Von der Innovation zur Effizienz mit Cloud-Plattformen

Die Public Cloud hat Unternehmen zahlreiche Innovationen bei der eigenen IT-Umgebung und bei der Erbringung digitaler Services ermöglicht. Doch wie lässt sie sich bestmöglich in die IT-Strategie einbinden? Wie lassen sich die Innovationsvorteile von Cloud-Lösungen mit der Effizienz traditioneller IT vereinen? Antworten auf diese Fragen finden Sie in dieser aktuellen Ausgabe des Datacenter-Newsletters.
Rechenzentren sehen sich der massiven Herausforderung gegenüber, Energie zu sparen, ihre Emissionen zu senken und mit Prozessressourcen effizienter umzugehen. Wie das am besten gelingt, erläutern wir in unserer Artikelreihe zum Thema nachhaltige IT. Dieses Mal stellen wir Ihnen in Teil 2 der Reihe konkrete Maßnahmen vor.
Die meist in den 2000er-Jahren entstandenen Rechenzentren vieler Unternehmen sind geographisch verteilt und genügen in vielen Fällen nicht mehr den Anforderungen an einen modernen Betrieb. Eine Konsolidierung der Rechenzentren ist daher unausweichlich. Wir erläutern Ihnen, mit welchen Schritten Sie diese erfolgreich meistern.
Die ProLiant Server der 11. Generation von Hewlett Packard Enterprise (HPE) liefern eine herausragende Performance und ausgeklügelte Sicherheit. Wir stellen die aktuellen Modelle vor und zeigen, was bei deren Einsatz zu beachten ist.
Unsere aktuelle Agile-IT-Kolumne beschäftigt sich mit der Verantwortung in interdisziplinären Teams. Lesen Sie, wie diese die Verantwortung am besten aufteilen, damit Prozesse schnell umgesetzt werden können, gut funktionieren und so zum Erfolg und zur Wertschöpfung des Unternehmens beitragen.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Computacenter ist mit dem „HP Security Partner of the Year“ Award für Deutschland ausgezeichnet worden.
Weitere InfosDie Computacenter plc. hat heute ihre Geschäftsergebnisse für das Jahr 2022 bekannt gegeben. So stieg der Umsatz in Deutschland bei konstanten Wechselkursen um 18,6 Prozent.
Weitere Infos
Jessica Linke, Christian Schreiner
Die Public Cloud hat Unternehmen zahlreiche Innovationen bei der eigenen IT-Umgebung und bei der Erbringung digitaler Services erst ermöglicht. Doch wie lässt sie sich bestmöglich in die IT-Strategie einbinden? Wie lassen sich die Innovationsvorteile von Cloud-Lösungen mit der Effizienz traditioneller IT vereinen? Wir haben die Antworten.
Unternehmen hatten in den letzten Jahren einen hohen Innovationsdruck, dem sie mit der hocheffizienten Struktur der traditionellen IT nicht gerecht werden konnten. Viele Fachabteilungen sind folglich, auch im Bewusstsein eines Effizienzverlustes, auf andere Erbringungsformen wie die Public Cloud ausgewichen. Gänzlich neue Skills mussten aufgebaut werden, vielfach in verschiedenen Abteilungen eines Unternehmens parallel. Für diese entstandenen Silos – wie zum Beispiel die Nutzung unterschiedlicher und nicht abgestimmter Cloud Provider – mussten folglich bisherige zentrale Services dediziert, individuell passend und dezentral neu aufgebaut werden.
In der traditionellen IT fokussierte man sich in den letzten Jahren vermehrt auf die kontinuierliche Verbesserung der vorhandenen Infrastruktur. Primär ging es darum, die Systeme effizient zu betreiben. Hierbei mussten sich Applikationsarchitekturen oft an die Möglichkeiten, die im Rahmen der IT-Infrastruktur geboten waren, anpassen. Eine grundlegende Veränderung in der Art und Weise der Bereitstellung und des Betriebes waren lange Zeit eher die Ausnahme. Das galt damit aber auch für den Grad der Innovationsmöglichkeiten der Unternehmen auf Basis von digitalen Services.
Mit Aufkommen der Public-Cloud-Angebote hat sich das gewandelt. Nicht nur, dass IT-Leistungen wie Software, aber auch Rechenkapazitäten, Datenbanken oder auch Speicher nun „on demand“ zur Verfügung standen, sondern es wurden durch die Cloud Provider auch zunehmend komplexere IT-Services angeboten, was es den Entwickler:innen einfacher machte, den Endnutzer:innen neue Applikationen und Services bereitzustellen. Immer mehr Unternehmen haben in den letzten Jahren ihre IT-Ressourcen in die Public Cloud verlagert. Damit sind Daten und Anwendungen von jedem Ort auf der Welt und rund um die Uhr zugänglich. So, wie Sie es vermutlich auch aus Ihrem Nutzungsverhalten als Privatanwender:in kennen. Strom kommt aus der Steckdose und IT-Anwendungen aus der Cloud.
Ebenso wie wir als Anwender:innen haben auch Unternehmen erkannt, dass die Nutzung von Cloud-Ressourcen eine bessere Skalierbarkeit und vor allem die schnelle Bereitstellung von Anwendungen und Ressourcen ermöglicht. Dies schafft neben der notwendigen Flexibilität vor allem die Möglichkeit, den eigenen Kund:innen auf Basis der vorhandenen Daten immer wieder neue Services zur präsentieren und sich damit von der Konkurrenz abzuheben.
Wir nennen das die erste Cloud-Welle, in der durch die Entwickler:innen und/oder Fachabteilungen innovative Ansätze und Lösungen geschaffen wurden. Dies führte zu einem Verlust der hohen Effizienz, die in der eigenen IT jahrelang forciert wurde.
Um dies mit einem einfachen Beispiel zu verdeutlichen: Stellen Sie sich vor, Sie möchten eine Website hosten, die auf einem Server ausgeführt wird. Wenn Sie sich für die Bereitstellung im eigenen Rechenzentrum entscheiden, benötigen Sie die geeigneten Räumlichkeiten, Stromversorgung, Klimatisierung und Netzwerkinfrastruktur. Auch die notwendige Server-Hardware muss gekauft, installiert und konfiguriert werden. Zudem muss sichergestellt werden, dass ausreichende Sicherheitsmaßnahmen implementiert sind, um die Server und Daten zu schützen. Damit das Rechenzentrum permanent einsatzbereit ist, müssen Sie sich darüber hinaus um die laufende Wartung, Aktualisierung und Skalierung der Hardware kümmern. Dies beinhaltet die Überwachung der Serverleistung, den Austausch defekter Hardware, die Sicherung der Daten und die Gewährleistung der Verfügbarkeit der Website.
