Virtual Desktop Infrastructure mit Nvidia

Sehr geehrte Damen und Herren,
das Homeoffice boomt – und damit auch das Thema Virtual Desktop Infrastructure. Mit Nvidia vGPU lassen sich auch Arbeitsplätze, die besonders viel Performance benötigen, mit genügend Leistung versorgen. Wir zeigen Ihnen in der aktuellen Ausgabe unseres Datacenter-Newsletters, wie das funktioniert.
Erfahren Sie außerdem, wie Sie dank der Pensando Distributed Service Platform für HPE-Server von einer Steigerung der Netzwerkleistung und mehr Sicherheit beim Zugriff auf Daten und Applikationen profitieren können.
Mit der AWS Landing Zone Solution lassen sich alle Wünsche an ein Cloud Operating Model umsetzen. Lesen Sie in dieser Ausgabe, wie Computacenter als AWS Advanced Partner Sie bei der reibungslosen Implementierung einer Public Cloud in Ihre Unternehmens-IT unterstützen kann.
Zudem zeigen wir Ihnen, welche Möglichkeiten es für eine Modernisierung im Rechenzentrum gibt und wie ein solches Vorhaben am besten gelingt.
Unsere aktuelle Backup-Kolumne befasst sich mit der Schattenwelt der Datensicherung, während unsere Agile-IT-Kolumne dieses Mal die Frage aufgreift, ob eine Cloud für die digitale Transformation ausreicht – oder in welchen Fällen ein Multi-Cloud-Ansatz sinnvoll erscheint.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter hat laut vorläufigen Zahlen im ersten Halbjahr 2020 seinen Gewinn in Deutschland um 15,4 Prozent zum Vorjahreszeitraum steigern können.
Weitere InfosComputacenter kündigte einen neuen End-to-End-Transformation-Service an, der Unternehmen dabei helfen wird, die Umstellung auf Amazon Web Services (AWS) zu beschleunigen.
Weitere Infos
Im Zuge der Corona-Pandemie brauchte man plötzlich sehr schnell die Möglichkeit, von zu Hause aus zu arbeiten – auch in Kundenbereichen, die das bis dahin ausgeschlossen hatten. Somit erhielt das Thema Virtual Desktop Infrastructure (VDI) einen riesigen Schub. Bei Arbeitsplätzen, die besonders viel Performance benötigen, war das mit einer größeren Herausforderung verbunden. Doch die lässt sich meistern.
Früher wurden meist virtuelle Umgebungen für Office-Arbeitsplätze geplant und angeboten. Was aber tun, wenn mehr Performance gefragt ist und der virtuelle Desktop für den gesamten Arbeitsalltag verwendet werden soll? Windows 10 in Verbindung mit Office verschlingt Ressourcen geradezu. Und Grafikleistungen sind sogar noch hungriger, was die Ressourcen anbelangt. Mal ein Video anschauen, Google Earth nutzen, sehr schnell in PDF-Dateien scrollen … In nahezu jedem VDI-Projekt, das wir in den letzten Jahren durchgeführt haben, sind genau diese Anforderungen quasi zum Standard geworden.
Unsere Lösung für Arbeitsplätze, die besonders viel Performance benötigen, lautet Nvidia vGPU. Mit der vGPU-Technologie ist es möglich, eine anspruchsvolle VDI zu erstellen, 3D-CAD-Benutzer mit genügend Leistung zu versorgen und sogar das Thema AI / Machine Learning / Deep Learning anzugehen.
Die Hauptvoraussetzungen für die technische Umsetzung sind Nvidia-GPUs mit den passenden Lizenzen. Die Liste der unterstützten Server ist sehr vielfältig und wir beraten unsere Kunden, damit für den jeweiligen Use Case die richtigen Komponenten ausgewählt werden. Anschließend wird im Hypervisor-System ein Treiber für die GPUs installiert. Es können auch mehrere Grafikkarten in einem Server verbaut werden, um die Leistung oder die Packungsdichte zu erhöhen. Gleichzeitig installiert man einen beziehungsweise wegen der Ausfallsicherheit besser zwei Lizenzserver. Auf diesen werden die Lizenzen für die einzelnen virtuellen Desktops oder Terminalserver vorgehalten.
Terminalserver?
Ja, auch Terminalserver profitieren von dem Einsatz von GPUs. Hier nutzen dann mehrere User die Leistung der GPU in den Terminalserver-Anwendungen.
Als letzter Schritt während der Implementierung erfolgt die Konfiguration der virtuellen Maschinen (VMs). Diese bekommen ein vGPU-Profil zugewiesen, um die GPU ansprechen zu können. Hier hat man die Wahl zwischen verschiedenen GPU-Speicherprofilen, um darüber die unterschiedlichen Use Cases zu adressieren. Innerhalb der virtuellen Maschine werden dann die Nvidia-Treiber installiert (Windows oder Linux). Der Nutzer hat damit Zugriff auf eine echte GPU. Jeder Benutzer, der einmal einen Desktop mit GPU benutzt hat, will niemals mehr ohne arbeiten.
Sehr viele unserer Kunden beschäftigen sich schon seit längerer Zeit mit diesen Themen. Kurz zusammengefasst: Man nutzt GPUs nicht für Grafik, sondern für komplexe Berechnungen. Bilderkennung ist dafür ein gutes Beispiel. Wie bringt man einem Computer bei, Bilder zu erkennen? Wie kann er entscheiden, ob es sich auf dem Foto um einen Hund oder eine Katze handelt? Für solche Bilderkennungsanwendungen gibt es spezialisierte Systeme mit vielen GPUs, diese sind aber sehr teuer in der Anschaffung. Wir nutzen die vGPU-Technologie als Einstieg in genau diese Themen. Somit kann man auf den GPUs, die man tagsüber für virtuelle Desktops verwendet, die Berechnungen ablaufen lassen.
