Application Performance Monitoring und Application Ressource Management

Sehr geehrte Damen und Herren,
mit den passenden Werkzeugen lassen sich die steigenden Aufwände der IT-Verantwortlichen für immer komplexere Applikationen und IT-Landschaften eindämmen. In der aktuellen Ausgabe unseres Datacenter-Newsletters stellen wir Ihnen vor, wie Sie Tools zum Application Performance Monitoring und Application Ressource Management so einsetzen, dass Sie bestmögliche Resultate erzielen.
Lesen Sie außerdem, wie Sie mit „Infrastructure as Code“ IT-Infrastrukturen deutlich einfacher bereitstellen, betreiben und skalieren können.
Welche Cloud-Strategie verfolgt Ihr Unternehmen? Unter anderem davon hängt ab, welche Werkzeuge Sie bei Ihrem Multi Cloud Management optimal unterstützen können. Wir zeigen Ihnen exemplarisch einige Werkzeuge für die unterschiedlichen Aufgaben und erläutern, wie unsere Consultants Ihnen dabei helfen können, Ihr Cloud Management möglichst effektiv und kostengünstig zu betreiben.
Wie lässt sich das Backup für exponentiell wachsende File Server bewerkstelligen? Welche Strategie schützt die Unternehmensdaten? Antworten auf diese und weitere Fragen liefert unsere aktuelle Backup-Kolumne.
Und unsere Agile-IT-Kolumne beschäftigt sich dieses Mal mit Pipelines für Continuous Integration und Delivery (CI/CD-Pipelines) und Cloud-native Application Platforms, die die Basis zur Entwicklung moderner Applikationen darstellen. Eine Live-Demonstration verschiedener Lösungen können Sie sich übrigens in unserem Solution Center ansehen.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Der Umsatz von Computacenter in Deutschland stieg 2019 bei konstanten Wechselkursen um 5,2 Prozent gegenüber dem Vorjahr.
Weitere InfosDie Information Services Group (ISG) hat Computacenter in ihrer Studie als Leader für Public Cloud Transformation Services ausgezeichnet.
Weitere Infos
Nicht nur die Applikationen selbst werden immer komplexer, sondern auch die IT-Landschaften in den Unternehmen. Damit steigt der Aufwand für die IT-Verantwortlichen erheblich. Doch Tools zum Application Performance Monitoring und Application Ressource Management können dabei helfen, den Aufwand einzudämmen. Computacenter erläutert, wie das genau funktioniert und wie Sie mit diesen Tools am besten starten, um optimale Resultate zu erzielen.
Heutige Applikationen bestehen aus einer Vielzahl einzelner Services und werden zukünftig noch komplexer werden. Die Ressourcen stammen dabei in der Regel nicht nur aus dem eigenen Rechenzentrum, sondern zusätzlich aus mehreren unterschiedlichen Cloud Services. All das trägt dazu bei, dass der manuelle Aufwand seitens der IT-Verantwortlichen steigt, um die Performance sowie die Verfügbarkeit der Applikation und Ressourcen sicherzustellen. Wäre es da nicht einfacher, Entscheidungen zur optimalen Infrastrukturnutzung zu automatisieren? Oder eine Anwendersicht auf die eigene Applikation zu haben und somit genau zu verstehen, wie der Kunde den Service erlebt? Tools zum Application Performance Monitoring (APM) und zum Application Ressource Management (ARM) können dabei helfen, das Erlebnis der Anwender (Customer Experience) mit den Services zu verbessern, Fehlersuchen zu beschleunigen, Probleme proaktiv zu verhindern und die Nutzung und Kosten von Services zu optimieren.
Auch die Technik kann mal versagen. Dies führt in einer komplexen und verteilten Umgebung häufig zu langen Analysen von Vorfällen und damit auch zu verlorener Zeit bei der Behebung des Problems. Zudem ist es häufig nicht möglich, immer wiederkehrende oder anhaltende Leistungsprobleme zu identifizieren beziehungsweise zu lösen. Die zugrunde liegende Ursache – der sogenannten Root Cause – wird selten gefunden und behoben, stattdessen behandelt man oft nur die Symptome. Im optimalen Fall erkennt man eigene Performance-Probleme bei der Erbringung von Services, bevor der Kunde sie feststellt. Leider ist es häufig jedoch der Kunde beziehungsweise der Anwender selbst, der einen darüber informiert.
Wer kennt nicht das Motto „Never change a running system“? In der heutigen schnelllebigen Zeit, in der die IT ständigen Veränderungen unterliegt, ist dies jedoch immer seltener ein guter Ratschlag, da er nicht dem Innovationsdruck Rechnung trägt. Durch die Inbetriebnahme weiterer Services, zusätzlicher Infrastruktur oder auch durch die Erweiterung oder Verbesserung vorhandener Services kommt es regelmäßig zu notwendigen Veränderungen. Man sollte meinen, dass dies aufgrund standardisierter Prozesse geregelt abläuft, aber ohne vollständige und detaillierte Sicht auf die komplette Applikations- und IT-Landschaft ist das in der Regel nicht möglich.
Der geschäftliche Erfolg steht heutzutage im engen Zusammenhang mit der Leistungsfähigkeit der eigenen Applikationen. Oftmals ist ein einzelner Service gleichzeitig das Alleinstellungsmerkmal des Unternehmens oder des Produkts. Umso wichtiger ist es, sicherzustellen, dass dieser Service, die dahinterliegenden Applikationen und die Infrastruktur zu 100 Prozent zur Verfügung stehen.