Wenn Sie sich jedoch für die Nutzung der Public Cloud entscheiden, müssen Sie keinen physischen Standort für Ihr Rechenzentrum verwalten. Stattdessen erstellen sie ein Konto bei einem der Cloud-Service-Anbieter wie Amazon Web Services (AWS), Microsoft Azure oder Google Cloud. Dort richten sie virtuelle Maschinen oder Container ein, um die Website auszuführen. Der Cloud-Anbieter übernimmt die Verantwortung für die physische Infrastruktur, einschließlich Standort, Stromversorgung und Netzwerk. Sie müssen sich nicht um die Beschaffung, Installation und Wartung der Hardware kümmern. Der Cloud-Dienstleister bietet auch Funktionen wie automatische Skalierung, Sicherheitsmaßnahmen und Datensicherung. Zudem zahlen Sie nur für die Ressourcen, die Sie tatsächlich verwenden.
Der Hauptunterschied besteht also darin, dass Sie beim eigenen Rechenzentrum die physische Infrastruktur und die gesamte Verantwortung für den Betrieb übernehmen, während Sie in der Public Cloud die Infrastruktur eines Cloud-Anbieters nutzen und sich auf die Verwaltung Ihrer Anwendungen konzentrieren können.
Eine andere Möglichkeit, Cloud Services zu nutzen, ist die Konsumierung von SaaS-Lösungen, also das Ersetzen von On-Premises-Lösungen durch SaaS-Applikationen. Hier sind Effizienz und Innovation bereits optimal aufeinander abgestimmt. Als Beispiele hierfür wären Applikationen wie Teams, Office 365 oder CRM- und ERP-Lösungen zu nennen.
Der technologische Fortschritt hat in den letzten Jahren enorm an Fahrt aufgenommen. Hinzu kommt, dass durch das Internet der Dinge nach und nach alles miteinander vernetzt wird. Damit Unternehmen auch zukünftig diese Herausforderungen meistern können, gehört die Nutzung von Public-Cloud-Ressourcen als wichtigste Technologie unabdingbar zur Digitalisierungsstrategie. Dies bedingt aber auch, dass man den Fokus wieder auf die Erhöhung der Effizienz legen muss, da diese Umgebungen inzwischen einen erheblichen Anteil an der gesamten IT-Landschaft ausmachen.
Der nächste große Schritt nach dem gezeigten Innovationssprung ist daher nun der Effizienzsprung im IT-Betrieb der Cloud-Umgebungen. Mithilfe von Cloud-Plattformen wird in der zweiten Welle der Cloud-Nutzung nun die Verbesserung der Effizienz des Applikationsbetriebs innerhalb von Cloud-Betriebsmodellen vorangetrieben – als Beispiel sind hier die Bereitstellung zentraler Services, die für diese neuen Betriebsmodelle benötigt werden, und die Containerisierung von Applikationen genannt. Der Betrieb bei einem einzigen Hyperscaler ist dabei keineswegs fest in Stein gemeißelt, stattdessen ist auch eine Prüfung der optimalen Betriebsumgebung ein Bestandteil der Deployment-Entscheidung. Public Cloud, Hybrid Cloud, Colocation oder klassische On-Premises-Umgebungen werden so kombiniert, dass eine optimale Betriebsumgebung entsteht, die den Bedürfnissen und Anforderungen der Kund:innen und der Applikationen entspricht. Das Ergebnis: Die Effizienz traditioneller IT wird mit den Innovationsvorteilen von Cloud-Lösungen vereint.
Die Positionierung der IT-Organisation spielt ebenfalls eine entscheidende Rolle. Mit dem Cloud-Einsatz verändern sich in der Regel Betriebsmodelle, Anbietersteuerung, Serviceintegrationen aber auch der Support der eigenen Organisation und Fachabteilungen. Die unternehmenseigene IT-Abteilung wächst in die Rolle eines internen Dienstleisters, der die genannten zentralen Services bereitstellt und als Partner die Fachabteilungen berät, um ihnen einen optimalen Einstieg in diese „neue Welt“ zu bieten. Die IT-Abteilung wächst somit mehr und mehr in die Rolle eines Service Providers und wird damit zum zentralen Dreh- und Angelpunkt für das Business eines Unternehmens.
In den letzten Jahrzehnten haben wir vielen unserer Kunden als Partner zur Seite gestanden, vom Rechenzentrumsaufbau über den Betrieb bis hin zur Integration von Systemen und Applikationen. Dabei haben sich unsere Standards und Vorgehensmodelle als zentrale Komponente für die erfolgreiche und schnelle Umsetzung der Ziele unserer Kunden bewährt. Diese Erfahrung haben wir in den vergangenen Jahren auf unsere Partner im Bereich der Public-Cloud-Anbieter erweitert. Denn die Welt ist hybrid. Die Nutzung eigener Rechenzentrums-Ressourcen wird in großen Teilen auch weiterhin notwendig sein, doch in Kombination mit Public-Cloud-Ressourcen entstehen zahlreiche Vorteile, auf die man nicht verzichten sollte. Wir kennen beide Welten und können Sie auf Ihrem Weg der Effizienzsteigerung optimal unterstützen. Wenden Sie sich dazu am besten gleich an Ihre:n Ansprechpartner:in bei Computacenter.

Ulf Schade
In der vorigen Ausgabe haben wir Ihnen eine Einführung in die Themen Green IT und Sustainable IT gegeben und vier Spielfelder genannt, mit denen sich Energie sparen und Emissionen reduzieren lassen. Diese vier Spielfelder stellen wir Ihnen in dieser Ausgabe genauer vor.
Die im Folgenden beschriebenen Maßnahmen haben keinen Anspruch auf Vollständigkeit, sondern sind Beispiele, die in der Praxis von Green-IT-Umsetzungsprojekten häufiger vorkommen. Für die individuelle Green-IT-Umsetzungs-Roadmap sind gegebenenfalls weitere Ansätze in die Bewertung einzubeziehen. Mit dem in der vorigen Ausgabe beschriebenen Blueprint der Messung und Bewertung sollte dies problemlos möglich sein.
Eine schnelle und einfache Art die Energieversorgung für Datacenter „grüner“ zu machen, ist der Kauf von Ökostrom. Bei dem Energiebedarf der Datacenter ist das Potenzial zur Verringerung von GHG-Emissionen sehr hoch. Die Umsetzung ist kurzfristig realisierbar. Allerdings gibt es nicht nur Vorteile. Ökostrom hat im Energiemix in Westeuropa heute einen Anteil von 38 Prozent (in Deutschland sind es 42 Prozent). Wenn große Industrienutzer wie Datacenter ihre Stromversorgung auf Ökostrom umstellen, verknappen sie das Angebot – und damit steigt der Preis für die vielen Millionen Privatnutzer:innen, die auch ihren Beitrag zu mehr Nachhaltigkeit leisten wollen.