Möchten Sie das selbst ausprobieren? Sprechen Sie uns an. Wir beraten und unterstützen Sie gern – egal, ob in der Theorie, jederzeit in einer Live-Demo, beim PoC oder zum Einsatz in der Produktion. Ihre Benutzer werden es Ihnen danken!
Nehmen Sie am virtuellen Nvidia GTC Event teil?
Das empfehlen wir Ihnen, wenn Sie sich für Nvidia und VDI interessieren. Marc Huppert, Principal Architect bei Computacenter, hält dort einen Vortrag genau zu diesen Themen. Wir würden uns freuen, wenn wir Sie dort (virtuell) treffen. Sollten Sie noch nicht registriert sein, können Sie gern unseren Promo-Code verwenden, mit dem Sie das Ticket 20 Prozent günstiger erhalten: „XDAgnwyjy4m“

Die explosionsartige Zunahme von Daten, die von Anwendungen innerhalb und außerhalb des Rechenzentrums erzeugt werden, stellt Unternehmen aller Größen vor die schwere Wahl, die Kapazität mit traditioneller IT-Architektur zu erhöhen oder mehr Arbeitslasten in Public Clouds zu verlagern. Beide Ansätze führen dazu, dass IT-Mitarbeiter oft mehr Zeit mit der Verwaltung einer komplexeren Infrastruktur verbringen als damit, Innovationen für das Unternehmen voranzutreiben. Doch das muss nicht sein.
Im Fokus steht dabei auch die Compliance bezüglich der Datensicherheit. Hier ist neben dem Datenmanagement der gesicherte Zugriff auf Daten und Applikationen über das Netzwerk essenziell. In klassischen On-Premises-Umgebungen finden wir dafür im Netzwerk auf den unteren Protokollebenen Firewalls, welche den Zugriff auf Daten und Applikationen zulassen oder verhindern. Um dies zu tun, muss der gesamte Netzwerkverkehr (also alle Datenpakete) zur Firewall, um dort analysiert und durchgelassen oder verworfen zu werden.
In kleineren Umgebungen ist dieses Vorgehen praktikabel, da die Netzwerklast in der Regel überschaubar ist.
In großen Umgebungen ist es jedoch komplexer. Um die Last zu bewältigen und eine Überlast zu verhindern, wird neben großen Firewalls oft auch eine Vielzahl von kleineren Firewalls eingesetzt. Die Bandbreiten müssen der Netzwerklast entsprechen und gegebenenfalls ist diese mittels Loadbalancern zu verteilen. Dies geht einher mit erhöhten administrativen Aufwänden für eine Vielzahl von Systemen, welche die Netzwerke segmentieren. Änderungen beanspruchen viel Zeit und verzögern gegebenenfalls die Bereitstellung von neuen Angeboten und Services. Wir sprechen hier von der Makro-Segmentierung. In modernen Umgebungen reicht diese aber nicht mehr aus, um den Anforderungen gerecht zu werden. Daher wächst der Bedarf an Micro-Segmentierung stetig.
Gartner prophezeite im Februar 2020: „Function Accelerator Cards Disrupting Traditional Ethernet Adapter Market.“ Hyperscaler und andere Cloud Service Provider verwenden Functional Accelerator Cards, um die Verfügbarkeit der Serverdienste und die Effizienz des Datentransports zu verbessern. Führende Hersteller von Halbleiterprodukten, die auf Netzwerkschnittstellen abzielen, sollten ihre Roadmaps umgestalten, um neue Netzwerkfunktionen zu integrieren und mit Dienstanbietern zusammenzuarbeiten, um die Konfiguration zu erleichtern.
Zusammen mit Pensando Systems bringt Hewlett Packard Enterprise eine solche Functional Accelerator Card auf den Markt. Damit verlagern sich die traditionellen Netzwerk- und Sicherheitsdienste im Rechenzentrum auf die Netzwerkkarte im Server, was Ihnen als Nutzer zahlreiche Vorteile bringt:
Der Serverhersteller HPE hat eine strategische Investition in Pensando getätigt. Die Technologie ist verfügbar für ausgewählte HPE-ProLiant-, HPE-Apollo-, und HPE-Edgeline-Server. Die Pensando Distributed Service Platform für HPE-Server bietet eine leistungsstarke Suite von softwaredefinierten Diensten wie Firewall, Mikro-Segmentierung und Telemetrie – direkt auf der Netzwerkkarte im Server.
Sie als Kunde erhalten mit der Pensando Distributed Service Platform eine Steigerung der Netzwerkleistung und mehr Sicherheit beim Zugriff auf die Daten und Applikationen, indem zum Beispiel die Firewall an der Stelle läuft, wo der Übergang zwischen Netzwerk und Server auftritt: auf der Netzwerkkarte. Damit ist gewährleistet, dass der gesamte Netzwerkverkehr eines Servers erfasst wird und die Lösung mit jedem weiteren Server automatisch skaliert.

Die Grundlage der Pensando-Plattform ist der Pensando-P4-Prozessor – ein maßgeschneiderter Prozessor, der für die Ausführung des Netzwerk-Softwarestacks optimiert ist. Die innovative Pensando-Technologie hat das Potenzial, den digitalen Transformationsprozess für Unternehmen weiter zu beschleunigen, da sie positiv auf die IT-Leistung, Automatisierung und die Sicherheit im Netzwerk des Rechenzentrums wirkt.
