So machen Sie Ihre Cloud sicher

Sehr geehrte Damen und Herren,
Cloud-Lösungen bereichern die IT-Umgebungen der Unternehmen immens, stellen jedoch auch zusätzliche Anforderungen an das Sicherheitskonzept. In der aktuellen Ausgabe unseres Datacenter-Newsletters zeigen wir Ihnen, wie Sie dank unseres Cloud Security Frameworks jederzeit auf der sicheren Seite sind.
Lesen Sie außerdem, wie Sie mit AppDynamics den Überblick über jede noch so vielschichtige Applikation behalten und zudem ad hoc neue Funktionen implementieren und die Akzeptanz seitens Ihrer Kunden herausfinden können.
Auch Rechenzentren müssen von Zeit zu Zeit modernisiert werden. Mit der richtigen Strategie und geeigneten Technologien und Services gelingt eine solche Modernisierung reibungslos. Wir präsentieren Ihnen die Top-Tipps für einige typische Szenarien.
Lassen Sie sich darüber hinaus zeigen, wie künstliche Intelligenz Sie beim Management komplexer IT-Systeme unterstützen kann. Artificial Intelligence for IT Operations lautet hier das Schlagwort. Mit ServiceNow erhalten Sie eine Lösung, die alle wichtigen Funktionalitäten bereits an Bord hat.
In unserer Backup-Kolumne gehen wir den unterschiedlichen Arten des Zusammenspiels von Backup und Cloud auf den Grund. Und in unserer Agile-IT-Kolumne dreht sich dieses Mal alles um die Automation der Netzwerkkonfigurationen. Neben der technischen Umsetzung hängt deren erfolgreiche Einführung von weiteren Faktoren ab, die man nicht vernachlässigen darf. Wir stellen sie Ihnen vor.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter plc. hat heute die vorläufigen Zahlen für das erste Halbjahr 2019 bekanntgegeben.
Weitere InfosComputacenter hat seine neue Geschäftsstelle in Frankfurt offiziell eröffnet.
Weitere Infos
Stetig wachsende Anforderungen an das Geschäft und immer neue Herausforderungen im Markt nötigen Unternehmen dazu, immer schneller und flexibler auf Kundenwünsche zu reagieren. Bei der Evaluierung neuer Entwicklungs- und Produktionsfertigkeiten sowie bei der Verschlankung und Beschleunigung der eigenen Prozesse führt heute kein Weg mehr an der Cloud vorbei. Dabei spielt der Schutz der Daten eine entscheidende Rolle. Mit Computacenter finden Sie dafür die passende Lösung.
Egal, ob es um Infrastructure-, Plattform- oder Software-as-a-Service-Angebote geht, in letzter Instanz ist das Unternehmen für den Schutz seiner Daten selbst zuständig. Ebenso obliegt ihm die Nachweispflicht bei Audits oder regulatorischen Prüfungen. Mit der Nutzung von Cloud-Plattformen oder gar Container-Lösungen wie Docker steigen jedoch die Komplexität der Umgebungen und die Anforderungen an die Administratoren. Umso schwieriger wird es, die Übersicht über die Datenstämme zu behalten sowie das geforderte Schutzniveau einzuhalten.
Generell stellt die Absicherung von Infrastructure-as-a-Service-Cloud-Plattformen keine grundlegend neuen Herausforderungen an die Sicherheit, da sich die Bedrohungslage gegenüber klassischen RZ-Infrastrukturen nur minimal ändert. Herkömmliche Sicherheitskonzepte funktionieren auch in Cloud-Umgebungen, müssen allerdings angepasst werden, um der größeren Angriffsfläche und dem höheren Bedarf an Automatisierung und Orchestrierung gerecht zu werden. Es gibt jedoch Lösungsmöglichkeiten, um diesen Herausforderungen zu begegnen. Eine ganzheitliche Cloud-Strategie beinhaltet, je nach Anforderung, sowohl herkömmliche als auch neue Lösungsansätze zur Cloud-Sicherheit. Letztere basieren auf den integrierten Lösungen des Cloud Service Providers oder beziehen ganz neue Mechanismen ein, beispielsweise den Cloud Access Security Broker (CASB).
Computacenters Vorgehensweise zur Entwicklung eines Cloud Security Frameworks orientiert sich an den Grundlagen zur Entwicklung von IT-Sicherheitsmanagement-Systemen. Gemäß der Sicherheitspyramide des Bundesamts für Sicherheit in der Informationstechnik (BSI) steht ganz oben die IT-Leitlinie. Neben der generellen Aussage zur Nutzung der IT beschreiben aktuelle Leitlinien, welchen Mehrwert durch eine Cloud-Nutzung erzeugt werden soll. Die Definition der IT-Leitlinie erfolgt außerhalb des Frameworks.
Zur Absicherung der Strategie werden unternehmensindividuelle allgemeine Sicherheitsrichtlinien entwickelt, die sogenannten Guardrails. Die Guardrails sind generisch und können für unterschiedliche typengleiche Cloud-Plattformen eingesetzt werden. Zur Entwicklung der Vorgaben verwendet Computacenter den selbst entwickelten „Best-Practice-Katalog für Cloud-Plattformen“. Dieser bildet einen Querschnitt aus dem internationalen Standard der European Union Agency for Network and Information Security (ENISA) und dem BSI C5. Zusätzlich wurde der Best Practice Catalogue mit den gesammelten Projekt-Erfahrungen von Computacenter-Consultants angereichert.
Bei der Entwicklung des Cloud Security Frameworks wird prinzipiell die Pyramide von oben nach unten abgearbeitet. In den oberen Schichten ist die Ausarbeitung generell gehalten und die Detailtiefe ist überschaubar; in den tieferen Schichten sind die Ausarbeitungen sehr detailliert und die Umfänge entsprechend groß. Das Top-down-Verfahren wird eingesetzt, wenn ein Unternehmen am Beginn seiner Cloud-Nutzung steht. Sollte ein Unternehmen allerdings bereits Cloud Services nutzen und schon technische Konzepte entwickelt haben, so können daraus auch die allgemeinen Sicherheitsvorgaben abgeleitet werden. In diesem Fall spricht man vom Bottom-up–Vorgehen. Fehlende Guardrails und Konzepte werden ergänzt.