Eine Alternative zum Einkauf des Ökostroms über den Markt sind sogenannte Power Purchase Agreements (PPA). Hier wird ein langjähriger Direktvertrag zwischen dem Erzeuger (beispielsweise Windparkbetreiber) und dem Nutzer (beispielsweise Datacenter) geschlossen. Die langfristige Abnahmebeziehung ermöglicht es dem Anlagenbetreiber, auch mit einer auslaufenden Förderung den Windpark wirtschaftlich zu betreiben.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: kurzfristig (0 – 2 Jahre) | Potenzial: sehr hoch |
Eine gute Möglichkeit, Ökostrom nachhaltig einzusetzen, besteht darin, ihn selbst zu produzieren und mit dieser Investition die eigenen Netto-Zero-Emissions-Ziele beim Betrieb des Unternehmens zu erreichen. Bei Datacentern und Bürogebäuden eignen sich die Dächer besonders gut, um Photovoltaik zu installieren. Der Strombedarf von Datacentern ist in diesem Zusammenhang nicht zu unterschätzen. Datacenter-Betreiber brauchen für die Deckung des eigenen Strombedarfs neben den Dach- weitere Freiflächen. Nicht alle Datacenter-Betreiber können zusätzliche Freiflächen für diesen Zweck aufbringen und nicht immer ist die behördliche Beantragung dieser Flächen einfach umzusetzen. Investments in eigene Solarkraftwerke binden darüber hinaus Geld, das dann dem Kerngeschäft des Unternehmens nicht mehr zur Verfügung steht.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: mittelfristig (2 – 3 Jahre) | Potenzial: sehr hoch |
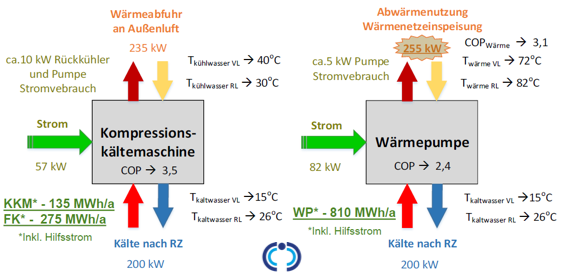
Der PUE-Wert gibt den Quotienten aus Energieeintrag und Energienutzung an. Nimmt man die Nutzung (die IT-Last im Datacenter) als theoretisch konstant an (zum Beispiel 1.000 kWh), dann wird der PUE-Wert durch die Effizienz der Versorgungssysteme bestimmt. Die größten Verbraucher hier sind die unterbrechungsfreie Stromversorgung (USV) und vor allem die Kühltechnik inklusive Pumpen. In der Vergangenheit wurden für die Kühlung der IT-Systeme leistungsstarke Kompressionskältemaschinen zentral verbaut. Das Prinzip solcher Kältemaschinen ist dem eines Kühlschranks identisch. Über Rohr- und Umluftkühlsysteme wird die in den Kältemaschinen produzierte Kälte zu den Verbrauchern auf der IT-Fläche gebracht. Dabei wird oft mit Temperaturen von 18 bis 20 Grad Celsius gearbeitet. Datacenter mit solchen Anlagen weisen im Schnitt einen PUE-Wert von 1,7 aus.
Mit zwei geringfügigen Änderungen ist es möglich, ein solches Datacenter mit einem PUE-Wert von 1,3 zu betreiben und damit 50 Prozent der benötigten Energie für die Kälteerzeugung einzusparen:

| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: mittelfristig (2 – 4 Jahre) | Potenzial: hoch |
Der heute in den Datacentern verbaute Kühlkreislauf (auch unter B1) gibt am Ende die durch die Server strömende, erwärmte Luft an die Umwelt über ein Rückkühlsystem ab. Dies liegt vor allem daran, dass man mit der Abwärme von durchschnittlich 38 bis 45 Grad Celsius nicht viel anfangen kann. Abwärmenutzung setzt eine Prozesswärme von 75 bis 85 Grad Celsius voraus. Erst ab solchen Temperaturen könnte die Abwärme sinnvoll in ein Fernwärmenetz eingespeist werden.
Der Ersatz einer Kompressionskältemaschine (Beispiel B1) durch eine Wärmepumpe (WP) würde die notwendige Prozesswärme in Kombination mit der Abwärme bereitstellen.
Leider scheitert es häufig an der Umsetzung. Zum einen ist ein Fernwärme-Netzanschluss nicht an jedem Datacenter verfügbar oder der regionale Energieversorger nicht bereit, eine Fremdeinspeisung zuzulassen. Zum anderen ist der Energieaufwand bei einem gleichen Nutzerverbrauch höher als bei der Nutzung einer Kompressionskältemaschine. Aktuell gibt es beispielsweise in Deutschland keinen speziell geförderten Wärmepumpentarif, um den sinnvollen Einsatz von WP zu unterstützen.
Heute werden IT-Systeme vornehmlich über gekühlte, vorbeiströmende Luft gekühlt. Luft an sich ist kein besonders guter Wärmeleiter. Um die Effizienz bei der Kühlung zu erhöhen, wäre eine direkte Kühlung der IT-Systeme (insbesondere der CPUs) mit einem Cooling Liquid Medium ein vielversprechender Ansatz. Die hier eingesetzten Vorlauftemperaturen liegen weit oberhalb von 50 Grad Celsius. Damit kann auch die noch notwendige Raumkühlung vollständig über „freie Kühlung“ realisiert werden. Die Abwärme in dem Kreislauf ist mit 80 bis 90 Grad Celsius schon auf dem Niveau der Prozesswärme für die Übergabe an ein Fernwärmenetz. Damit entfallen die Investition und der Betrieb einer Wärmepumpe (Beispiel B2). Bei Verwendung solcher Systeme in Verbindung mit der Abwärmenutzung sind PUE-Werte von <1,10 erreichbar. So gut, wie die Effizienz eines solchen Systems ist, ist die Umsetzung herausfordernd. Nicht in jedem Datacenter sind die Infrastrukturanlagen so konzipiert, dass Wasseranschlüsse in hinreichendem Maße in die Racks und an jeden Server geführt werden können. IT-Systeme wie Server mit Liquid-Cooling-Anschlüssen sind heute aufgrund der gering nachgefragten Stückzahlen noch gut 50 Prozent teurer in der Anschaffung als vergleichbare Standard-Server.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: mittelfristig (3 – 5 Jahre) | Potenzial: sehr hoch |
Bei Green-IT-Projekten geht es sehr schnell um Maßnahmen zur Effizienzsteigerung der Datacenter-Infrastruktur. Weniger betrachtet werden die Möglichkeiten bei der Software, die auf den IT-Systemen als Business-Applikation läuft. Die These: Je effizienter die Programmiersprache und je eleganter der Code mit der Ressource CPU-Cycle und Speicherplatznutzung umgehen, desto weniger Ressourcen (Server, Klima, Strom und so weiter) werden benötigt.