Sie haben Fragen zur Technologie und möchten weitere Informationen im Detail? Selbstverständlich steht Ihnen Ihr Ansprechpartner bei Computacenter zur Verfügung – gern auch für eine Live-Demo.

Die AWS Landing Zone Solution bietet eine enorme Flexibilität. Somit können alle Wünsche an ein Cloud Operating Model berücksichtigt werden. Und das Beste: Mit Computacenter als AWS Advanced Partner an Ihrer Seite erhalten Sie viel Erfahrung und Unterstützung, sodass die Implementierung einer Public Cloud in Ihre Unternehmens-IT reibungslos klappt.
„Funktioniert eine Public Cloud auch für unser Unternehmen? Und wie stellen wir sicher, dass die grundlegenden Anforderungen der IT und unsere Prozesse umgesetzt werden, wenn jeder etwas anderes nutzen möchte?“ Das sind zwei der Kernfragen, die sich jedes größere Unternehmen mit lang gewachsener IT und der dazugehörigen Prozessstruktur stellt, wenn es mit einer Public Cloud liebäugelt. Durch die Expertise unseres AWS-Teams, bestehend aus Architekten und Entwicklern, in Verbindung mit unserer Partnerschaft mit AWS können wir Ihnen die Antworten auf diese Fragen liefern.
Seit Amazon Web Services – kurz: AWS – Mitte 2018 die Landing Zone Solution vorgestellt hat, tauchten erste Leitfäden mit Herstellerunterstützung auf, wie ein Multi-Account Deployment im Unternehmenskontext unter Berücksichtigung allgemeingültiger Ansichten durchzuführen sei. Doch durch diese allgemeingültigen Ansichten tauchten mehr Fragen auf, als sie weiterhalfen, schließlich hat jeder Kunde seine ganz spezifischen Anforderungen, insbesondere hinsichtlich der Richtlinien im Unternehmenskontext. Somit kann auch keine Landing Zone Solution der anderen gleichen.
Wir haben aufbauend auf der Basis von AWS über die Jahre hinweg einen Baukasten definiert, den wir bei Interesse gern gemeinsam mit Ihnen im Rahmen der Anforderungsaufnahme besprechen. So definieren wir Schritt für Schritt und für alle Beteiligten Ihres Unternehmens vollkommen transparent Ihre individuelle Landing Zone Solution, die wir als AWS Advanced Partner auf Wunsch von der Konzeption bis zum Deployment im Lifecycle betreuen.
Der Vorteil der AWS Landing Zone Solution ist die vollkommene Flexibilität und die Berücksichtigung Ihrer Wünsche hinsichtlich eines Cloud Operating Models. Hierzu gehören auch die kontinuierliche Weiterentwicklung und die Nutzung von Neuerungen bei konkreten Features oder gar neuen Produkten im Einklang mit agilen DevOps-Methoden – getreu dem Motto „You build it, you run it!“.
Die erwähnte Flexibilität bietet natürlich auch die Möglichkeit, sich nicht von den On-Premises-Komponenten trennen zu müssen, sondern diese durch uns als Ihrem Partner für ganzheitliche und vor allem herstellerunabhängige IT-Lösungen in Ihre individuelle Landing Zone Solution integrieren zu lassen. So gelangen Sie in die komfortable Situation, dass Ihre IT sich nicht zwangsläufig in der Tiefe mit Public Cloud Services auseinandersetzen muss, sondern dass im Kontext der hybriden Multi-Cloud-Szenarien ein harmonischer Übergang zwischen den Welten geschaffen wird, bei dem sich jeder abgeholt und mitgenommen fühlt.
Wenn Sie befürchten, dass die Landing Zone Solution eine zu große Herausforderung darstellen könnte, oder wenn Sie sich nicht sicher sind, ob Sie diese vollkommene Flexibilität überhaupt benötigen, bieten wir Ihnen individuelle Workshops zu „Control Services on AWS“ an. Diese Workshops beleuchten insbesondere den Vergleich zwischen der beschriebenen AWS Landing Zone Solution und den Plattformdiensten „AWS Control Tower“ und „AWS Security Hub“ im Praxiseinsatz. Wo die Landing Zone Solution aus Kundensicht eher einer DIY-Erfahrung gleichkommt, gibt es bei der Kopplung von Control Tower und Security Hub eher einen fertigen Baukasten, aus dem man als Kunde in Zusammenarbeit mit uns die möglichen Vorgehensweisen und Richtlinien auswählt.
AWS arbeitet sukzessive daran, die Möglichkeiten der Landing Zone Solution in den Baukasten der Plattformdienste zu überführen. Dabei spielt das Feedback der Kunden und Partner eine große Rolle – etwa welche Art der Anpassungen im Rahmen eines Landing Zone Solution Deployments den Ausschlag gegeben haben, um zuerst den DIY-Weg zu beschreiten.
Sprechen Sie uns an, wenn Sie die Vorteile eine Public Cloud nutzen möchten, ohne sich von den On-Premises-Lösungen gänzlich loszusagen. Wir bieten Ihnen konkrete Antworten auf Ihre Fragen.

Modernisierung an sich ist nichts Neues, weder im privaten Bereich noch im Rechenzentrum. Seitdem Menschen IT-Systeme in Rechenzentren stellen, erneuern sie in unterschiedlichen Zyklen ihre Infrastrukturen, um diese an geänderte Anforderungen aus dem Business oder an technologische Entwicklungen anzupassen. Mit der richtigen Strategie und geeigneten Technologien und Services gelingt eine solche Modernisierung reibungslos.
