein aktives Datenmanagement.
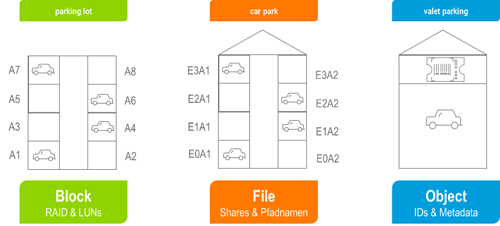
Daten werden je nach verwendeter Speicherarchitektur unterschiedlich abgespeichert. Dies kann man mit parkenden Autos vergleichen. Bei einer Block-Architektur steht auf einem Parkplatz eine nummerierte Anzahl von Parkplätzen zur Verfügung. Das Betriebssystem eines Servers bestimmt dabei das Parklayout, also die Zuordnung. Fileservice-Strukturen sind vergleichbar mit einem Parkhaus mit mehreren Ebenen und einer definierten Auffahrt. Die Verwaltung, wo ein Auto zu parken hat, obliegt dem jeweiligen Parkhaus. Object-Storage-Architekturen sind in diesem Zusammenhang mit einem Parkservice vergleichbar. Der einzelne Autobesitzer weiß nicht mehr, wo sein Auto abgestellt wird, sondern bekommt eine Marke des Parkservices. Die Verwaltung und Zuordnung wird gesondert von den Autos in einer Extraablage (Metadata) geführt.
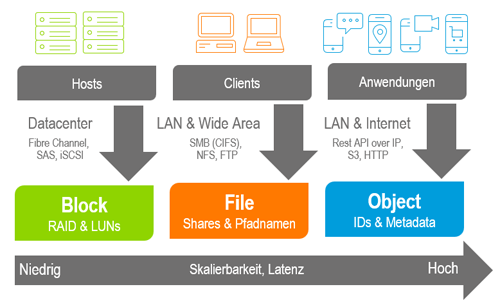
Object-Storage-Plattformen stellen Protokolle wie S3, HTTP, REST und Swift als Zugriffsprotokoll zur Verfügung. Zusätzliche Lösungen für beispielsweise Enterprise File Services oder unternehmensinterne „DropBox“-Varianten realisieren den herkömmlichen CIFS- oder NFS-Zugriff, wenn die verwendete Applikation kein S3 oder REST spricht.
Nicht geeignet für Object Storage hingegen sind Anwendungen, bei denen eine hohe Performance und geringere Latenz gefordert sind (zum Beispiel Produktionsdatenbanken). Hier werden auch weiterhin Block- und File-Storage-Lösungen zum Einsatz kommen.
Für den Einsatz von Object Storage gibt es zahlreiche Anwendungsbeispiele. Häufig werden diese durch die Anwendung getrieben. Damit ergibt sich, dass Object Storage meist über einen speziellen Use Case Einzug in die Unternehmens-IT hält und dann als universelle Speicherplattform für Massendaten ausgebaut wird. Durch die Skalierung in x86-Serverblöcken ist dies in Verbindung mit dem SDS-Layer auch im laufenden Betrieb umsetzbar.