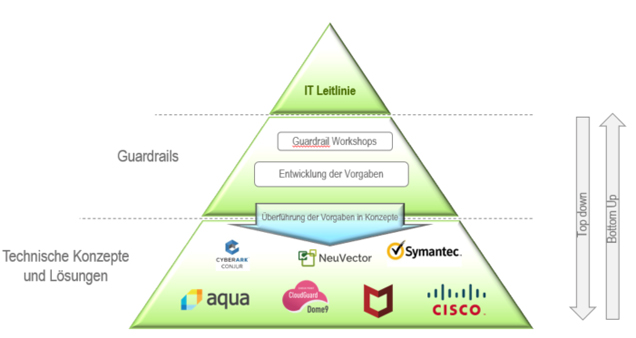
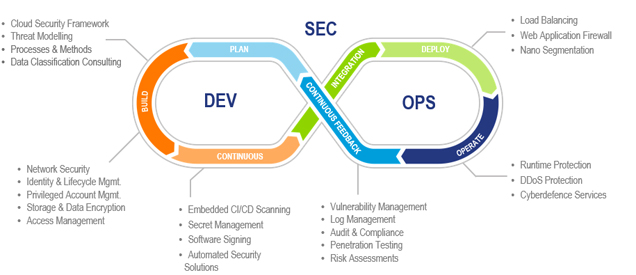
Mit dem Einzug von Containern in heutige Rechenzentren entstehen weitere Angriffsvektoren, die die Sicherheit einer Umgebung beeinträchtigen können. Heutige Sicherheitskonzepte müssen eine weitere Technologie-Ebene einbeziehen, um rundum gegen Angriffe und Schadcode zu schützen. Computacenter hat dazu das bestehende Cloud Security Framework erweitert, um Container ebenfalls effektiv schützen zu können. Die bereits bestehenden Sicherheitskategorien wurden neu aufgeteilt und den neuen Bereichen zugeordnet. Dadurch verfügt Computacenter über ein umfassendes Framework, das auch zum Schutz von DevOps-Umgebungen und CI/CD Pipelines geeignet ist. Dabei werden die Anforderungen der Softwareentwicklung und der damit verbundenen Arbeitsweisen ebenfalls berücksichtigt. Darüber hinaus wird dem erhöhten Automatisierungsgrad Rechnung getragen, indem auf den Einsatz von vollständig automatisierbaren Sicherheitslösungen geachtet wird.
Wünschen Sie weitere Informationen zu einer umfassenden Sicherheitslösung für Ihre Cloud-Plattform? Dann vereinbaren Sie am besten noch heute einen Beratungstermin bei Ihrem Ansprechpartner von Computacenter.

Moderne Applikationen sind komplex. Micro Services, Cloud-native Architekturen und das Einbinden von neuen Technologien wie Serverless verwandeln die klassischen 3-Tier-Applikationen in vielschichtige Konstrukte aus unterschiedlichen Bausteinen. Mit AppDynamics behalten Sie dennoch jederzeit den Überblick. Zudem können Sie ad hoc neue Funktionen implementieren und auf Knopfdruck herausfinden, wie Ihre Kunden weltweit diese Funktionen aufnehmen.
Je komplexer eine Applikation ist, desto schwieriger ist es, die Ursache einer Störung zu finden. Nehmen wir ein Beispiel: Die Antwortzeiten der Applikation an den mobilen Apps und den Webbrowsern ist nicht akzeptabel, die Benutzer klicken sich zu Webseiten von Marktbegleitern durch. Nun beginnt die Suche nach dem Grund für die schlechte Performance. Der berüchtigte War Room wird eröffnet und Kolleginnen und Kollegen aus diversen Team (Server, Netzwerk, Storage, Datenbanken, Middleware, Applikation) kommen zusammen, um nach der Ursache zu suchen. Und viel Zeit vergeht.
Die klassischen Monitoring-Lösungen liefern Informationen zu der jeweiligen Komponente, aber ein übergreifendes Bild der betroffenen Applikation – von der App bis zum Backend – ist nicht verfügbar.
In solchen Situationen wird deutlich, dass ein Ende-zu-Ende-Monitoring für eine Micro-Service-orientierte Architektur in Echtzeit nicht nur sinnvoll, sondern auch notwendig ist. Mit Application-Performance-Monitoring-Lösungen wie AppDynamics wird der Weg einer Benutztertransaktion in Echtzeit über die gesamte Kette hinweg überwacht und die Latenzen und notwendigen Zeiten bei jedem Schritt protokolliert. Über längere Zeiten werden diese Informationen aggregiert und für Trendanalysen und weitergehende Auswertungen bereitgestellt.
Der Wert dieser Informationen ist immens. Beginnend mit einem Mapping der Kommunikationsbeziehungen der Applikationen – Ende-zu-Ende – über die Antwortzeiten in jedem Kommunikationsschritt bis hin zu einer zielgenauen Suche nach Anomalien und Performance-Problemen stehen alle Informationen visualisiert und in einem Drill-down zur Verfügung. Wird eine Kommunikationsmatrix für die Applikation benötigt, so steht diese automatisch erzeugt für die gesamte Kette zur Verfügung. Möchten Sie wissen, welche Komponenten und Bausteine in der Applikation enthalten sind – sowohl solche in eigener Verantwortung als auch diejenigen, die extern (zum Beispiel in der Cloud) vorgehalten werden? Sie finden all das grafisch aufbereitet in der Applikations-Übersicht. Und bei einem Engpass führt ein einfacher Drill-down schnell zur Root Cause für den Incident. Punktgenau.
Damit stehen alle Informationen bereit, um eine schnelle Analyse von Störungen durchzuführen und eine zielgenaue Fehlerbehebung einzuleiten. Zusätzlich kann AppDynamics mit ServiceNow verbunden werden, um einheitliche IT-Service-Management-Prozesse und Reportings erstellen zu können.
Der Wert von Application-Performance-Monitoring-Lösungen geht jedoch noch weiter. Über die aggregierten Informationen lassen sich Trends erkennen und es können zudem proaktive Analysen durchgeführt werden – was als Beratungsleistung für die diversen DevOps- und Applikationsteams bereitgestellt werden kann. Richtig aufgesetzt führt dies zu einer nachhaltigen Optimierung der Applikationen und der Qualität der Business-Anwendungen.
Eine Root-Cause-Analyse ist eine technische Sichtweise. Die ist wichtig für den täglichen Betrieb und für eine fortlaufende Optimierung der Anwendungen. Der Product Owner der Business-Applikation erwartet jedoch eine Übersicht darüber, wie die Applikation weltweit angenommen wird und wie sich neue Features auf das Geschäft auswirken. Dazu wünscht er sich komfortable Dashboards, in denen der Erfolg und die Verteilung des globalen Business sichtbar werden.