Aktuell befinden sich Organisationen und IT-Verantwortliche in der sogenannten digitalen Transformation. Zum einen werden bestehende Prozesse Ende-zu-Ende digitalisiert, zum anderen werden ganz neue Applikationen entwickelt, um neue digitale Geschäftsmodelle zu unterstützen oder erst zu ermöglichen. Experten und Kunden sind sich mittlerweile einig, dass weder die Public Cloud noch die On-Premises-IT das alleinige oder vorherrschende Betriebsmodell sein kann. Die Verbindung von Vorteilen der On-Premises-IT und der Public Cloud Services wird zum bestimmenden IT-Betriebsmodell.
Darüber hinaus zeichnet sich heute schon ab, dass für moderne Applikationen nicht die eine Public Cloud benutzt wird. Vielmehr nutzen moderne Applikationen diverse Services aus unterschiedlichen IaaS-, PaaS- und SaaS-Angeboten. Zusätzlich werden Services aus der On-Premises-Umgebung ebenso wie Services aus den Public Clouds eingebunden. Solche Umgebungen werden über ein Multi-Cloud-Managementsystem verwaltet. Damit kann die moderne On-Premises-IT einfach als ein weiterer Cloud-Standort interpretiert werden.
Eine wie oben beschriebene Umsetzung funktioniert nur, wenn IT-Systeme und -Services ähnlichen oder den gleichen Mechanismen wie Services in den Public-Cloud-Umgebungen folgen. Diese sind insbesondere von Automatisierung und Konsumption gekennzeichnet. Die komplette On-Premises-IT so aufzubauen, widerspricht jedoch der heutigen Realität. Zum einen finden sich in den Rechenzentren über Jahrzehnte gewachsene Infrastrukturen und Prozesse, zum anderen sind eine Vielzahl der heute betriebenen Applikationen monolithisch, also nicht in Services oder gar Microservices unterteilbar. Hier gibt es drei Optionen für den zukünftigen Betrieb oder Weiterbetrieb:
Untersuchungen gehen davon aus, dass etwa 15 bis 30 Prozent der heute betriebenen Applikationen über einen Zeitraum von bis zu 10 Jahren im bisherigen Betriebsmodell weiterzubetreiben sind. Ungefähr 40 bis 50 Prozent der Software werden durch neue Applikationen ersetzt, entweder durch ganz neue Business-Applikationen oder durch Standard-SaaS-Angebote. Bei nur 15 bis 20 Prozent der Bestandsapplikationen gelingt mit einem vertretbaren Aufwand die Portierung auf eine serviceorientierte Applikationsarchitektur.
Demnach verbleiben bis zu einem Drittel der heute eingesetzten Applikationen bis zum Ende ihres LifeCycle im heutigen RZ-Betrieb. Genau für diese Applikationen sind im Rechenzentrum die Bestandssysteme einem normalen Infrastruktur-LifeCycle zu unterziehen, also bei Bedarf zu modernisieren.
Man kann sich das wie eine Modernisierung im privaten Umfeld vorstellen. Wir bauen ein Haus und passen es nach und nach an unsere Bedürfnisse an. Von Zeit zu Zeit müssen neben der jährlichen Wartung und Instandsetzung aber auch größere technologische Veränderungen stattfinden. Aus einem Heizungskessel wird dann ein moderner energieeffizienter Brennwertkessel, aus einem Röhrenfernseher wird ein Flachbildschirm. Die Art der Nutzung, oder übersetzt des Betriebes, ändert sich dabei nicht. Wir erwarten nach wie vor warmes Wasser in einem festgelegten Temperaturbereich oder schauen immer noch Fernsehen – vielleicht etwas mehr als wir sollten.
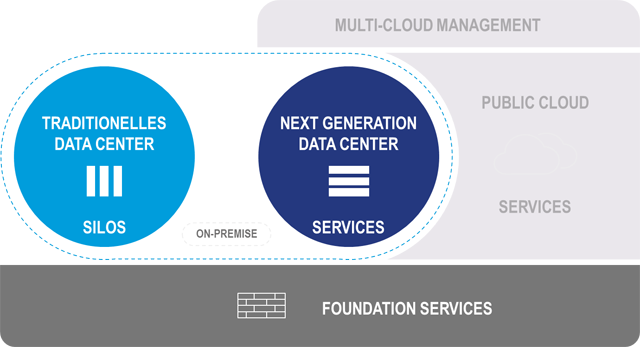
Im Rechenzentrum haben wir es vor allem mit Technologien in den Bereichen Compute, Netzwerk, Speicher, Virtualisierung und Container zu tun. Natürlich kümmern sich die Verantwortlichen auch um Applikationen, Datenbanken und Service-Prozesse. Aber bleiben wir für einen Moment bei der Infrastruktur.
Modernisierungen im Bestand sind vor allem technologisch bedingt. Das zugrunde liegende Betriebsmodell wird nicht verändert. Die einzelnen Betriebseinheiten Netzwerk, Speicher, Compute und Virtualisierung/Container erneuern (modernisieren) periodisch ihre Systeme. So kommen Server mit der neusten CPU-Generation, Netzwerk-Switches mit mehr Bandbreite und Speichersysteme mit Flash statt Festplatten in das Rechenzentrum.
Die Modernisierung im Bestand verfolgt dabei die Ziele Erneuerung, Stabilität, Wachstum und Kosteneffizienz. Kunden profitieren in der Regel neben der Partizipation an technologischen Weiterentwicklungen auch von veränderten Liefermodellen. In den vergangenen Jahren haben die Schnelligkeit bei der Beschaffung und der Erst-Inbetriebnahme an Bedeutung gewonnen. In der Regel sind in einer IT-Plattformlösung mehrere Herstellersysteme verbaut. Bei der Aktualisierung der Systeme stehen Kunden dann regelmäßig unterschiedlichen Laufzeiten, komplexen Abhängigkeiten der Systeme untereinander und letztendlich auch unterschiedlichen Lieferzeiten der Komponenten gegenüber.