Eleganter Code beschäftigt sich damit, die CPU-Ressource und den Zugriff auf den Arbeitsspeicher zu optimieren. Ein simples Bespiel hierfür wäre die Berechnung von PI/2 mit einer anschließenden Multiplikation einer Variablen innerhalb einer Schleife. Bei jedem Schleifenaufruf muss PI/2 berechnet werden. Eleganter wäre es, PI/2 als Konstante einmal zu berechnen und den Wert in der Schleife zu verwenden. Damit wird bei jedem Schleifenaufruf nur die Multiplikation einer Konstanten mit einer Variablen ausgeführt.
Verwendung von Programmiersprachen: In Unternehmen werden heute Business-Applikationen auf Basis vieler unterschiedlicher Programmiersprachen erstellt. Gründe hierfür sind das Alter von Applikationen, der gerade verfügbare Skill von Programmierern, die Einfachheit des Erlernens der Sprache und die Art der Aufgabe, die es zu lösen gilt.
Dabei entstehen große Unterschiede in der Ressourcenausnutzung pro Business-Applikation. Industrie-Benchmarks haben gezeigt, dass im Mittel C und C++ sehr effizient mit CPU und Speicher umgehen. Perl und Python hingegen belasten für die gleichen Benchmark-Aufgaben die CPU 70-fach mehr. Auf der anderen Seite ist Python im Vergleich zu C einfacher zu erlernen und der Softwarecode leicht verständlich. JavaScript liefert in solchen Benchmarks einen guten Wert (3,6-fach). Die relativ neue Programmiersprache RUST ist mit einem Benchmark-Wert von 1,17 fast so effizient wie C, gleichsam ist der Software-Code einfach zu verstehen und zu lesen. (Eine ausführliche Übersicht dazu finden Sie hier.)
Grundsätzlich ist die dauerhafte Pflege von Programmen bei vielen verwendeten Programmiersprachen ineffizienter als bei wenigen Programmiersprachen. Standards wie Enterprise-Architektur können dabei helfen, in diesem Bereich das Optimum für eine Organisation zu finden.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: kurzfristig (0 – 2 Jahre) | Potenzial: hoch |
Datacenter verbrauchen sehr viel Energie zum Betrieb der Nutzlast (in der Regel Rechen-, Speicher- und Kommunikationsleistungen) und für die Sicherstellung der Verfügbarkeit (always on) dieser Rechenleistungen. Nicht alle Regionen auf der Welt haben gleiche Voraussetzungen zur Produktion und Speicherung von nachhaltig erzeugter Energie.
Aus Photovoltaik erzeugter Strom ist nachhaltig produziert, steht aber nicht 24×7 zur Verfügung. Auch in Regionen mit optimaler Sonneneinstrahlung produzieren die Anlagen nachts keinen Strom. Windkraftanlagen sind maßgeblich von den Wetterbedingungen der jeweiligen Region abhängig. Sie können zwar auch nachts Strom produzieren, ein 24×7-Betrieb ist aber keinesfalls realistisch. Wasserkraft- oder Wellenkraftwerke eignen sich schon eher für eine kontinuierliche, gleichmäßige Stromproduktion. Allerdings müssen für diese Stromproduktion seltene geografische Rahmenparameter vorhanden sein. Neben der Produktion sind die Wege für den Transport der grünen Energie relevant.
Nordische Länder wie Island und Norwegen besitzen sehr gute geografische Voraussetzungen für die Produktion und Zwischenspeicherung von Energie. Der Reichtum an geothermischer Energie (Island) und Wasserkraft (Norwegen), kombiniert mit Ganzjahrestemperaturen von unter 20 Grad Celsius sind optimal für den Betrieb von Datacentern. Dazu liegt zum Beispiel Island zwischen Nordamerika und Europa entlang wichtiger Internetautobahnen. Der in Norwegen erzeugte Strom kann beliebig über die zahlreich in den Regionen zur Verfügung stehenden Staudämme gespeichert und über die Talsperren regional zur Verfügung gestellt werden. Durch die Regionalität, die natürliche Ressource Wasser, sind die Produktion und Speicherung von Energie sehr kostengünstig realisierbar. Der Faktor bei den Energiepreisen in Norwegen und Island gegenüber Strompreisen in Westeuropa liegt in der Regel bei größer 10.
Die Ressource Energie ist beim Betrieb von Datacentern einer der wesentlichen Kostenfaktoren. Ein Faktor 10 wirkt entsprechend groß für Betreiber oder Unternehmen. Damit ist im Sinne der Nachhaltigkeit der Business Case – Betrieb des Datacenter in den nördlichen Regionen – unbedingt zu prüfen.
Besonders rechenintensive Plattformen sind High-Performance-Simulationscluster. Alle Automobilbauer betreiben als Beispiel große Teile ihrer Simulationscluster in Norwegen und Island. Der Grund: Nachhaltig produzierter, sehr billiger Strom.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: mittelfristig (1 – 3 Jahre) | Potenzial: sehr hoch |
Jede Migration von Applikationen aus dem eigenen Datacenter ist aus der isolierten Sicht „Green-IT“ positiv und effizient.
Hyperscaler wie Google Cloud, AWS und Microsoft Azure bauen und betreiben große Rechenzentren in allen Regionen der Erde. Sie bieten dort IaaS, PaaS und SaaS Services für alle erdenklichen IT-Bedarfe an. In der Regel werden diese Datacenter entweder bei großen Colocation-Providern, wie beispielsweise Equinix, angemietet oder von den Hyperscalern in modernster Bauweise errichtet. Das angestrebte Ziel der Hyperscaler ist der dauerhafte Betrieb der Lokationen mit einem PUE <1,20. Jeder der Hyperscaler versucht, bei Neubauprojekten den aktuell neuesten Stand der Technik zu antizipieren, und so gibt es heute schon Datacenter, welche einen PUE-Wert von 1,09 ausweisen.