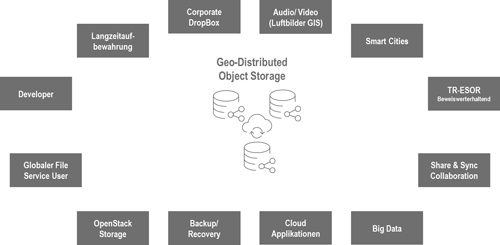
Computacenter hat in den vergangenen drei Jahren zahlreiche und vielfältige Projekte zu Object Storage umgesetzt. Dabei haben sich typische Einsatzszenarien abgezeichnet. Allgemein lässt sich sagen, dass Object Storage immer dann als Technologie zum Einsatz kommen kann, wenn
Im Markt für Object Storage gibt es derzeit sehr viel Bewegung. Während relativ viele junge Unternehmen (Start-ups) auf dem Markt erscheinen, verstärken sich etablierte Größen der Speicherindustrie mit Zukäufen und Übernahmen. So hat RedHat die Firma Ink Tank aufgrund ihres Know-hows im Bereich RADOS akquiriert. RADOS – reliable autonomic distributed object storage – ist die Kernkomponente von CEPH (Open Source Object Storage Project). HGST, Tochterfirma des Festplattenherstellers Western Digital, hat 2015 das Start-up Amplidata übernommen. Im gleichen Jahr akquirierte IBM die Firma Cleversafe und bietet seitdem mit COS den Cloud Object Storage in seinem Portfolio vor allem im eigenen Public Cloud Offering „Bluemix“ an. HPE ist einen anderen Weg gegangen und tätigte ein strategisches Investment mit der Beteiligung an dem französisch-amerikanischen Start-up Scality, das auch mit Cisco eine strategische Vertriebspartnerschaft verbindet.
Die Hersteller Dell EMC (FilePool 2001), Hitachi Vantara (Archivas 2007) und NetApp (Bycast 2010) – alle drei bekannte Größen im Speichermarkt – haben schon länger Zugang zu Object-Storage-Technologien durch Zukäufe zwischen 2001 und 2010.
Alle anderen Marktteilnehmer spielen zurzeit eine untergeordnete Rolle oder adressieren nur ein spezielles Marktsegment oder einen speziellen Use Case.
Wir bei Computacenter sind überzeugt, dass der Markt für Object Storage Marktreife erlangt hat. Waren 2014 und 2015 Anfragen zu Object Storage eher vereinzelt zu verzeichnen, so sehen wir seit 2017, dass alle größeren Ausschreibungen Object Storage direkt ausschreiben oder in den Verdingungsunterlagen eine Marktbewertung und einen technologischen Ausblick fordern. Deshalb möchten wir auch in den nächsten Ausgaben dieses Newsletters das Thema immer wieder aufgreifen und dann von konkreten Use Cases im Zusammenhang mit der Object-Storage-Technologie berichten.
Brennen Ihnen aktuell Fragen zu Object Storage und den Einsatzmöglichkeiten unter den Nägeln? Zögern Sie nicht, sich an Ihren Ansprechpartner bei Computacenter zu wenden, der Ihnen gern weiterhilft.

Die neue Datenschutz-Grundverordnung der Europäischen Union (EU-DSGVO) muss bis zum 25. Mai umgesetzt sein. Ganz selbstverständlich springen einem da die Anwendungen in den Sinn, die originär personenbezogene Daten sammeln und speichern – doch häufig existieren davon Datenkopien, zum Teil sogar mehrere an verschiedenen Ablageorten. Wie ist mit diesen Kopien umzugehen? Computacenter bringt Licht ins Dunkel.
Ein Projekt zum Thema EU-DSGVO beginnt häufig mit einer Prozessanalyse. Darin wird geklärt, in welchen Geschäftsprozessen personenbezogene Daten anfallen und welche Auflagen es gibt, unter denen diese Daten verarbeitet werden. Nachgelagert wird dann an die IT-Abteilung die Frage gestellt, in welchen persistenten Speichersystemen diese Daten abgelegt und gespeichert werden.
Die Antwort sieht meist so aus: E-Mails mit personenbezogenen Daten liegen im Mailsystem, oft Exchange. Kundendaten werden in einem CRM-System – eventuell SAP – gespeichert. So entsteht eine Datenlandkarte der persistenten Speichertöpfe mit den personenbezogenen Daten.
Neben dem „produktiven“ Datensatz existieren aber Kopien – an vielen verschiedenen Ablageorten.