Mit AppDynamics stehen diese Informationen mit den Komponenten Business IQ und Application Analytics zur Verfügung. Die Daten lassen sich darüber hinaus beispielsweise mit Finanzdaten verbinden, sodass direkt abgelesen werden kann, wie sich der Umsatz global über die Regionen verteilt, wie sich neue Features monetär auswirken und wie sich der Geschäftsverlauf über den Tag hinweg verteilt.
Gerade diese Kombination der technischen und geschäftlichen Sichtweisen auf neue Applikationen ist eine Schlüsseltechnologie, um erfolgreich und effizient komplexe Applikationen einzusetzen und eine komplette Ende-zu-Ende-Sicht mit Integration in die ITSM-Prozesse zu erreichen. Unterstützt durch Machine-Learning- und Artifical-Intelligence-Funktionen (ML/AI) erweitert AppDynamics das Application Performance Monitoring hin zu einem AIOps-Modell, um einen effizienten Betrieb und eine lernende Einsicht in die aktuelle Applikations-Performance zu erreichen. Die Lösung berücksichtigt zudem die bestehende Applikationswelt und bietet die Möglichkeit, darüber hinaus Anwendungen wie SAP, Datenbanken und andere klassische Applikationen in das Performance Monitoring zu integrieren.
Gern präsentiert Ihnen Computacenter die Möglichkeiten und Vorteile von AppDynamics und Application Performance Monitoring vor Ort, auch in Verbindung mit modernen Container-basierten Architekturen und DevOps-Methoden. Vereinbaren Sie dazu einfach einen Termin mit Ihrem Ansprechpartner.

Modernisierung an sich ist nichts Neues, weder im privaten Bereich noch im Rechenzentrum. Seitdem Menschen IT-Systeme in Rechenzentren stellen, erneuern sie in unterschiedlichen Zyklen ihre Infrastrukturen, um diese an geänderte Anforderungen aus dem Business oder an technologische Entwicklungen anzupassen. Mit der richtigen Strategie und geeigneten Technologien und Services gelingt eine solche Modernisierung reibungslos. Computacenter präsentiert Ihnen die Top-Tipps für einige typische Szenarien.
Aktuell befinden sich Organisationen und IT-Verantwortliche in der sogenannten digitalen Transformation. Zum einen werden bestehende Prozesse Ende-zu-Ende digitalisiert, zum anderen werden ganz neue Applikationen entwickelt, um neue digitale Geschäftsmodelle zu unterstützen oder erst zu ermöglichen. Experten und Kunden sind sich mittlerweile einig, dass weder die Public Cloud noch die On-Premises-IT das alleinige oder vorherrschende Betriebsmodell sein kann. Die Verbindung von Vorteilen der On-Premises-IT und der Public Cloud Services wird zum bestimmenden IT-Betriebsmodell.
Darüber hinaus zeichnet sich heute schon ab, dass für moderne Applikationen nicht die eine Public Cloud benutzt wird. Vielmehr nutzen moderne Applikationen diverse Services aus unterschiedlichen IaaS-, PaaS- und SaaS-Angeboten. Zusätzlich werden Services aus der On-Premises-Umgebung ebenso wie Services aus den Public Clouds eingebunden. Solche Umgebungen werden über ein Multi-Cloud-Managementsystem verwaltet. Damit kann die On-Premises-IT einfach als ein weiterer Cloud-Standort interpretiert werden.
Eine wie oben beschriebene Umsetzung funktioniert nur, wenn IT-Systeme und -Services ähnlichen oder den gleichen Mechanismen wie Services in den Public-Cloud-Umgebungen folgen. Diese sind insbesondere von Automatisierung und Konsumption gekennzeichnet. Die komplette On-Premises-IT so aufzubauen, widerspricht jedoch der heutigen Realität. Zum einen finden sich in den Rechenzentren über Jahrzehnte gewachsene Infrastrukturen und Prozesse, zum anderen sind eine Vielzahl der heute betriebenen Applikationen monolithisch, also nicht in Services oder gar Microservices unterteilbar. Hier gibt es drei Optionen für den zukünftigen Betrieb oder Weiterbetrieb:
Untersuchungen gehen davon aus, dass etwa 15 bis 30 Prozent der heute betriebenen Applikationen über einen Zeitraum von bis zu 10 Jahren im bisherigen Betriebsmodell weiterzubetreiben sind. Ungefähr 40 bis 50 Prozent der Software werden durch neue Applikationen ersetzt, entweder durch ganz neue Business-Applikationen oder durch Standard-SaaS-Angebote. Bei nur 15 bis 20 Prozent der Bestandsapplikationen gelingt mit einem vertretbaren Aufwand die Portierung auf eine serviceorientierte Applikationsarchitektur.
Demnach verbleiben bis zu einem Drittel der heute eingesetzten Applikationen bis zum Ende ihres LifeCycle im heutigen RZ-Betrieb. Genau für diese Applikationen sind im Rechenzentrum die Bestandssysteme einem normalen Infrastruktur-LifeCycle zu unterziehen, also bei Bedarf zu modernisieren.
Man kann sich das wie eine Modernisierung im privaten Umfeld vorstellen. Wir bauen ein Haus und passen es nach und nach an unsere Bedürfnisse an. Von Zeit zu Zeit müssen neben der jährlichen Wartung und Instandsetzung aber auch größere technologische Veränderungen stattfinden. Aus einem Heizungskessel wird dann ein moderner energieeffizienter Brennwertkessel, aus einem Röhrenfernseher wird ein Flachbildschirm. Die Art der Nutzung, oder übersetzt des Betriebes, ändert sich dabei nicht. Wir erwarten nach wie vor warmes Wasser in einem festgelegten Temperaturbereich oder schauen immer noch Fernsehen – vielleicht etwas mehr als wir sollten.
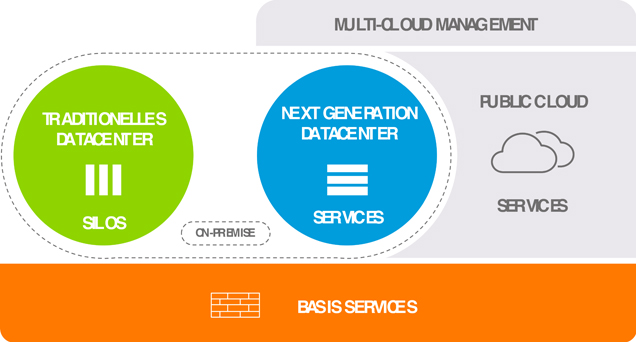
Abb. 1: Infrastruktursicht auf On-Premises und Cloud
Im Rechenzentrum haben wir es vor allem mit Technologien in den Bereichen Compute, Netzwerk, Speicher und Virtualisierung zu tun. Natürlich kümmern sich die Verantwortlichen auch um Applikationen, Datenbanken und Service-Prozesse. Aber bleiben wir für einen Moment bei der Infrastruktur.