Im Durchschnitt erreichen heutige Corporate Datacenter einen PUE-Wert von 1,63 (bezogen auf den durchschnittlichen PUE-Wert aller Corporate Datacenter in Deutschland; einzelne Datacenter neuerer Bauart weisen deutlich bessere PUE-Werte aus; nur ein einstelliger Prozentsatz der Datacenter schafft dabei einen PUE-Wert <1,3). Die PUE-Werte der Colocation Provider und Hyperscaler weisen mindestens einen PUE-Wert <1,2 aus. Aus Sicht der Green-IT Prinzipien werden damit die Datacenter der Hyperscaler um 25 Prozent effizienter betrieben.
Migrationen und die Nutzung von Cloud Services zahlen positiv auf die Green-IT und damit auf die Nachhaltigkeitsanstrengungen der Unternehmen ein.
| Vorteile | Nachteile |
|---|---|
|
|
| Umsetzung: mittelfristig (1 – 3 Jahre) | Potenzial: hoch |
In der kommenden Ausgabe des Datacenter-Newsletters stellen wir Ihnen vor, wie sich die unterschiedlichen Maßnahmen in das Roadmap-Modell einordnen lassen, das wir in Teil 1 dieser Serie beschrieben haben.
Haben Sie Fragen zu Green IT oder Sustainable IT? Benötigen Sie Unterstützung bei der Erstellung Ihrer individuellen Umsetzungs-Roadmap zur Reduzierung von Emissionen? Wir zeigen Ihnen gern geeignete Messverfahren, mit denen Sie die einzelnen Maßnahmen bezüglich ihres Nachhaltigkeitspotenzials einordnen können. Melden Sie sich dazu am besten gleich bei Ihrer/Ihrem Ansprechpartner:in von Computacenter.

Michael Löbmann, Ulf Schade
Weniger ist mehr, so lautet die Devise vieler Unternehmen, die derzeit ihre eigenen Rechenzentren nicht mehr selbst betreiben wollen und ihre Kapazitäten entweder zu den Hyperscalern oder zu Colocation Providern verlagern. Der Grundgedanke: Runter mit den Kosten, rauf mit Effizienz und Nachhaltigkeit. Damit sich die gewünschte Wirkung jedoch einstellt, ist eine professionelle und vor allem langfristige Planung gefragt. Denn vermeintlich triviale Projektschritte entpuppen sich häufig als zeit- und kostenintensiv.
Vom Thema RZ-Konsolidierung muss wohl kaum ein IT-Verantwortlicher noch überzeugt werden. Die Vorteile liegen auf der Hand, denn konsolidierte Rechenzentren sind dynamischer, effizienter und kostengünstiger. Auf welche Weise man eine Konsolidierung innerhalb eines Rechenzentrums angeht, ist bereits altbekannt. Harmonisierung, Virtualisierung und Automatisierung bilden das klassische Methodenset und ebnen zudem den Weg zur Private Cloud. Doch eine Konsolidierung betrifft längst nicht mehr nur die Betrachtung eines einzelnen Rechenzentrums. In vielen Fällen müssen mehrere Rechenzentren zusammengeführt werden. Diese gilt es dann nicht nur technologisch, sondern auch physisch zu konsolidieren.
Der Hintergrund: Die meist in den 2000er-Jahren entstandenen Rechenzentren vieler Unternehmen sind geographisch verteilt und genügen in vielen Fällen nicht mehr den Anforderungen an einen modernen Betrieb. Dies betrifft neben dem Alter der Rechenzentren (15 bis 20 Jahre) die regulatorischen Anforderungen zum Abstand der einzelnen Rechenzentren zueinander und die wachsenden Anforderungen an die IT aus der Bedeutung, die durch die Digitalisierung von Geschäftsprozessen entstanden ist. Hinzu kommt: Viele der „historisch“ gewachsenen Rechenzentren rentieren sich nicht – denn mit ihnen verbunden sind zahlreiche Fixkosten, die auch durch Verschlankungen bei der Hard- und Software nicht reduziert werden können.
Die Rede ist beispielsweise von ungenutzter Fläche oder großen Klima- und USV-Anlagen, die bei einer Konsolidierung des jeweiligen Rechenzentrums nicht gleichermaßen mitschrumpfen. Ein weiterer Faktor ist der akute Mangel an Fachkräften, der den Betrieb zunehmend erschwert. Aktuell trägt das Thema Nachhaltigkeit zusätzlich zur Notwendigkeit bei, Rechenzentren energieeffizient zu betreiben. Bei älteren Rechenzentren steht der dazu notwendige Ertüchtigungsaufwand oft in keinem wirtschaftlichen Verhältnis.
Die Konsolidierung ihrer Rechenzentrumslandschaft und ein damit verbundener Hardware-Umzug stehen daher derzeit für viele Unternehmen auf der Agenda. Vor dem Hintergrund des in Aussicht stehenden Einsparpotenzials darf eines jedoch nicht vergessen werden: Eine erfolgreiche Migration ist mit einem hohen Planungsaufwand verbunden, dessen Ausmaß häufig unterschätzt wird. Diese Planung ist naturgemäß in hohem Maße individuell. Dennoch gibt es einige Bausteine, die als Basis für eine allgemeine Vorgehensweise herangezogen werden können:
Sollen ein beziehungsweise mehrere Rechenzentren migriert werden, gilt es zunächst, die richtige Örtlichkeit zu finden und eine nachhaltige Planung aufzusetzen. Unabhängig davon, ob ein neues Rechenzentrum gebaut wird oder vorhandene Räumlichkeiten ertüchtigt werden sollen, wirken sich Fehler meist langfristig aus. Was einmal falsch geplant war, ist mit hoher Wahrscheinlichkeit nicht oder nur mit hohem Aufwand änderbar. Zu beachten sind beispielsweise grundlegende Anforderungen an Energie, Brandschutz, Flächenkonzeption und passive Verkabelung. Grundsätzlich gilt es, bei der Planung dieser Komponenten immer vom Versorgungsmaximum auszugehen und den Blick acht bis zehn Jahre in die Zukunft richten.
Eine Alternative zum eigenen Rechenzentrum ist die Nutzung von Colocation-Flächen. Die Vorteile liegen auf der Hand. Colocation-Betreiber stellen moderne RZ-Flächen als Teil ihres Kerngeschäfts zur Verfügung. Die Auslastung und der Betrieb der Flächen erfolgen in der Regel effizienter als der Betrieb von eigenen Lokationen. Hyperscaler nutzen ebenfalls in Teilen Colocation-Angebote. Eine geringe Latenz zu vom Kunden genutzten Cloud Services wirkt sich positiv auf den Gesamt-IT-Servicebetrieb aus.
Häufig unterschätzt werden bei einer RZ-Konsolidierung die Inventarisierung der Hardware sowie Applikationsabhängigkeiten. Das Wissen über die Geräte ist meist auf mehrere unstrukturierte Informationsquellen oder Datenbanken verteilt und nicht selten veraltet. Zudem kommt es vor, dass Zuordnungen nicht eindeutig sind. Einen validen Status zu erhalten, ist daher häufig mit hohem Aufwand verbunden.