Wird der IT-Abteilung die Frage gestellt, ob und wo Datenkopien auch personenbezogener Daten entstehen, dann sind die ersten Antworten naheliegend: in der Datensicherung, in der Speicherspiegelung für das Desaster Recovery und in Snapshots für einen schnellen Zugriff auf alte Versionen. Hier beginnt in der Tat in vielen Unternehmen die erste Grauzone. Bei über 80 Prozent der Kunden finden sich Datensicherungen, die über sehr lange Zeiträume – zehn Jahre ist ein häufiges Beispiel – vorgehalten werden. Das birgt ein Dilemma in sich: Welche Daten werden warum so lange vorgehalten? Welche Business Unit hat die Anforderung gestellt und kennt der Datenschutz dieser Kopien?
Im nächsten Schritt geraten weitere Systeme ins Augenmerk: Test und Entwicklung – und auch Big Data Lakes. Die brauchen natürlich Daten, um die Applikationen weiterzuentwickeln oder zu testen. Oft werden dazu Verfahren verwendet, die sehr effizient eine Kopie der Produktionsdaten bereitstellen – und in der können schnell personenbezogene Daten oder andere vertrauliche Daten enthalten sein. Das erfordert einen Data-Masking-Prozess, um diese Daten zu anonymisieren. Damit ist den Anforderungen der EU-DSGVO aber noch nicht Genüge getan, denn tatsächlich fällt der gesamte Prozess darunter – von der Anforderung der Datenkopie über das Data Masking bis zur Bereitstellung. Dieser gesamte Prozess muss dokumentiert und gesichert sein, um die Vertraulichkeit der Daten sicherzustellen.
Darüber hinaus gibt es einen weiteren, wenig transparenten Bereich, in dem personenbezogene und vertrauliche Daten abgelegt sein können. Das sind die File Services oder die neuen Plattformen wie OneDrive, SaaS-Applikationen in der Cloud, auf Endgeräten und so fort. Betroffen sind also sehr vielfältige Technologien und Plattformen. Doch warum liegen dort überhaupt solche Informationen?
Die Antwort ist einfach: Sie liegen dort, weil in vielen Fällen Werkzeuge wie Excel und andere verwendet werden, um Informationen und Daten aufzubereiten und für das Business nutzbar zu machen. Schon ein einfacher Brief oder das Teilen von Unterlagen in einem Fachteam über SharePoint Online kann bedeuten, dass in einem dieser unstrukturierten Datentöpfe eine Kopie von personenbezogenen Daten landet, die primär beispielsweise in einer SAP-Datenbank liegen.
An dieser Stelle eine Aussage vom Datenschutzbeauftragten eines Kunden: „Der Datenschutz kennt eigentlich keine Kopien.“ Das ist naheliegend, denn der Geschäftsprozess, in dem Daten erhoben und verarbeitet werden, benötigt keine Kenntnis von Datenkopien – und eine Archivierung von Daten kennt aus Geschäftssicht ebenfalls keine Kopien, da das archivierte Objekt das Originalobjekt und die einzig gültige Version ist.
Das ist seitens des jeweiligen Unternehmens im Projekt abzuwägen. Die naheliegende Sichtweise kann sein, dass das „Recht auf Vergessenwerden“ auch die Datenkopien im eigenen Rechenzentrum oder bei externen Dienstleistern und Cloud Providern betrifft. Das würde aber bedeuten, dass ein Instrumentarium erforderlich wird, das die relevanten Daten in allen persistenten Speichertöpfen finden und klassifizieren kann und Aktionen auf diesen Speichertöpfen erlaubt.
Aus IT-Sicht kann Computacenter dabei unterstützen, neben der primären Kopie auch die diversen Datenkopien im Unternehmen zu identifizieren und in einen technischen Prozess zu integrieren. Wenden Sie sich am besten gleich an Ihren Ansprechpartner!