Modernisierungen im Bestand sind vor allem technologisch bedingt. Das zugrunde liegende Betriebsmodell wird nicht verändert. Die einzelnen Betriebseinheiten Netzwerk, Speicher, Compute und Virtualisierung erneuern (modernisieren) periodisch ihre Systeme. So kommen Server mit der neusten CPU-Generation, Netzwerk-Switches mit mehr Bandbreite und Speichersysteme mit Flash statt Festplatten in das Rechenzentrum. Die Modernisierung im Bestand verfolgt dabei die Ziele Erneuerung, Stabilität, Wachstum und Kosteneffizienz. Kunden profitieren in der Regel neben der Partizipation an technologischen Weiterentwicklungen auch von veränderten Liefermodellen. In den vergangenen Jahren haben die Schnelligkeit bei der Beschaffung und der Erst-Inbetriebnahme an Bedeutung gewonnen. In der Regel sind in einer IT-Plattformlösung mehrere Herstellersysteme verbaut. Bei der Aktualisierung der Systeme stehen Kunden dann regelmäßig unterschiedlichen Laufzeiten, komplexen Abhängigkeiten der Systeme untereinander und letztendlich auch unterschiedlichen Lieferzeiten der Komponenten gegenüber.
Computacenter liefert mit „Rapid Datacenter Deployment“, „Zero Touch Deployment“ und „Multi Vendor Maintenance Support“ Service-Dienstleistungen, die die oben geschilderten Herausforderungen adressieren.
Mit dem Rapid Datacenter Deployment, auch „Rack&Roll” genannt, lassen sich alle logistischen Herausforderungen bei der Integration neuer IT-Systeme meistern. Neben der Multi-Vendor-Integration im Logistik-Center in Kerpen werden nach kundenindividuellen Blueprints auch Themen wie eine verpackungslose Anlieferung sichergestellt.

Abb. 2: Kernpunkte des Rapid-Datacenter-Deployment-Services
Im Ergebnis profitieren Kunden von den stark verkürzten Bereitstellungszeiten der IT-Systeme und Plattformen und kommen so besonders schnell einen weiteren Schritt Richtung Industrialisierung ihrer IT-Infrastruktur voran.

Abb. 3: Vorteile des Rapid-Datacenter-Deployment-Services
Beim Zero Touch Deployment wird das Ziel verfolgt, Systeme automatisiert in Bestandsumgebungen zu integrieren. Ist die Automation im Rechenzentrum bei einzelnen Systemen noch überschaubar, so werden in einer Multi-Vendor-IT-Plattform die Abhängigkeiten schnell sehr komplex.
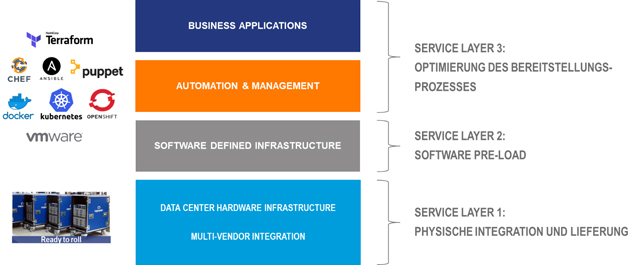
Abb. 4: Multi-Vendor Integration und Zero Touch Deployments
Die Komplexität des Managements von Herstellerverträgen und der Sicherstellung von Support-SLAs steigt linear mit der Anzahl der Hersteller, deren Systeme vom Kunden betreut werden. Doch die Herausforderung liegt nicht nur in der Anzahl, jeder Herstellervertrag funktioniert zudem nach ganz eigenen Spielregeln. Der Ansatz des Multi-Vendor-Maintenance-Service zielt auf ein Ende-zu-Ende-Management und die Kapselung der Servicekomplexität für den Kunden ab.
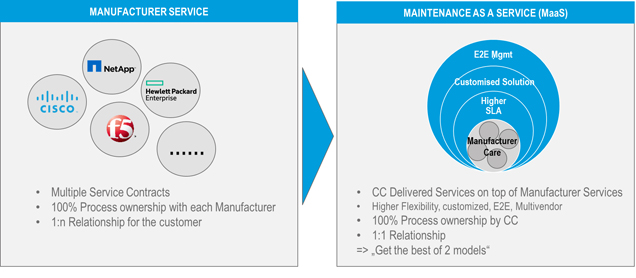
Abb. 5: Maintenance as a Service
Neben der Modernisierung im Bestand finden auch neue Plattformen Einzug in die Rechenzentren. Hier handelt es sich meist um Infrastruktur, die ein neues Betriebsmodell besser unterstützt, als es die Bestandsinfrastrukturen tun können. NGDC-Infrastrukturen sind gekennzeichnet von einer Technologiekonsolidierung und der Ausrichtung des Betriebsmodells auf den zu liefernden Service statt auf Technologie. Aus Anwendersicht ist es egal, ob und wie der Bereich Speicherbetrieb oder Netzwerkbetrieb organisiert ist. Nutzer erwarten den Service Infrastruktur als IaaS und beispielsweise SAP als Applikation per Software as a Service (SaaS).
Für den IaaS-Service werden natürlich immer noch die Expertenthemen Compute, Netzwerk, Speicher und Virtualisierung benötig. Die neue Qualität besteht darin, dass die einzelnen Technologien des Infrastrukturbetriebes gebündelt werden, um den Nutzer über eine übergreifende Zusammenarbeit den Service Infrastruktur als Gesamtheit zur Verfügung zu stellen. Die konsequente und vollständige Automatisierung des Betriebs und die ausschließliche Serviceorientierung sind dem Betriebsmodell von HyperScalern (Public Cloud Providern) sehr ähnlich. Tatsächlich sind ähnliche Grundprinzipien, nämlich das Verständnis von Services und die Umsetzung der Kommunikation über Schnittstellen (API), eine zwingende Voraussetzung dafür, die On-Premises-Systeme in eine Multi-Cloud-Umgebung zu integrieren.
Die Konsolidierung der Technologien Compute, Netzwerk und Speicher findet oft auf der Basis softwarebasierter Technologien statt. Auf einem x86-Server-Block werden alle anderen Technologien über Virtualsierungstechniken realisiert. Software Defined X (SDx) ist hier das Schlagwort. Das „X“ steht für die jeweilige Technologie: Domaine Compute (SDC – Software Defined Computing oder Servervirtualisierung), Networking (SDN – Software Defined Networking) und Storage (SDS – Software Defined Storage). Mit entsprechendem Monitoring, Workflow, Automatisierungs- und Inventory-Funktionen bildet das SDDC – Software Defined Datacenter – die Klammer um alle Infrastrukturbausteine.