Erfahrungen zeigen, dass die Anzahl der inventarisierten Geräte je nach Quelle in erheblichem Ausmaß variieren kann. Abhilfe schafft hier die Erstellung einer zentralen, softwaregestützten Konsolidierungsdatenbank, in die standardmäßig sämtliche Hardware eingepflegt wird. Mit der einmaligen Eingabe und Konsolidierung der Daten ist es allerdings noch nicht getan. Vielmehr muss die Aktualität der Datenbank durch kontinuierliche Pflege während des gesamten Migrationsprozesses – und möglichst darüber hinaus – sichergestellt werden. IT-Asset-Management und Data Center Infrastructure Management (DCIM) sind operationale Werkzeuge, die, so sie bislang im IT-Betrieb noch nicht existieren, spätestens bei einer RZ-Konsolidierung dauerhaft eingeführt werden sollten.
Aufwändiger noch als die Bestandsaufnahme der Hardware gestaltet sich in den meisten Fällen die Analyse der Applikationen, deren Ergebnis ebenfalls in die Konsolidierungsdatenbank eingepflegt werden muss. Die Frage lautet: Wo läuft was und wie gestalten sich die Verbindungen? Dabei gilt es, Abhängigkeiten und Schnittstellen zu erkennen und zu erfassen. In den seltensten Fällen ist diese Brücke zwischen Hardware, Virtualisierung und Anwendungen ausreichend dokumentiert. Es gibt lizenzpflichtige Softwarelösungen, die es ermöglichen, Applikationen, Hardware und Maintenance auf Knopfdruck abzurufen (Application Device Dependency Mapping, kurz: ADDM).
Diese sind jedoch mit einem gewissen technischen und personellen Aufwand verbunden – aus diesem Grund vernachlässigen Unternehmen deren Einsatz gern. Gleiches gilt für die Entwicklung und den Betrieb eigener Anwendungen, mit denen ein zentrales Management von Themen wie Umzug, Wartung, Notfallplanung oder Betriebsanleitungen erfolgen kann. Erfahrungen zeigen allerdings, dass sich die dadurch gewonnene Flexibilität auszahlt. Denn nur, wenn diese Zusammenhänge transparent sind, können Geräte oder virtuelle Assets risikofrei bewegt werden.
Rund ein Drittel der Aufgaben, die bei einer Konsolidierung mit gekoppeltem Umzug anfallen, betrifft die Kommunikation. Vor einer Migration gilt es zu erfassen, welche Fachabteilungen Endkunden welcher Applikationen sind, und die jeweiligen Ansprechpartner:innen sowie deren Vertreter:innen ins Boot zu holen. Mit ihnen muss neben dem Freigabeprozess zur Migration auch die Aufrechterhaltung der jeweils vereinbarten Servicelevel abgestimmt werden. Festgehalten werden diese Informationen ebenfalls in der zentralen Konsolidierungsdatenbank.
Während des Konsolidierungsprojekts oder -programms ist es hilfreich, ein Projektmarketing und eine Projektfortschrittskommunikations-Strategie umzusetzen. Umzüge und Migrationen sind mit Risiken und Veränderungen verbunden. IT-Anwender:innen scheuen Veränderungen (deren Auffassung: never change a running system). Eine positive Informationskultur schafft Vertrauen, Akzeptanz und eine gewisse Kultur der Fehlertoleranz.
Ein Konsolidierungsprozess läuft in den meisten Fällen nicht strikt nach Plan. Während der Umsetzung ergeben sich immer wieder Abweichungen und veränderte Rahmenbedingungen. Umso wichtiger ist ein kontinuierliches Changemanagement. Jede Änderung, sei es im Applikations-, Hard- oder Softwarebereich, muss dokumentiert werden und tagesaktuell verfügbar sein. Entsprechend handelt es sich nicht um einen einmaligen Projektschritt, sondern um einen komplexen Prozess, der eine Konsolidierung fortwährend begleitet. Erfolgskritisch dabei ist, dass seine Bedeutung von allen Beteiligten verstanden wird und eine konsequente Umsetzung erfolgt.
Sind die vorbereitenden Maßnahmen auf den Weg gebracht, muss die Besiedelung der RZ-Räumlichkeiten mit IT-Komponenten konzipiert und umgesetzt werden. Die Frage lautet: Wo werden welche Komponenten am sinnvollsten aufgebaut? Um dies zu entscheiden, müssen unter anderem Faktoren wie Klimatisierung, Stromversorgung, Verfügbarkeit und die Platzierung von Sondergeräten wie Bandrobotern oder Mainframes in die Betrachtung mit einbezogen werden. Zusätzlich gilt es festzulegen, welche Alttechnologien mitgenommen werden müssen und wo neue Technologien zum Einsatz kommen.
Modernisierungen betreffen dabei vor allem den LAN- und SAN-Bereich. Stichworte sind hier unter anderem die Konvergenz von LAN und SAN, 100/400 GbE und 32 Gb/s FC und deren Längenbeschränkungen, ein flexibles und ausfallsicheres Rackdesign, innovative Rack- und Bladeservertechnologien sowie Clusterfunktionalitäten über RZ-Module hinweg. Bei aller Begeisterung für einen Rundumschlag in Sachen Modernisierung sollte das grundsätzliche Ziel darin bestehen, einen weichen Übergang zu schaffen. Denn die Erfahrung zeigt, dass der Wunsch nach neuen Technologien nicht immer mit den Anforderungen an Betrieb und Verfügbarkeit vereinbar ist. Prinzipiell gilt das „Frozen Zone“-Prinzip: Je näher der Umzug, desto weniger Technologie-Changes.
Umstellungen, seien es das Einspielen von Updates oder Upgrades bei Softwarekomponenten, die Durchführung von Konfigurationsänderungen oder Modifikationen von Netz- oder Serverressourcen, sollten entweder mit genügend Vorlauf vor dem Umzug erfolgen oder in Ruhe danach. Ausgenommen von den „Frozen Zones“ sind natürlich Störungsbehebungen und dringende Wartungsarbeiten.
Werden mehrere Rechenzentren verschiedener Standorte zusammengelegt, gilt es, bestehende Kopplungsleitungen zu überprüfen, gegebenenfalls neue Leitungen zu beantragen, diese zeitlich zu terminieren und ihre Qualität sicherzustellen. In der Planung zu beachten sind dabei zentrale Parameter wie Hochverfügbarkeit, Wegeredundanz, Sicherheit oder Laufzeitverhalten. Nicht selten ist übrigens die Qualitätssicherung die größte Herausforderung. Netzwerkverantwortliche müssen jederzeit die aktuelle Leistungsfähigkeit der Kopplungsleitungen beurteilen können, um ihre Netzwerke für eine optimale Leistung zu konfigurieren oder um die Qualität der zugekauften Services zu überprüfen.