Bundesweit häufen sich die Anfragen, bestehende Backup-Architekturen zu modernisieren und auszutauschen. Dabei spielt Object Storage eine zunehmend wichtige Rolle – ob als Object Storage in der Public Cloud oder als dedizierter und sehr wirtschaftlicher Speicher in den eigenen Rechenzentren. Daher stellt sich die Frage: Ist Object Storage als neue Speicherarchitektur für die Datensicherung geeignet und rechnet es sich? Computacenter gibt Antworten.
Object Storage ist eine extrem gut skalierbare Speicherarchitektur, die aufgrund integrierter technischer Verfahren wie Erasure Coding Daten als Objekte sehr effizient und sicher ablegt. Durch die Scale-out-Architektur und eine einfache Verteilung von Daten über mehrere Standorte hinweg wird eine sehr hohe Sicherheit erreicht. Object Storage stellt eine logische Trennung von Mandanten oder Datenbeständen diverser Applikationen über die Bucket-Architektur bereit.
Object Storage ist besonders über den Begriff Amazon AWS S3 als Public Cloud Service bekannt und ist ein Synonym für eine sehr wirtschaftliche Datenspeicherung. Seit einiger Zeit gibt es eine Reihe von Anbietern, die Object Storage „On-Premise“ im eigenen Rechenzentrum bereitstellen und hier einen deutlichen Preisvorteil und eine wesentlich bessere Performance als Public-Cloud-Varianten bieten.
Zusammengefasst ist Object Storage eine extrem skalierbare und wirtschaftliche Plattform, um unstrukturierte Daten aufzunehmen. Typische erste Einsatzgebiete sind Archivierung, Data Tiering für Plattformen wie Hadoop oder File Service, IoT-Anwendungen und natürlich auch für die Datensicherung.
Object Storage ist einerseits ein sehr wirtschaftliches Speichermedium. Damit ist er selbstverständlich für die Datensicherung interessant, da hier sehr große Datenmengen gespeichert werden müssen – bei vielen unserer Kunden erreichen die Dimensionen schnell den Petabyte-Bereich. Daher wird Object Storage gern als Alternative zu Bandtechnologien und Tape Libraries evaluiert. Neuerdings wird Object Storage auch als Alternative zu DeDuplication Appliances und -Plattformen getestet – wobei in beiden Fällen die Prämisse der Kosteneinsparung im Vordergrund steht.
Andererseits ist die Performance zu betrachten, wenn es um die Entscheidung geht, Object Storage zur Datensicherung einzusetzen. Hier gilt: Bei einer Verwendung von Public Cloud Object Storage steht eine gute Performance nicht im Vordergrund.
Eine hohe Restore-Performance an der Datenquelle – meistens im eigenen Rechenzentrum – wird durch eine lokale Backup-Infrastruktur realisiert. In die Public Cloud wandert nur die Datensicherung, die einer langen Aufbewahrungsfrist unterliegt und selten bis nie für einen Restore angefordert wird.
Allerdings sind unter den Vorgaben der Datenschutz-Grundverordnung der Europäischen Union (EU-DSGVO) und den Best Practices für eine Datenarchivierung diese Aufbewahrungsfristen dringend zu überprüfen und neu zu bewerten, da eine Aufbewahrung aller Sicherungskopien eventuell nicht den Vorgaben bezüglich Datenschutz entspricht.
Technisch wird hier eine zweistufige Architektur implementiert. Vor Ort eine performante Backup-Architektur, beispielsweise mit DeDuplication-Hardware, verbunden mit einer Cloud Tier (Public Cloud Object Storage) für Daten mit langen Aufbewahrungsfristen.
Wie verhält es sich aber, wenn der Object Storage vor Ort im eigenen Rechenzentrum aufgebaut wird und damit keine WAN-Trasse zwischen den Quellsystemen und den Backup-Daten liegt? Ist in diesem Fall ein On-Premise Object Storage eine Alternative für althergebrachte Backup-Hardware wie Tape oder DeDuplication-Hardware?