Der Betrieb und die Ausgestaltung solcher Umgebungen orientieren sich am ganzheitlichen Infrastrukturservice für den Nutzer und sind geprägt vom Arbeiten mit wiederverwendbaren Polices über Technologie-Domaingrenzen hinweg. Eine gemeinsame Verantwortung aller beteiligten Infrastrukturbereiche für die Serviceerbringung gehört zum Rollenmodell eines dienstleistungsbezogenen IT-Providers.
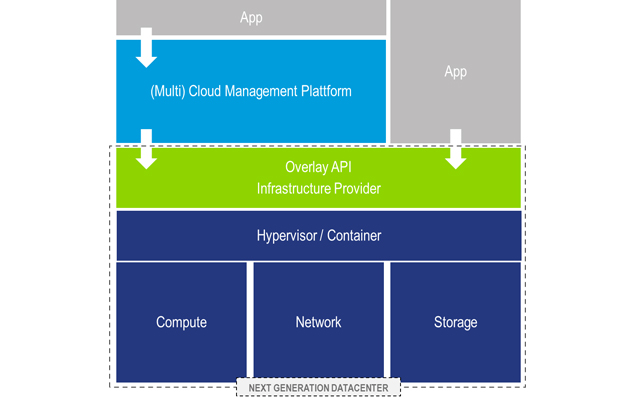
Abb. 6: NGDC-Modell
Ein wie hier beschriebenes NGDC ist ein modernes Infrastruktur-Serviceangebot, welches auf der einen Seite IaaS-Services für Multi-Cloud-Managementsysteme zur Verfügung stellt und auf der anderen Seite modernen, neuen Webapplikationen ermöglicht, Infrastrukturressourcen direkt in Software-Code (IaC – Infrastructure as Code) zu beschreiben und für ihre Belange automatisiert anzufordern.
Modernisierung im Rechenzentrum findet demnach sowohl in der Bestands-IT als auch im Bereich neuer softwarebasierter Infrastrukturplattformen statt.
Möchten Sie mehr über die Möglichkeiten der Modernisierung in Rechenzentren wissen oder haben Sie konkrete Fragen zu Ihrem Modernisierungsbedarf? Dann wenden Sie sich am besten gleich an Ihren Ansprechpartner bei Computacenter, der Ihnen gern weiterhilft.

Wie gut kennen Sie Ihre IT-Systeme wirklich? Fühlen Sie sich gerüstet, dem Management Auskunft über die Performance aller unternehmenskritischen Infrastrukturen geben zu können? Sind Sie zuversichtlich, der Ursache einer möglichen Störung schnell auf die Spur zu kommen und diese zielgenau beheben zu können? Oder haben Sie mit steigender Komplexität der IT-Systeme zunehmend den Überblick verloren? Dann kann Ihnen Artificial Intelligence for IT-Operations gute Dienste leisten.
Der IT-Betrieb steht vor der Herausforderung, dass die Systeme komplexer und komplizierter werden und dass die Anzahl sowie die Verteilung der Systeme steigen. Damit ist schon die Gewinnung der Basisinformationen zu allen Configuration Items (CI) eine große Aufgabe. Gleiches gilt für das Monitoring und das Event Management.
Einige Beispiele: Wissen Sie, ob bei jeder Ihrer IT-Infrastrukturen die notwendige Governance besteht? Oder können einzelne Bereiche im Unternehmen an der zentralen IT vorbei Infrastrukturen erstellen – beispielsweise in der Public Cloud wie bei AWS oder Azure? Haben Sie alle Automatismen im Blick, etwa wenn aufgrund von Performance-Anforderungen Infrastrukturen eigenständig skalieren oder Daten und Anwendungen von einer Plattform auf eine andere verschieben?
Gartner hat hierzu im August 2018 in einer Analyse festgestellt: „Bis 2021 werden weniger als 15 Prozent der Unternehmen ein ganzheitliches Monitoring implementieren, somit sind Investitionen in Cloud-basierte Lösungen in Höhe von 255 Milliarden US-Dollar gefährdet.“ Es besteht also ein immenser Handlungsbedarf.
Die Verfügbarkeit, Performance und Sicherheit der IT-Systeme sind eine existenzielle Notwendigkeit für jedes Unternehmen. Ohne einen neuen Ansatz reagieren IT-Teams nur noch, anstatt proaktiv Innovationen herbeizuführen. Artificial Intelligence for IT-Operations (AIOps) ist ein solcher Ansatz, den laut Gartner bis 2022 40 Prozent aller großen Firmen verwenden werden, um Big-Data- und Machine-Learning-Funktionen zu kombinieren und um damit Überwachungs-, Service-Desk- und Automatisierungsprozesse zu unterstützen und teilweise zu ersetzen. Heute beschäftigen sich gerade einmal 5 Prozent damit.
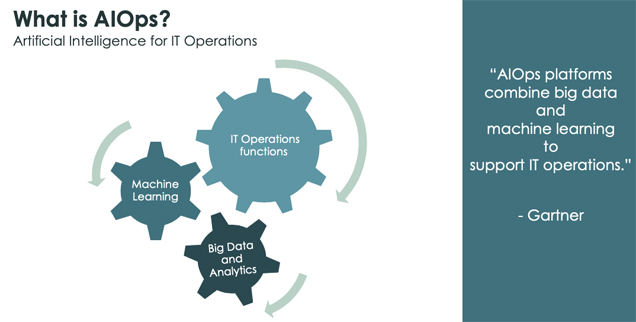
Die Daten im IT-Betrieb stellen eine gute Grundlage für die Anwendung von künstlicher Intelligenz (KI; auch: AI (artificial intelligence)) dar. Es gibt viele Daten aus verschiedensten CMDBs, Monitoring- und Managementsystemen und auch viele Möglichkeiten, die Machine-Learning-Algorithmen anhand von historischen Daten zu trainieren. Dies macht sich Artificial Intelligence for IT Operations (AiOps) zu Nutze. Gartner hat diesen Begriff 2014 geprägt und meint damit die Kombination von Big Data and Analytics und Machine-Learning-Methoden zur Unterstützung der IT Operations.