Computacenter liefert mit „Rapid Datacenter Deployment“, „Zero Touch Deployment“ und „Multi Vendor Maintenance Support“ Service-Dienstleistungen, die die oben geschilderten Herausforderungen adressieren.
Mit dem Rapid Datacenter Deployment, auch „Rack&Roll” genannt, lassen sich alle logistischen Herausforderungen bei der Integration neuer IT-Systeme meistern. Neben der Multi-Vendor-Integration im Logistik-Center in Kerpen werden nach kundenindividuellen Blueprints auch Themen wie eine verpackungslose Anlieferung sichergestellt.
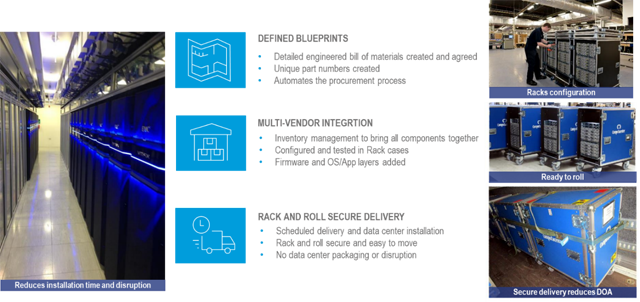
Im Ergebnis profitieren Kunden von den stark verkürzten Bereitstellungszeiten der IT-Systeme und Plattformen und kommen so besonders schnell einen weiteren Schritt Richtung Industrialisierung ihrer IT-Infrastruktur voran.
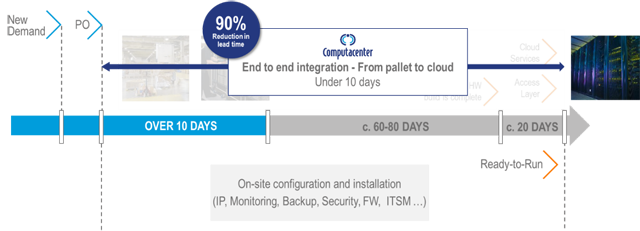
Beim Zero Touch Deployment wird das Ziel verfolgt, Systeme automatisiert in Bestandsumgebungen zu integrieren. Ist die Automation im Rechenzentrum bei einzelnen Systemen noch überschaubar, so werden in einer Multi-Vendor-IT-Plattform die Abhängigkeiten schnell sehr komplex. Mit einem Multi-Vendor Infrastructure Automation Framework auf Basis von RedHat Ansible / Ansible Tower ist es uns möglich, gängige Hersteller-Hardware für das Rechenzentrum in einem IaC-Modell (Infrastructure as Code) integrativ für die Installation und Integration (Day0 und Day1 Operation) zu automatisieren.
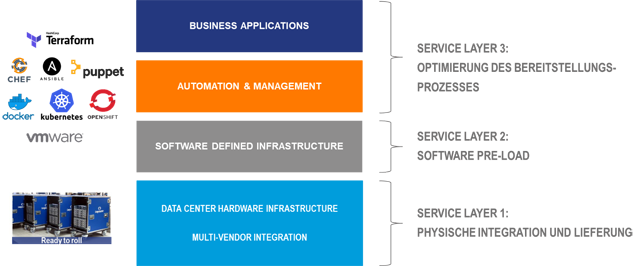
Die Komplexität des Managements von Herstellerverträgen und der Sicherstellung von Support-SLAs steigt linear mit der Anzahl der Hersteller, deren Systeme vom Kunden betreut werden. Doch die Herausforderung liegt nicht nur in der Anzahl, jeder Herstellervertrag funktioniert zudem nach ganz eigenen Spielregeln. Der Ansatz des Multi-Vendor-Maintenance-Service zielt auf ein Ende-zu-Ende-Management und die Kapselung der Servicekomplexität für den Kunden ab.
Neben der Modernisierung im Bestand finden auch neue Plattformen Einzug in die Rechenzentren. Hier handelt es sich meist um Infrastruktur, die ein neues Betriebsmodell besser unterstützt, als es die Bestandsinfrastrukturen tun können. NGDC-Infrastrukturen sind gekennzeichnet von einer Technologiekonsolidierung und der Ausrichtung des Betriebsmodells auf den zu liefernden Service statt auf Technologie. Aus Anwendersicht ist es egal, ob und wie der Bereich Speicherbetrieb oder Netzwerkbetrieb organisiert ist. Nutzer erwarten den Service Infrastruktur als IaaS und beispielsweise SAP als Applikation per Software as a Service (SaaS).
Für den IaaS-Service werden natürlich immer noch die Expertenthemen Compute, Netzwerk, Speicher und Virtualisierung benötig. Die neue Qualität besteht darin, dass die einzelnen Technologien des Infrastrukturbetriebes gebündelt werden, um den Nutzer über eine übergreifende Zusammenarbeit den Service Infrastruktur als Gesamtheit zur Verfügung zu stellen. Die konsequente und vollständige Automatisierung des Betriebs und die ausschließliche Serviceorientierung sind dem Betriebsmodell von HyperScalern (Public Cloud Providern) sehr ähnlich. Tatsächlich sind ähnliche Grundprinzipien, nämlich das Verständnis von Services und die Umsetzung der Kommunikation über Schnittstellen (API), eine zwingende Voraussetzung dafür, die On-Premises-Systeme in eine Multi-Cloud-Umgebung zu integrieren.