Risikomanagement ist neben dem Changemanagement einer der permanent laufenden Prozesse im Zuge einer RZ-Konsolidierung. Dabei geht es in erster Linie darum, sowohl interne als auch externe Risiken in ihrer Auswirkung transparent zu machen, zu analysieren und im Prozess durch geeignete Maßnahmen weitgehend zu minimieren. Dazu gehören beispielsweise Verzögerungen im Zeitplan, Einschränkungen in der Ressourcenverfügbarkeit und Einschnitte im Budget genauso wie technologische Risiken wie etwa Ausfallraten bei Altgeräten.
Wenn Inventarisierung, Analyse und Konzept stehen, heißt es, konkrete Migrationsgruppen zusammenzufassen und den phasenweisen Umzug zu planen. Mithilfe des laufenden Changemanagements ist eine Gruppierung der einzelnen Komponenten – gewissermaßen auf Knopfdruck – umsetzbar. Auf dieser Basis wird eine Zeit- und Ablaufplanung für den Umzug erstellt, in der Ausfallzeiten und Wiederinbetriebnahmen klar festgelegt sind.
Durch eine laufende Qualitätssicherung und Kontrolle muss während des gesamten Prozesses sichergestellt werden, dass der Übergang gefahrlos abläuft und die jeweiligen Services zum vereinbarten Zeitpunkt wieder zur Verfügung stehen. Dazu gehört neben dem klassischen Vier-Augen-Prinzip in der Konzeption auch die ständige Überprüfung der einzelnen Prozessschritte durch eine:n verantwortliche:n Projektleiter:in.
Vor den eigentlichen Wellenumzügen oder Massenmigrationen sind die Umzugs- oder Migrationsverfahren in einem kleinen Maßstab zu testen. Ergeben sich GAPs oder Auffälligkeiten im Prozess, sind diese risikominimierend noch anpassbar.
Werden die oben genannten Basisschritte berücksichtigt, steht einer erfolgreichen Konsolidierung geographisch verteilter Rechenzentren nichts im Wege. Das gilt übrigens auch, wenn der Prozess durch einen externen Anbieter übernommen wird und Services aus der Public Cloud das eigene RZ-Leistungsspektrum ergänzen oder in Gänze abbilden.
Dieser Faktor spielt übrigens auch bei der Betrachtung der künftigen Entwicklung eine wichtige Rolle, denn die Dynamik von RZ-Konsolidierungen wird in Zukunft auch maßgeblich dadurch bestimmt, wie vertrauenswürdig und sicher Public Cloud Services angeboten werden. Beachtenswert ist, dass auch Migrationen in Richtung Public Cloud oft mit einem Lift&Shift, also mit einem virtuellen Umzug, beginnen. Viele der hier beschriebenen Prozessschritte sind dabei gleich.
Computacenter unterstützt Unternehmen bereits seit über 20 Jahren professionell bei Rechenzentrumsverlagerungen. Die aufgebauten Kompetenzen und Services umfassen sowohl die Beratung beim Bau oder bei der Ertüchtigung von Rechenzentren, die Relocation (Umzug) von Applikationen, Systemen oder gesamten Rechenzentren, als auch den Aufbau eines geeigneten Notfallmanagements für den IT-Betrieb. Sprechen Sie uns gern an!

Claus Müller
Nachdem AMD und Intel ihre neuen Prozessoren auf den Markt gebracht haben, sind nun auch neue Servermodelle verfügbar. Die ProLiant Server der 11. Generation von Hewlett Packard Enterprise (HPE) bestechen dabei mit herausragender Performance und ausgeklügelter Sicherheit. Wir stellen die aktuellen Modelle vor und zeigen Ihnen, was bei deren Einsatz zu beachten ist.
Mit den neuen Prozessoren werden herstellerübergreifend die aktuellen Speicher- und Bustechnologien unterstützt: DDR5 RAM und PCIe5. GenZ-Ansätze gehen in Compute Express Link (CXL) auf und versprechen uns in der Zukunft weitere Performance-Schübe und einen effizienteren Betrieb der Systeme. Bereits heute sehen wir neue Performance-Rekorde, Leistungszuwächse, mehr Cores, eine erhöhte Leistungsaufnahme und dadurch bedingt anspruchsvolle Maßnahmen, die Systeme zu kühlen. Das gilt insbesondere für die hoch performanten Prozessoren.
HPE ProLiant Server unter der Lupe
Was aber unterscheidet einen x86-Server von HPE, einen HPE ProLiant Server, von den Servern der anderen Hersteller? Was liefern die Systeme, um die Compliance-, Governance- und ganz neu die Sustainability-Anforderungen zu erfüllen?
HPE ProLiant Server der Generation 11 (HPE ProLiant Gen11) setzen den Goldstandard bei den Rechenzentrumsservern und fokussieren auf bestmögliches Management mit niedriger Total Cost of Ownership und auf höchstmögliche Sicherheit.
HPE bietet aktuell die folgenden Modelle an:
Die Sicherheit – HPE fasst unter dem Oberbegriff Zero-Trust eine globale Initiative zusammen – beginnt bei den Lieferketten und endet mit dem sicheren Entfernen aller Daten, wenn der Server das Ende seines Lifecycle (sein Lebensende im Datacenter des Kunden) erreicht hat. Die Integrität des Server-BIOS wird durch Technologien wie Silicon Root of Trust kontinuierlich sichergestellt, sodass bei HPE ProLiant Servern Veränderungen im laufenden Betrieb festgestellt und gemeldet werden. Sicherheitsrelevante Vorkommnisse im Bereich des BIOS fallen damit nicht erst beim Rebooten in einem Wartungsfenster auf, sondern schon während der Laufzeit, und entsprechende Maßnahmen (zu Beispiel UEFI BIOS Rollback) können frühzeitig und gezielt geplant werden.
Erweitert wird Silicon Root of Trust unter anderem um die DevID, die Serveridentität. Die DevID bietet eine Möglichkeit, einen Server über Netzwerke hinweg eindeutig zu identifizieren. Sie basiert auf dem IEEE-802.1AR-DevID-Standard. Die DevID ist eindeutig an einen Server gebunden und ermöglicht es diesem, seine Identität in verschiedenen Industriestandards und Protokollen nachzuweisen, die kommunizierende Geräte authentifizieren, bereitstellen und autorisieren.