Object Storage und Performance sind in der Tat kein Widerspruch. Implementierungen mit 700 MB/s Durchsatz für die Datensicherung sind erfolgreich getestet und können in der Produktion verwendet werden. Das bedeutet, Object Storage kann auch für hohe Backup/Restore-Performance ausgelegt werden. Allerdings sind dafür eine Reihe von Design-Aspekten zu berücksichtigen. Rein technisch kann ein Object Storage virtualisiert abgebildet werden, alternativ kann man eine sehr kleine Anzahl von Servern – meistens mindestens drei – verwenden. Aber für eine berechenbare Performance sind weitergehende Details zu berücksichtigen und die Einstiegskonfiguration wird mehr als drei Server umfassen. Neben dem Zugriffsprotokoll der Backup-Software auf den Object Storage (S3 oder ein NFS-Gateway der Object-Storage-Plattform) sind ausreichende Netzwerk-Durchsätze zum und innerhalb des Object Storage sowie eine ausreichende Schreibperformance – speziell bei einem Inband Erasure Coding – bereitzustellen.
Wichtig: Mit dem korrekten Design ist all das möglich und Object Storage kann in Hinblick auf Wirtschaftlichkeit und Performance eine echte Alternative zu klassischen Backup-Architekturen bieten.
Ja. Es existiert eine Reihe von Einschränkungen, die im Detail stecken. Bisher haben wir nur Performance und Kosten betrachtet. Aber moderne Backup-Architekturen verwenden spezielle DeDuplication- und Beschleunigungsverfahren verbunden mit Instant Recovery und granularen Restore-Methoden. Oder anders formuliert: Bestimmte Funktionen der Datensicherung funktionieren nicht oder nur eingeschränkt in Verbindung mit Object Storage.
Ein Beispiel: Typische Sicherungen von VMware-Umgebungen nutzen die Schnittstelle der VMware – der Name ist vADP – und das Change Block Tracking (CBT). Das erlaubt es in Kombination mit einer DeDuplication-Funktion, dass nur die Änderungen (aus dem CBT) täglich gesichert werden und im Backup automatisch eine Vollsicherung registriert wird – eine Eigenschaft der intelligenten DeDuplication-Engine. Diese Sicherungslogik lässt sich mit den meisten Produkten nicht oder nur über Umwege mit einem Object Storage verheiraten.
Die Konsequenz kann reichlich Geld kosten. Wenn anstelle einer modernen Backup-Software, welche die Daten dedupliziert in einem S3 Storage ablegt, die Software die Daten nur nativ ablegt, so kann dies einen Faktor 10 bis 15 in den notwendigen Speicherressourcen bedeuten.
Neben der Planung der Object-Storage-Plattform für die Performance muss deshalb parallel auf die Details geschaut werden, damit auch die Backup/Restore-Fähigkeit und -Effizienz eingehalten wird. Das bedeutet, dass der Anbieter der Backup-Software oder -Hardware nicht nur einen „S3 Support“ bereitstellt, sondern auch eine Vielzahl intelligenter Funktionen der Backup-Lösung in Kombination mit S3 unterstützt. Und das Mindestmaß heute ist Kompression, Verschlüsselung (AES256) und DeDuplication – aber mit der Prüfung der Details.
Mit über 20 Jahren Erfahrung in Backup/Restore und einem breiten Spektrum an Backup- und Object-Storage-Lösungen besitzt Computacenter die Expertise, moderne Backup-Architekturen kombiniert mit Object Storage zu designen und zu implementieren. Ihr Ansprechpartner hilft Ihnen gern weiter!

Container bringen viele Vorteile mit sich, gerade bei der Entwicklung und dem Betrieb von Applikationen. Allerdings fehlt ihnen der persistente Speicher für wichtige Informationen wie Metadaten, Logdateien und beispielsweise Datenbanken. Dieser muss daher extern dynamisch provisioniert werden. Computacenter beherrscht die damit verbundenen Anforderungen aus dem Effeff und bietet passende Lösungen.