Damit ist es aus Sicht des Nutzers (Anwenders / Applikation) möglich, auf Basis von unternehmensweiten Regeln pro Applikation oder Service zu entscheiden, wo das Sourcing der Infrastruktur stattfindet. Es können ökonomische Fragestellungen oder solche rund um Compliance sein, die das Deployment der Applikationen entweder in Richtung NGDC oder Public Cloud ausrichten.
Die Konsolidierung der Technologien Compute, Netzwerk und Speicher findet oft auf der Basis softwarebasierter Technologien statt. Auf einem x86-Server-Block werden alle anderen Technologien über Virtualisierungstechniken realisiert. Software Defined X (SDx) ist hier das Schlagwort. Das „X“ steht für die jeweilige Technologie: Domaine Compute (SDC – Software Defined Computing oder Servervirtualisierung), Networking (SDN – Software Defined Networking) und Storage (SDS – Software Defined Storage). Mit entsprechendem Monitoring, Workflow, Automatisierungs- und Inventory-Funktionen bildet das SDDC – Software Defined Datacenter – die Klammer um alle Infrastrukturbausteine.
Der Betrieb und die Ausgestaltung solcher Umgebungen orientieren sich am ganzheitlichen Infrastrukturservice für den Nutzer und sind geprägt vom Arbeiten mit wiederverwendbaren Polices über Technologie-Domaingrenzen hinweg. Eine gemeinsame Verantwortung aller beteiligten Infrastrukturbereiche für die Serviceerbringung gehört zum Rollenmodell eines dienstleistungsbezogenen IT-Providers.
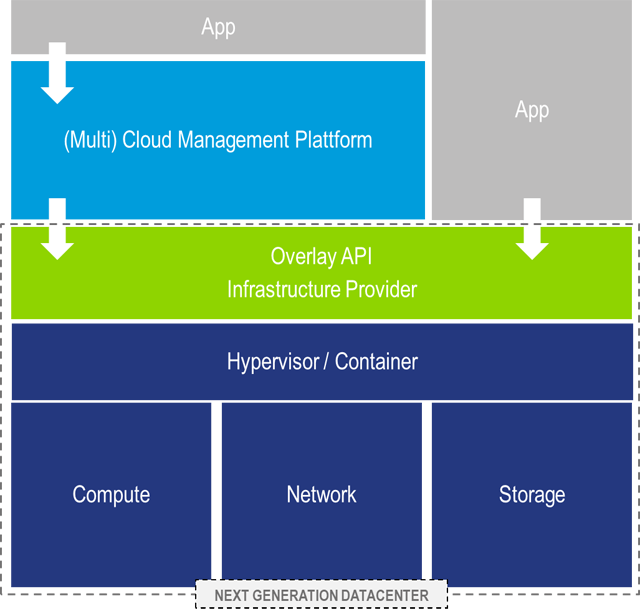
Ein wie hier beschriebenes NGDC ist ein modernes Infrastruktur-Serviceangebot, welches auf der einen Seite IaaS-Services für Multi-Cloud-Managementsysteme zur Verfügung stellt und auf der anderen Seite modernen, neuen Webapplikationen ermöglicht, Infrastrukturressourcen direkt in Software-Code (IaC – Infrastructure as Code) zu beschreiben und für ihre Belange automatisiert anzufordern.
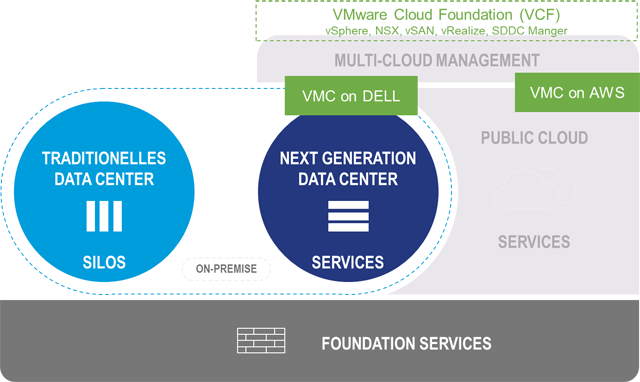
Ein praktisches Beispiel für die Umsetzung der skizzierten Architektur ist der Einsatz von Produkten aus den Häusern VMware und DELL Technologies.
VMConAWS (VMware Cloud on AWS) ist ein schon länger verfügbares IaaS-Angebot von VMware für den Betrieb von vSphere Clustern bei AWS. VMConDELL (VMware Cloud on DELL) ist ein in Europa neuer Service, der es Kunden ermöglicht, Betriebsdienstleistungen von vSphere Clustern im eigenen Rechenzentrum durch VMware analog dem AWS-Modell betreiben zu lassen. Die Infrastruktur-Hardware kommt in diesem Fall aus dem Hause Dell Technologies in Form von HyperConverged Systemen (VxRail). Die Verbindung der NGDC-Plattform im Rechenzentrum des Kunden mit der Cloud-Instanz des Kunden auf AWS erfolgt über das Produktbundel VMware Cloud Foundation (VCF).
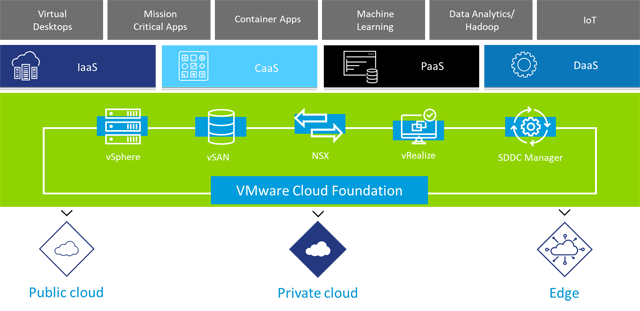
Zusammenfassend können wir feststellen, dass Modernisierung im Rechenzentrum sowohl in der Bestands-IT als auch im Bereich neuer softwarebasierter Infrastrukturplattformen stattfindet.