Alle wesentlichen Markteilnehmer setzen sich mit dem Thema auseinander. Neben den traditionellen Herstellern von IT-Managementsystemen hat sich auch eine stattliche Anzahl neuer Unternehmen des Themas angenommen. Diese haben meist den Vorteil, dass sie keine Rücksicht auf bestehende Installationen nehmen müssen. Ihre Lösungen sind dafür aber häufig nicht so einfach zu integrieren.
Im Fokus der AiOps-Werkzeuge stehen vor allem 3 Anwendungsfälle:
AiOps-Systeme verändern die Sichtweise auf die bisherigen IT-Managementwerkzeuge, da die AiOps-Plattform diese allesamt als Quelle für die Big-Data-Analysen heranzieht. Somit stellt auch die bisherige zentrale CMDB nur noch eine der Datenquellen dar und rückt letztlich aus dem Zentrum des Managements heraus.
AiOps-Plattformen sind in erster Linie Integrationsplattformen, um alle Datenquellen mit den Algorithmen der Big-Data-Analyse und denen des Machine Learnings zu verbinden. Das bedeutet aber auch, dass AiOps-Plattformen die bisherigen Monitoring- und IT Managementsysteme nicht ersetzen, sondern ergänzen, um durch die Kombination der Daten eine bessere Aussagekraft zu erreichen. Dabei werden die technischen Daten beispielsweise mit finanziellen Informationen und Organisationsdaten angereichert, sodass eine bessere Aussage über die Kritikalität einer Störung erfolgen kann. Weiterhin kann auf Basis der Historiendaten per Machine Learning eine Aussage über das Verhalten der Systeme in der Zukunft gemacht werden, womit sich eine Möglichkeit des proaktiven Managements erschließt.
ServiceNow kann mit seinen IT-Operations-Management-Möglichkeiten und den Big-Data- und Machine-Learning-Fähigkeiten der NOW-Plattform als eine der schon gut am Markt positionierten AiOps-Lösungen angesehen werden.
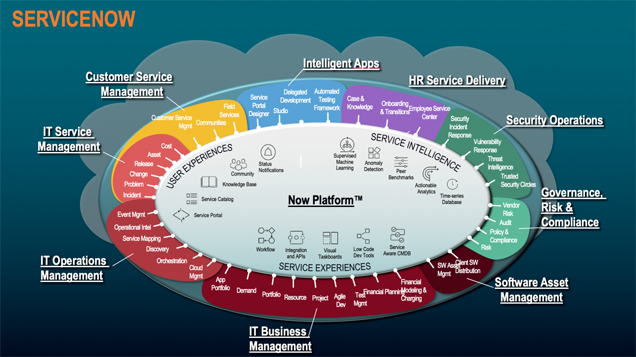
ServiceNow hat im ITOM-Modul alle Funktionalitäten zusammengestellt, um einerseits Infrastrukturen und Abhängigkeiten zu entdecken (Discovery) und in der CMDB bereitzustellen, andererseits können im Event Management alle Quellen bestehender Monitoring-Systeme zusammengeführt werden und per Korrelation und Machine Learning zu Dashboards aufbereitet werden. Natürlich besteht auch die Möglichkeit, automatisiert mit Workflows auf Events zu reagieren und somit die Automation des Event Managements zu verbessern.
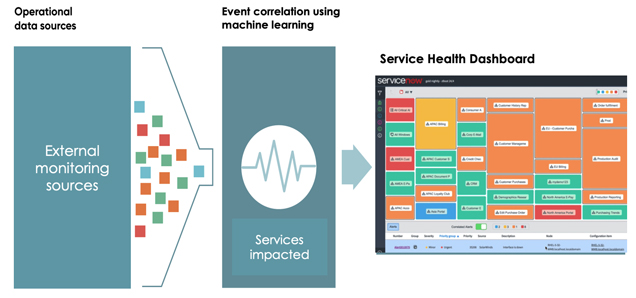
Weiterhin enthält das Modul die Möglichkeit des Service Mappings, sodass auf Basis der Informationen aus Discovery und Event Management unter anderem Rückschlüsse auf die Auswirkungen auf die beteiligten IT Services ermöglicht werden. Damit sind schnelle Root-Cause-Analysen und Entscheidungen zur Wiederherstellung bei Service Outages deutlich schneller möglich als in traditionellen Systemen.
Neben den schon existierenden ITOM Features der Plattform hat ServiceNow für die nächsten Versionen, die im Jahr 2020 erscheinen sollen (Orlando QI/20 und Paris QIII/20), vor allem das prädikative Management im ITOM-Umfeld auf der Roadmap. Nachdem in den letzten Updates vor allem Machine Learning für den ITSM-Bereich im Fokus stand, werden nun diese Funktionalitäten auch für das proaktive Management von Infrastrukturen und Applikationen kommen.
Die Einführung von AiOps-Systemen sollte mit Augenmaß geschehen, da die Technik noch relativ neu ist und sich der Markt noch stark verändert. Dabei sollte man auch immer im Auge haben, was heute schon Realität beziehungsweise was Hype ist. Da sich durch eine AiOps-Einführung die Arbeit im IT Operations Management ändert, sollte man an möglichst konkreten, aktuellen Anforderungen arbeiten. Wichtig scheint weiterhin, dass man die Einführung in nicht zu großen Phasen angeht, um den Wert der Implementierung zu demonstrieren und mögliche Risiken zu minimieren.
Gern beraten wir Sie persönlich und ausführlich zu den Möglichkeiten von Artificial Intelligence for IT-Operations. Melden Sie sich dazu einfach bei Ihrem Ansprechpartner bei Computacenter.

Im Zusammenspiel der Begriffe Backup und Cloud kursieren zahlreiche Begriffe und Erwartungen. Dies beginnt bei Angeboten wie Backup as a Service (BaaS) und geht weiter über Backup in die und in der Cloud bis hin zu der Erwartung, dass die Cloud Backup gleich mitliefert. Jede dieser Lösungen hat ihre eigenen Stärken und Schwächen, die man abhängig von den eigenen konkreten Anforderungen abwägen muss. Wir bringen Licht ins Dunkel.
Ein Backup ist im Kern eine Versicherung oder ein Versprechen. Auf Anfrage bekommt der Endbenutzer die gewünschten Versionen von Dateien, SharePoint-Dokumenten oder E-Mails zurück. Der Datenbank-Administrator dagegen bekommt einen Point-in-Time Restore seiner Datenbank, der Server-Administrator seiner virtuellen Maschine (VM) bereitgestellt.