Developer lieben Container. Der frisch entwickelte Code wird in einen Container gesperrt und hat alle nötigen Bausteine und Komponenten zur Verfügung, um die Applikation ablaufen zu lassen. Der Container kann jetzt auf einer beliebigen Container-Plattform – in der Private oder Public Cloud – gestartet werden. Perfekt.
Aber sind die Container wirklich immer stateless? Das würde bedeuten, dass alle Metadaten, Logdateien und Konfigurationen außerhalb des Containers gespeichert werden. Tatsächlich ist das ein weit verbreitetes Phänomen – mit der Folge, dass bei einem Neustart des Containers diese Daten verloren gehen. Daher gilt persistenter Speicher als eine Hauptanforderung an einen produktiven Container-Betrieb.
Gerade Entwicklern ist es wichtig, Applikationen stateful in Containern zu halten, das heißt, dass die oben genannten Informationen zu den Daten vorgehalten werden. Die Container-Plattform muss also einen persistenten Storage bereitstellen, der an die Container angebunden werden kann. Beispiele hierfür wären die Datenbanken von Cassandra sowie MongoDB und Ähnliche.
Container werden als Images in einem Repository abgelegt oder in einer Build Pipeline dynamisch gebaut und ebenfalls in einem Repository abgelegt. Wenn die Applikation in einem oder in mehreren Container-Images gestartet wird, dann werden basierend auf den Images Instanzen gestartet. Und ein Container Orchestrator wie Kubernetes entscheidet zur Laufzeit, auf welchen Ressourcen – basierend auf Policies – die Instanzen gestartet werden.
Das bedeutet auch, dass zum Zeitpunkt der Ressourcenzuweisung durch den Orchestrator auch der persistente Storage zugewiesen werden muss. Dazu stellt Kubernetes ein Persistent Storage Framework bereit.
Der Orchestrator kann einen vordefinierten Speicherbereich (Fibre Channel, iSCSI, NFS, AWS EBS und so fort) an die jeweilige Instanz anbinden. Dazu sind in Kubernetes die notwendigen Plugins vorhanden, die durch die diversen Hersteller im Open-Source-Projekt zu Kubernetes entwickelt und bereitgestellt wurden.
Diese Art der Speicherzuweisung ist jedoch statisch und erfolgt nach einem klassischen Prozess: Der Applikationsverantwortliche stellt eine Anforderung an Storage, der Storage-Administrator stellt den Speicher bereit und anschließend können in Kubernetes die Policies definiert werden, den Storage anzubinden.
Das ist in der Regel ein langwieriger Prozess, der schnell zu einer Überprovisionierung von Storage führt. Und das Ergebnis entspricht nicht dem Wunsch der Developer. Diese möchten Storage-as-Code provisionieren. Sie wünschen sich also ein Dynamic Storage Provisioning.
Der Storage soll dynamisch und automatisiert in genau der gewünschten Menge mit den erforderlichen Eigenschaften (read-only / read-write, HA, Replication, Snapshot) provisioniert werden, so der Wunsch der Entwickler. Welche Voraussetzungen sind dafür nötig?
Antwort 1: Wir brauchen einen Software Defined Storage Layer, der über RestAPI und CLI angesprochen werden kann.
Antwort 2: Wir brauchen eine Integration in Kubernetes, mit dem über den Orchestrator der Storage dynamisch provisioniert werden kann.
Als zweitgrößter Contributor in den Open-Source-Projekten Kubernetes (nach Google) und Container (Open Container Initiative, nach Docker) hat Redhat umfangreiche Integrationen in Kubernetes für die Einbindung von persistentem Storage vorangetrieben. Dazu existieren zwei weitere Open-Source–Projekte: Heketi und gluster-kubernetes. Heketi stellt die RestAPI und CLI für das Open-Source-Software-Defined-Storage-Projekt GlusterFS bereit. Und gluster-kubernetes die Integration für Kubernetes. Damit wird aus GlusterFS ein Container Native Storage – der wiederum selbst als Container deployed wird.