Möchten Sie mehr über die Möglichkeiten der Modernisierung in Rechenzentren wissen oder haben Sie konkrete Fragen zu Ihrem Modernisierungsbedarf? Dann wenden Sie sich am besten gleich an Ihren Ansprechpartner bei Computacenter, der Ihnen gern weiterhilft. Für den Fall, dass Sie sich vorab noch etwas detaillierter über unsere Services rund um das Thema „Modernise the Data Center“ informieren möchten, haben wir hier weitere Informationen für Sie zusammengestellt.

Bei einer auf den ersten Blick simplen Frage tappen viele Unternehmen im Dunkel: „Gibt es eine konsistente Datensicherung gemäß unseren Servicevereinbarungen?“ Die Suche nach der Antwort kann plötzlich Licht in viele Schattenwelten werfen.
In jedem Unternehmen findet sich eine Abteilung, welche die zentrale Datensicherung verantwortet und primärer Ansprechpartner ist, wenn es darum geht, Berichte über erfolgreiche Backups und Wiederherstellungstests zu erhalten. Hier werden unternehmensweite Datensicherungslösungen und die notwendige Hardware betrieben – hochverfügbar, redundant und unter Berücksichtigung der Sicherheits- und Datenschutzstandards.
Sieht man jedoch genauer hin, finden sich im Schatten eine Reihe weiterer Sicherungsverfahren, die nicht in der Verantwortung und Kontrolle dieser Abteilung liegen.
In jedem Projekt im Rahmen der Computacenter-Methodik Backup Service Katalog (BSK) besteht der Anspruch, die Backup-Workflows zu identifizieren und einer Verantwortung zuzuordnen.
Für die zwei weiteren Schatten-Workflows muss die Frage an das NAS/Storage-Team beziehungsweise an das Datenbank-Team gerichtet werden.
Neben der Frage nach dem Erfolg der Datensicherung stellen sich auch Fragen in Richtung erfolgreicher Restore-Tests und zum Einhalten der Sicherheits- und Datenschutzstandards.
Auf der technischen Ebene und stellenweise verknüpft mit einer zentralen Jobsteuerung mag eine gewisse Transparenz herrschen – aber de facto sind in Bezug auf die Datensicherung die Zuständigkeiten meistens nicht klar dokumentiert (siehe auch BSI IT-Grundschutz CON3.A10 – Verpflichtung der Mitarbeiter zur Datensicherung) und nicht transparent.
In den Projekten finden sich immer mehr als drei Backup-Workflows und in manchen Kundensituationen sogar mehr als zehn verschiedene Zuständigkeiten. Das bedeutet, im Kontext der Datensicherung bestehen in Unternehmen viele Schattenwelten.
Es bedeutet jedoch nicht, dass mehrere getrennte Backup-Workflows nicht sinnvoll und effizient sein können – denn warum sollten beispielsweise Petabyte an NAS-Daten in eine zentrale Datensicherung einfließen? Das wäre in Bezug auf Kosten und Einhaltung der SLAs nicht unbedingt sinnvoll. Aber es ist wichtig, hier eine Transparenz und Zuordnung zu schaffen, damit die unternehmenskritischen Daten immer geschützt sind.
Public-Cloud- und Software-as-a-Service-Angebote erreichen auch in Deutschland eine zunehmende Verbreitung und Akzeptanz. Daher stellt sich die Frage, ob solche Plattformen in Bezug auf die Datensicherung und die verschiedenen Backup-Workflows eine Verbesserung bieten.
Dazu ist grundsätzlich festzuhalten: Die Verantwortung für die Daten und die Sicherheit sowie den Schutz der Daten obliegt auch hier immer dem Unternehmen und nicht dem SaaS-Anbieter oder Cloud Provider.
Ein Beispiel ist unter anderem Salesforce, die am 31.07.2020 einen Wiederherstellungsservice nach Best Effort für die Kundendaten eingestellt haben und explizit darauf verweisen, dass dies in der Verantwortung der Kunden liege (siehe auch hier). Dieses Beispiel lässt sich auf die meisten Cloud Services ausdehnen.
Somit tritt bei der Verwendung von Public Cloud Services keine Verbesserung in Bezug auf das Wiederherstellungsmanagement ein – im Gegenteil: Durch den Einsatz und die Nutzung solcher Services erhöht sich die Anzahl der Backup-Workflows und potenziell der Schattenwelten.
In der modernen hybriden Welt unter Einbindung verschiedenster Public-Cloud- und SaaS-Lösungen ist der Aufbau einer durchgängigen Datenmanagement-Strategie und darin enthalten der Backup- und Archivierungs-Strategie wichtig und notwendig. Das erfordert erstens eine Transparenz und ein Verständnis, wo welche Daten in welcher Verantwortung existieren und abgesichert werden. Und zweitens ist dann der Aufbau einer Plattform nötig, die diese Transparenz um die notwendigen Kontrollen und Schutzmaßnahmen ergänzt.
Wenn Daten das Öl der modernen hybriden Welt sind, dann ist die Datenmanagement-Strategie der Schutzwall für die Daten, damit diese nicht unkontrolliert auslaufen.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zum Datenmanagement und zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

Hyperscaler und Anbieter von Public-Cloud-Architekturen liefern eine beeindruckende Innovationsrate und stellen Funktionen und Services bereit, mit denen sich die digitale Transformation beschleunigen lässt. Zudem ist es für DevOps-Teams sicherlich einfacher, Anwendungen und Ressourcen auf einer dedizierten Plattform oder Public Cloud zu entwickeln und zu betreiben, als einen Multi-Cloud-Ansatz oder eine hybride Architektur zu fahren. Was spricht dafür und was dagegen? Gedanken aus Kundengesprächen.