Neben dem Prozessor ist das Remote-Management das Kernelement eines HPE ProLiant Servers der Generation 11. Das integrated Lights Out Board (iLO) kommt mit erweiterten Funktionen und kann werkseitig mit einer Serveridentität ausgestattet werden. Die werkseitig bereitgestellte Serveridentität wird iLO IDevID genannt. HPE Server können sicher in ein Kundennetzwerk eingebunden werden, indem die iLO IDevID für die 802.1X-Authentifizierung verwendet wird. Die iLO IDevID hat lebenslang Gültigkeit und ist unveränderlich.
Der Zero-Trust-Ansatz bildet auch die Grundlage für das revolutionäre Systemmanagement mit dem HPE Compute Ops Manager (COM). Multi-Faktor-Authentifizierung, Sicherheitszertifikate und die weltweit sichersten Industriestandard-Server gewährleisten problemlos die Compliance. HPE hebt das Management auf eine neue Stufe – es ist einfacher, agiler, leistungsfähiger.
HPE GreenLake für Compute Ops Management ist eine sichere und skalierbare Cloud-basierte Anwendung, die einen einheitlichen Betrieb auf As-a-Service-Basis vom Edge bis zur Cloud bereitstellt. Sie vereinfacht die Verwaltung der Infrastruktur über den gesamten Lebenszyklus hinweg – vom vereinfachten Zustandsstatus bis hin zum automatisierten Firmware-Management für die gesamte Serverflotte auf Basis HPE ProLiant.
Mit den neuen Prozessoren kommen auf die Betreiber von Rechenzentren höhere Anforderungen mit Blick auf Stromversorgung und Abwärme zu. Die Stromversorgung kann zu einem Problem werden, wenn pro CPU bis zu 360 W zur Verfügung gestellt werden müssen. Die Serverhersteller bieten die passenden Netzteile mit Leistungen über 2000 W an. Fraglich ist, wie die Leistung zum Rack kommt und wie die Verlustwärme abgeleitet wird.
Nach wie vor wird auf aktive und passive Kühlung gesetzt, aber auch Wasserkühlung (Direct Liquid Cooling) wird künftig kein exotisches Nischenthema mehr sein, sondern ein Standard im Rechenzentrum, wenn anspruchsvolle und leistungshungrige Arbeitslasten (Workloads) bedient werden müssen. Hier müssen eventuell Anpassungen im Rechenzentrum erfolgen, um den sicheren und effizienten Betrieb zu gewährleisten.
Gern informieren wir Sie über die neuen HPE ProLiant Gen11 Serversysteme, die Optionen der Server und die Roadmap. Wir stellen Ihnen vor, welche Modelle zu welchen Workloads am besten passen und finden gemeinsam mit Ihnen das optimale System, das Ihre Anforderungen am besten erfüllt. Sprechen Sie uns dazu einfach an!

Norbert Steiner
Ein erfolgreiches, digital transformiertes Unternehmen besteht aus interdisziplinären Teams. Diese verantworten jeweils ein Produkt, das wiederum andere Teams verwenden. Was bedeutet in einem solchen Umfeld der Begriff Verantwortung – und wie können Teams das verinnerlichen?
Für moderne Applikationen und Workloads sind die sogenannten Applikationsteams zuständig, auch Produktteams und weniger häufig DevOps-Teams genannt. Diese nutzen Services von Plattformteams, um schneller Wertschöpfung für das Unternehmen zu erreichen. Damit alles reibungslos klappt, arbeitet jedes interdisziplinär aufgestellten Teams eigenverantwortlich.
Die Idee beginnt bereits mit agilen Projektmethoden wie Scrum. Dabei ist festgelegt, dass die aus dem Entwicklungsprozess in Scrum entstehenden sogenannten Inkrements nach Freigabe durch den Produkt-Owner (PO) sofort in Produktion gehen dürfen. Es besteht eine Produkt- und Ende-zu-Ende-Verantwortung, das heißt, dass das Team die Verantwortung für alle Inkremente über die Testautomation bis in die Produktion innehat.
Das ist ganz im Sinne von Methoden rund um DevOps – wer es entwickelt, der betreibt und überwacht das eigene Produkte und dessen Inkremente. Und das verantwortliche Team behebt Störungen, bedient Change-Prozesse und erfüllt die Anforderungen der IT-Sicherheit.
All das ist schnell geschrieben, aber wenn diese Punkte im Team angesprochen werden, dann finden sich häufig viele Schubladen in den Köpfen und es wird schnell klar: Hier müssen die oft festgefahrenen Strukturen in den Köpfen aufgelöst werden.
Eine Antwort auf diese Frage ist schwer zu finden, denn es handelt sich weder um eine technische Frage noch um ein IT-Problem. Stattdessen geht es um Psychologie – und IT-Fachkräfte stehen nicht in der Reputation, dahingehend tiefgreifende Fachkenntnisse zu besitzen. Aber in der Arbeit in und mit dem Team ergeben sich Indikatoren, dass ein Umkrempeln notwendig ist. Im Folgenden finden Sie drei Beispiele typischer Fehlerursachen, die wir während unserer langjährigen Erfahrung mit agilen Methoden in Kundenprojekten schon häufig beobachten konnten.
Unsere Empfehlung lautet, dass in den Teams eine Aufgabe etabliert wird, einerseits moderne Betriebsprozesse und Verfahren zu formulieren und abzustimmen, andererseits aber auch das Team zu unterstützen, die Verantwortung für das Inkrement, das durch den PO für die Produktion freigegeben werden kann, zu übernehmen. Das Team muss sicherstellen, dass dieses Inkrement stabil und wiederherstellbar funktioniert. Die Aufgabe Betrieb im Team unterstützt und fordert das Team durch Maßnahmen wie Incident Game Days heraus, diese Fähigkeit zu trainieren.
Diese Aufgabe – und ja, das verantwortliche Ausführen der Aufgabe – ist wichtig und es handelt sich um eine dauerhafte Aufgabe. Auch die Teams und deren Vorgehen verändern sich mit der Zeit und unter anderem die drei oben genannten Punkte kommen immer wieder auf – nicht nur durch Fluktuation, sondern auch durch Überlastung im Team oder schlicht durch menschliche Vergesslichkeit.
Verantwortliche und selbstorganisierte interdisziplinäre Teams sind äußerst wichtig – und eine Aufgabe oder Rolle im Team, die diese Verantwortlichkeit immer wieder bewusst macht und in geeigneter Weise trainiert, ist aus unserer Erfahrung wertvoll und wertschöpfend. Wenn Sie mehr darüber erfahren möchten, sprechen Sie uns an – wir beraten Sie gern.