Das Versprechen ist mit einem Service Level verbunden. Typischerweise erhält man jede beliebige Version der letzten 14 bis 30 Tage, wenn dies erforderlich sein sollte. Und das innerhalb einer vereinbarten und meist sehr kurzen Zeit. Dies wird formalisiert mit den Begriffen Recovery Point (maximaler Datenverlust), Recovery Time (Zeit bis zur Wiederherstellung) und Recovery Level (Granularität) Objective (RPO / RTO / RLO).
Als Administrator oder als Endbenutzer ist es dabei irrelevant, ob das Unternehmen einen Public Cloud Service oder eine On-Premises-Lösung (Private Cloud) einsetzt. Warum sollten auch für Nachrichten in einem O365 Exchange Online Service andere SLAs gelten als für Nachrichten in einem lokalen Exchange Server?
Auch die Geschwindigkeit spielt eine große Rolle. In der Regel dauert es zu lang oder die WAN-Kosten sind zu hoch, um einen Restore über WAN-Strecken durchzuführen. Und das wäre erforderlich, wenn beispielsweise Backups von On-Premises-Servern bei einem Cloud-basierten BaaS-Anbieter oder direkt durch die eingesetzte Backup-Software bei einem Public Cloud Provider abgelegt werden.
Daher stellt sich die Frage, welche Backup-Szenarien in Verbindung mit einer Public Cloud sinnvoll oder erforderlich sind.
Der Klassiker ist die häufig vertretende Ansicht, ein Backup in die Public Cloud sei besonders kostengünstiger und daher sinnvoll. Technisch bedeutet Backup in die Cloud, dass die Backup-Produkte im eigenen Rechenzentrum die Backups durchführen und über einen Backup-Service in die Public Cloud schreiben. Das kann wahlweise über Gateway-Systeme oder durch eine direkte Integration der Backup-Software erfolgen, beispielsweise mit AWS S3 oder vergleichbaren Lösungen. Die Ingest-Kosten sind überschaubar und bei einem Restore müssen die Daten über eine WAN-Verbindung zurückgeladen werden.
Dazu wird für eine effiziente Nutzung eine Deduplizierung der Daten durchgeführt.
Das mag auf den ersten Blick attraktiv erscheinen, allerdings darf man dabei folgende Punkte nicht außer Acht lassen:
Unter Berücksichtigung dieser Punkte kommen viele Unternehmen zu dem Schluss, dass ein Backup in die Cloud keinen Vorteil bringt und damit keine Relevanz für eine zukunftsfähige Planung hat.
Bei Backup as a Service liefert ein Anbieter einen Managed Backup Service inklusive der Ablage der Backup-Daten beim Anbieter in der Public Cloud. Optional können hier auch On-Premises-Backup-Kopien für einen schnellen Restore bereitgestellt werden.
Das Angebot erscheint durchaus attraktiv – aber ist ein wenig detaillierter zu beleuchten.
Das bedeutet, dass eine Schärfung der Ziele und Anforderungen an einen BaaS und damit einen Serviceschnitt nötig ist.
Weiterhin hat ein Unternehmen nicht nur einen Backup-Workflow – beispielsweise über eine zentrale Datensicherungssoftware. In den meisten Unternehmen finden sich drei bis sieben verschiedene Workflows für eine Datensicherung, die zudem durch unterschiedliche Administrationsteams verantwortet werden. Beispiele sind Storage-basierte Methoden (Snapshots) für große File Services, Datenbank-Exporte (Dumps) auf Dateisysteme oder spezialisierte Produkte und Tools für spezifische Applikationen (zum Beispiel Hadoop-Distributionen wie MapR).
Ein weiteres Backup-Modell verbirgt sich hinter dem Begriff Backup in der Cloud. Gemeint ist damit die Datensicherung von Applikationen, Datenbanken und virtuellen Maschinen, die auf einem Hyperscaler betrieben werden. Dabei beinhalten die Verträge der Anbieter von Hyperscalern und von Software as a Service (SaaS) ganz klar: Die Daten liegen in der Verantwortung des jeweiligen Auftraggebers. Weiterhin werden oft keine oder nur sehr vereinzelte und teilweise eingeschränkte Backup-Services bereitgestellt.
Daher ist auch bei einem Einsatz von Hyperscaler-basierten Angeboten und SaaS-Lösungen der Auftraggeber in der Pflicht, den Backup-Service, die SLAs und die Verantwortlichkeiten zu definieren (siehe auch die Definition eines Backups zu Beginn des Artikels) und für einen Audit und die Governance zu dokumentieren und zu testen. Speziell diese Anforderungen werden durch keinen Hyperscaler- oder SaaS-Anbieter umgesetzt.
Somit muss eine übergreifende Definition und Dokumentation des Service Backup – von On-Premises über Hyperscaler bis hin zu SaaS-Angeboten – erfolgen. Aus dem Blickwinkel der Kunden ist dies für die Datensicherung einheitlich erforderlich.
Gern werden auch die Disziplinen Desaster Recovery (DR) und Archivierung mit einem Backup-Service verknüpft. Allerdings adressieren diese Services unterschiedliche Anforderungen und Zielsetzungen. Daher ist es sehr empfehlenswert, hier eine klare Trennung und Definition der Services herbeizuführen, um eine klare Service-Spezifikation zu erreichen. Potenziell können bei der technischen Umsetzung in Teilen Synergien erreicht werden. Das kann bei einer fehlenden brandtechnischen Trennung zwischen Produktion und Datensicherung das Erzeugen einer abgesetzten zweiten Backup-Kopie umfassen, die gleichzeitig als eine DR-Kopie verwendet wird.
Ein weiterer Trend, basierend auf modernen Softwareentwicklungsmethoden und Verfahren, sind Cloud-Native-Applikationen. Das sind Anwendungen, die auf Basis von Modellen wie 12-factor Apps und Microservices implementiert werden und eine integrierte Funktionalität für Desaster Recovery umfassen und auch dediziert für die eigenen persistenten Daten verantwortlich sind. In diesem Kontext sind entweder DevOps-Teams eigenverantwortlich für Backup/Restore zuständig oder stellen automatisierte Komponenten bereit, die einem Betriebsteam eine Datensicherung zur Verfügung stellen (zum Beispiel Kubernetes Operator für Datenbanken).
In jedem Projekt zeigt sich: Die Grundlage für eine sinnvolle und abgestimmte Datensicherung ist eine klare Definition des Backup-Service. Sie beinhaltet die Anforderungen der Kunden für die Datensicherung (Endbenutzer, Administratoren, Applikations- und Business-Teams) und führt die sich daraus ableitenden SLAs auf. Hinzu kommen die Anforderungen aus den Bereichen IT Security und Governance, die für das Handhaben aller Backup-Daten und für den Schutz der Unternehmensdaten umzusetzend sind, sowie das Festlegen von klaren Verantwortlichkeiten.