Entwickler lieben Cloud Services, bei denen die notwendigen Ressourcen und Services sofort verwendet werden können. Gerade in der agilen Entwicklung ist die Möglichkeit, neue Ideen schnell und einfach auszuprobieren, extrem wertvoll und hilfreich. Traditionelle IT-Organisationen leiden unter dem Ruf, dass ein Provisionieren von Ressourcen oft Wochen oder Monate dauert. In der Cloud funktioniert dies im Self Service oder gesteuert über eine Automation – einfach und effizient.
Entwickler suchen Innovation aber übergreifend zu den verschiedenen Hyperscalern und Cloud Providern. Konkret möchten Kunden aus verschiedenen Clouds die jeweils besten und effizientesten Services flexibel in einem Multi-Cloud–Szenario konsumieren können. Gleichzeitig werden existierende Lösungen aus Open Source Communities und Upstream-Projekten genutzt – denn warum sollte man das Rad neu erfinden, wenn eine große Open Source Community hierzu bereits Lösungen und Algorithmen kostenfrei anbietet und diese schnell in die neuen Applikationen integriert werden können?
Daher bietet es sich an, den Entwicklungsteams eine flexible Plattform für eine Cloud-übergreifende Entwicklung von modernen und Cloud-nativen Applikationen anzubieten und Algorithmen und Bausteine aus der Open Source Community nutzbar zu machen.
Intelligent gebaut und automatisiert kann eine solche Plattform für Cloud-native Applikationen den Entwicklern sowohl Geschwindigkeit als auch Flexibilität bieten und gleichzeitig die Nutzung der verschiedenen Cloud Provider und eigener Rechenzentren erlauben.
Aber Entwicklungsteams fokussieren sich auf Business-Nutzen und Applikationen – weniger auf die Frage, welche Hürden für diese Services auf dem Weg in die Produktion und den Regelbetrieb genommen werden müssen.
Natürlich müssen an dieser Stelle die Themen Compliance und Datensicherheit aufgegriffen werden, speziell die Herausforderungen durch den Cloud Act, der US-Unternehmen vorschreibt, auch ohne richterlichen Beschluss ermächtigten US-Behörden auf Anforderung Daten zu übergeben – darunter solche, die außerhalb der USA gespeichert sind. Das erfordert eine kritische Bewertung seitens der Unternehmen.
Doch welche weiteren Hürden existieren neben der Compliance und dem Datenschutz?
Hierzu zwei Geschichten aus dem Jahr 2020:
In einem Projekt nutzte der Kunde einen Public Cloud Provider und hatte mehrfach Schwierigkeiten, die Plattform für die in der Produktion befindliche Applikation zu skalieren. Das lag an fehlenden Ressourcen in der Region bei dem spezifischen Provider. Mit einer erheblichen Zunahme der Cloud-native Workloads und den dynamischen Skalierungsanforderungen ist es nicht auszuschließen, dass solche Situationen zukünftig häufiger auftreten können. Daher ist eine Strategie sinnvoll, die eine Skalierung über verschiedene Cloud Provider und Regionen ermöglicht. Das lässt sich durch eine zukunftsweisende Architektur für eine hybride oder Multi-Cloud-Plattform erreichen. So nutzt ein anderes Projekt primär Ressourcen in eigenen Rechenzentren – auch wegen der Datenklassifikation –, aber skaliert quartalsweise dynamisch 1.000+ Cores für eine kurze und intensive Datenanalyse bei einem Cloud Provider – und zwar dort, wo die Ressourcen gerade wirtschaftlich verfügbar sind.
Werfen wir einen Blick in eine andere Richtung zu einem stark regulierten Unternehmen. Es betreibt geschäftskritische und nach außen hin exponierte Applikationen und hatte Ausfälle zu beklagen – bedingt durch die darunterliegende Public-Cloud-Infrastruktur. Die Zielsetzung besteht hier darin, eine Desaster-Recovery-Fähigkeit über zwei verschiedene Public Cloud Provider zu etablieren – welche aber möglichst einfach durch die Entwicklungsteams genutzt werden können sollen, was eine entsprechende Abstraktion und Architektur erfordert.
Die Frage muss sich jedes Unternehmen stellen und die eigene Antwort finden. Cloud-native Applikationen basieren auf einer Architektur, die unabhängig von der darunterliegenden Infrastruktur ist und die somit sowohl in einer privaten als auch in einer Public Cloud ausgerollt werden kann. Sie zeichnet sich durch Eigenschaften wie Scale-out anstelle von Scale-up aus und verfügt über eine integrierte Redundanz durch das Starten mehrere Instanzen der gleichen Komponenten.
Diese modernen Applikationen können schnell in einer Cloud entwickelt werden – aber reicht mittelfristig eine Cloud dazu aus oder ist der Multi-Cloud-Weg die bessere Lösung?
Zusammengefasst sind in diesem Artikel dazu ausgewählte Fragen aufgeworfen worden:
Computacenter unterstützt Sie gern dabei, die passenden Antworten auf diese und weitere Fragen zu finden und anschließend eine passende Architektur für die modernen Cloud-nativen Applikationen zu etablieren, umzusetzen und zu betreiben. Wenden Sie sich bei Interesse einfach an Ihren Ansprechpartner bei Computacenter.