Alles ganz einfach – jetzt haben wir eine Lösung, wie Entwickler dynamisch persistenten Storage provisionieren können.
Neben diesem Beispiel gibt es weitere Open-Source–Projekte, die infrage kämen. Eines wäre beispielsweise das Projekt Trident, welches die Kubernetes-Plug-ins für NetApp Storage bereitstellt.
In jedem konkreten Projekt muss zunächst entschieden werden, wo die Verantwortlichkeit für die Bereitstellung des persistenten Speichers für Container angesiedelt sein soll (Storage-Team oder Team Container-Plattform). Darüber hinaus stellt sich die Frage, ob die bestehenden Lösungen für Storage geeignete Kubernetes-Plug-ins bereitstellen und welche Funktionen diese unterstützen.
Computacenter hat diverse Lösungen evaluiert und in Projekten realisiert. Sprechen Sie uns bei Interesse gern an und lassen Sie sich die Lösungen in unseren Solution Centern demonstrieren. Wir freuen uns auf Sie!

Das West Trax Future Readiness Assessment richtet sich an alle IT-Verantwortlichen, die ihre SAP-Landschaft für die Einsatzmöglichkeiten zukunftsweisender Technologien vorbereiten möchten. Der besondere Clou: Der größte Teil der Reifegrad-Bestimmung läuft automatisiert ab und erfordert von Kundenseite her kaum Zeitaufwand.
Mithilfe des West Trax Future Readiness Assessment können auch Sie schnell und einfach Ihre SAP-Systeme auf deren Zukunftsfähigkeit überprüfen, etwa hinsichtlich des Einsatzes von In-Memory, S/4HANA, Mobile Computing, Big Data, Cloud, Real Time Business, Internet of Things und weiterer zukunftsweisender Technologien. Das Reifegrad-Assessment erlaubt eine objektive Bestimmung der „Ist-Situation“ sowie klare kundenspezifische Maßnahmenableitungen, um die individuellen Ziele erreichen zu können. Notwendige Projekte können auf Basis von Fakten und mit belastbarem Business Case durchgeführt werden.
Das West Trax Future Readiness Assessment basiert auf der KPI-Scan-Methodik und dem Reifegradmodell von West Trax. Mit der KPI-Scan-Methodik wird die tatsächliche Nutzung von SAP-Systemen durch Endanwender einschließlich vorhandener Schwachstellen im Betrieb und von Geschäftsprozessen transparent. Die Auswertung der Daten erfolgt offline, ohne Systemzugriff.
Anschließend wird unter Einsatz des West-Trax-Reifegradmodells der Reifegrad eines SAP-Systems im Hinblick auf den Nutzen neuer Technologien und Projekte ermittelt sowie optional die notwendigen Maßnahmen zur Optimierung definiert.
Der Auswertung liegt ein von West Trax entwickeltes und durch die IHK Darmstadt zertifiziertes Kennzahlenmodell zugrunde. Während der Bestandsaufnahme werden verschiedene Kennzahlen gemessen und in Branchenbenchmarks vergleichbaren Installationen gegenübergestellt (West Trax eigene Benchmark-Datenbank mit aktuell über 1.500 Analysen in 15 verschiedenen Branchen). Die Ergebnisse der Kennzahlenmessung werden interpretiert und das System in seinen Reifegrad eingestuft sowie nutzenbringende Projekte identifiziert und dokumentiert.
Charmant: Für die Durchführung sind im Vorfeld keine zeitintensiven Workshops erforderlich. Ihre Mitwirkung beschränkt sich auf einen Zeitaufwand von etwa einer Stunde pro SAP-System.
Neugierig? Sprechen Sie uns einfach an!