Darüber hinaus ist eine klare Trennung zwischen den Diensten Backup/Restore, Desaster Recovery (DR) und Archivierung notwendig.
Auf Basis einer solchen Servicedefinition für die Datensicherung kann ein umfassendes Backup-Design vom eigenen Rechenzentrum über Hyperscaler bis hin zu SaaS- und Cloud-Native-Lösungen gespannt werden.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

NetOps ist die IT-Disziplin zur Automation der Netzwerkkonfigurationen. Dies umfasst neben dem eigentlichen Netzwerk auch die automatisierte Konfiguration von Firewalls. Wird eine Applikation im Sinne einer automatisierten Build- und Release-Pipeline ausgerollt oder eine neue virtuelle Maschine – wahlweise in der Private Cloud oder bei einem Hyperscaler – bereitgestellt, so müssen gleich die notwendigen Konfigurationen gesetzt werden, damit eine Kommunikation zur Applikation möglich ist.
In der Analyse „Hype Cycle for I&O Automation“ (I&O steht für Infrastruktur und Operations) von 2019 hat Gartner die Disziplin NetOps in den Bereich Early Mainstream eingestuft. Computacenter kann diesen Trend anhand von Erfahrungswerten bei den Kunden bestätigen: Aktuell laufen eine Reihe von Projekten zum Thema NetOps und I&O Leader fordern zunehmend eine Automation für die Netzwerke und die Konfiguration der Sicherheitskomponenten wie Firewalls.
Bei der Umsetzung solcher Projekte ist die technische Dimension meist die kleinste Herausforderung. Selbstverständlich müssen Technologien und Produkte beschafft werden, die eine Schnittstelle (RestAPI, andere) für eine Automation bereitstellen und idealerweise bereits Ansible-Playbooks oder vergleichbare Skripte unterstützen, auf deren Basis die Automation aufgesetzt werden kann. Diese Playbooks werden dann in einem Betriebs-Repository – in der Regel eine Distribution für GIT wie Gitlab Enterprise oder Bitbucket – gespeichert und vorgehalten. Für ein sicheres und nachvollziehbares Deployment der Skripte und Playbooks kommen dann Lösungen wie beispielsweise Ansible Tower zum Einsatz – damit jederzeit nachvollziehbar ist, welche Änderungen in der Netzwerk- und Firewall-Konfiguration erzeugt werden. Mit einer Anbindung an eine SIEM-Lösung (Siem = Security Information and Event Management) gilt dies auch für die IT Security.
Für die technische Implementierung benötigt man somit eine Reihe von Bausteinen – ausgelegt für einen 24/7-Service:
Das illustriert, dass die technischen Voraussetzungen für die Automation grundsätzlich beschafft werden können und die Tools und Werkzeuge heute verfügbar sind. Dies ist in den Auswahl- und Beschaffungsprozessen entsprechend zu berücksichtigen.
Ist ein NetOps-Projekt abgeschlossen, so kann die Lösung an den Betrieb übergeben werden (Day 2 Operations). Doch der Betrieb darf keine manuellen Konfigurationen oder Einstellungen mehr an den Produkten vornehmen. Eine Eigenschaft der Automation ist, dass der in den Playbooks definierte Zustand kontinuierlich eingehalten wird. Sollte nun jemand im Day 2 Operations eine Firewall-Freischaltung auf dem herkömmlichen Weg einrichten, dann ist diese am nächsten Tag nicht mehr vorhanden, da die Automation diese Freischaltung nicht kennt und somit wieder deaktiviert.
Das bedeutet, dass der Betrieb und die Betriebsprozesse neu zu definieren sind und dass die Betriebsteams auch neue Skills und Fähigkeiten benötigen.
Der neue Weg führt über die Playbooks im Git Repository. Das bedeutet, der Day-2-Betrieb muss in die Handhabung von Werkzeugen wie Git, Ansible und Ansible Tower eingewiesen werden und verstehen, wie eine skriptbasierte Automation der verwendeten Netzwerk- und Sicherheitskomponenten erfolgt. Die neuen beziehungsweise zusätzlich erforderlichen Skills umfassen:
Hierin liegt aus Sicht von Computacenter in den Projekten der entscheidende Faktor, um eine NetOps-Strategie erfolgreich einzuführen. Mitarbeiterinnen und Mitarbeiter, die seit vielen Jahren den Betrieb der Netzwerke und Firewalls sicherstellen, haben eine etablierte und effiziente Arbeitsroutine und stellen oft seit geraumer Zeit den 24/7-Betrieb sicher. Eine grundlegende Veränderung der Betriebsabläufe durch das Einführen einer vollständigen Automation wird in diesen Teams Unruhe und Besorgnis auslösen. Daher darf ein NetOps-Projekt niemals losgelöst von Day 2 Operations aufgesetzt werden. Wir empfehlen, von Anfang an sicherzustellen, dass durch geeignete Workshops, Trainings und weitere Maßnahmen der Day-2-Betrieb eingebunden und davon überzeugt wird, dass die durchgängige Automation dem Unternehmen eine höhere Agilität und schnellere IT-Prozesse bescheren und dass zudem die Mitarbeiterinnen und Mitarbeiter im IT-Betrieb die neuen Arbeitsabläufe und Methoden akzeptieren und persönlich wertschätzen. Das geht Hand in Hand mit der Einführung von DevOps-Methoden und -Verfahren im Unternehmen.
I&O Leaders sollten in einem NetOps-Projekt daher den Fokus auf die kulturellen und betrieblichen Veränderungen legen und in den Betriebsteams auch Skills aus der Softwareentwicklung und im Skripten von Automationsabläufen etablieren. Das bedeutet in letzter Konsequenz auch, dass eine Development- und Test-Umgebung für diese Automationsverfahren notwendig wird und bereits ab dem Erstellen der Automations-Playbooks und dem Deployment der Playbooks die IT-Sicherheit eingebunden sein muss. Schließlich kann ein Playbook deutlich mehr in weniger Zeit verändern, als dies mit manuellen Konfigurationen möglich ist.
Computacenter steht Ihnen gern jederzeit bei Fragen und auch für eine Live-Demo zu den neuen Abläufen und Methoden zur Verfügung. In Projekten hat Computacenter sowohl die technische wie auch die kulturelle Dimension bearbeitet und zudem einen großen Erfahrungsschatz beim Redesign der Betriebsprozesse und Abläufe aufgebaut.
Wenden Sie sich bei Interesse einfach an Ihren Ansprechpartner bei Computacenter.