Damit dies machbar ist, sollte nicht mehr nur eine Abteilung oder Person für die Applikation verantwortlich sein. Vielmehr sollten sich Entwickler, Ressourcen-Verantwortliche und kaufmännisch Verantwortliche gemeinsam darum kümmern, dem Kunden einen stabilen und qualitativ hochwertigen Service zur Verfügung zu stellen. Alle genannten Beteiligten benötigen hierzu handlungsorientierte und kontextbezogene Informationen, wofür wiederum ein durchgängiges Monitoring und Management der Applikationsleistung zwingend erforderlich ist.
Um diese Frage beantworten zu können, ist es wichtig, zu wissen, was genau ein Application Performance Monitoring und Application Ressource Management Tool ausmacht.
Vermutlich überwachen Sie Ihre Infrastruktur bereits mit den klassischen Monitoring Tools und reagieren entsprechend auf Meldungen. APM und auch ARM werden diese Art des Monitorings nicht ersetzen, jedoch sinnvoll ergänzen.
Der Fokus eines Application Performance Monitoring Tools findet sich schon im Namen selbst wieder. Es befasst sich mit der Performance-Überprüfung von Anwendungen. Ziel ist es, dem Anwendungsnutzer eine optimale Erfahrung bei der Nutzung der Anwendung zu bieten. Dazu ist es erforderlich, verschiedene Arten von Daten zu analysieren und den Administratoren zur Verfügung zu stellen, um bei Bedarf auf Basis der bereitgestellten Informationen korrigierende Maßnahmen zu ergreifen. Dies ist auch eine der wichtigsten Aufgabe eines APM Tools. Es kombiniert die Daten aus unterschiedlichen Monitoring-„Silos“ in einer Engine und stellt diese bestenfalls in einem Dashboard dar. Es vereinfacht das Lesen von Daten-Logs und ermöglicht eine einheitliche und frei definierbare Sicht auf den Service. Eine manuelle und fehleranfällige Analyse von Log-Dateien ist dadurch nicht mehr notwendig.
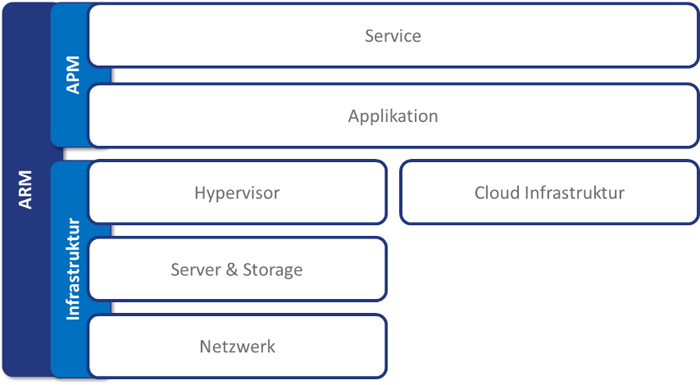
Am Markt sind APM und ARM Tools noch immer in zwei verschiedene Produktgruppen unterteilt. Aktuell gibt es kein Werkzeug, welches sowohl den Bereich APM als auch den Bereich ARM abbildet. Betrachtet man das Thema Application Performance Monitoring, fallen sehr schnell zwei dominierende Anbieter am Markt ins Auge. Beide sind in den letzten Jahren von Gartner immer wieder im Leaders-Quadranten eingeordnet worden. Dabei handelt es sich um das Produkt AppDynamics von Cisco und Dynatrace von der Firma Dynatrace.
Beide Produkte liefern sich bezogen auf die Funktionalität ein Kopf-an-Kopf-Rennen. AppDynamics bietet mit seiner einfachen Steuerung und verschiedenen Flow Maps den einfacheren Einstieg in die Applikationsanalyse.
Angesichts der zentralen Bedeutung von Cloud-Diensten für moderne Infrastrukturen ist es wichtig, visuell schnell erfassbare Informationen zur Verfügbarkeit und Performance der dort liegenden Applikationen zu erhalten. AppDynamics hat nicht nur das Potenzial, Applikationen in der eigenen Infrastruktur zu überwachen, sondern mit der gleichen Transparenz die in den genutzten Cloud-Services. Es ist in einer hybriden Infrastruktur möglich, in Echtzeit Einblick in die Anwendungsleistung und die Geschäftstransaktionen zu erhalten.
Durch die Anzeige von Geschäftstransaktionen kann beispielsweise nachverfolgt werden, wie Ihre Anwendung auf Kunden reagiert, wenn diese eine Suche durchführen, Produkte in einen Einkaufswagen legen oder auschecken. Eine der nützlichsten Funktionen im Hinblick auf die Transparenz der Ressourcennutzung ist das Auto-Discovery. Diese automatische Erkennung kann Geschäftstransaktionen finden und eine Topologiekarte des Datenverkehrs für den jeweiligen Dienst erstellen. Dadurch erhalten Sie einen detaillierten Einblick, wie Ihr Service funktioniert.
Im Bereich Application Ressource Management sehen die Analysten-Quadranten beziehungsweise -Waves ein wenig anders aus. Für das eigentliche Thema ARM gibt es keinen dedizierten Bericht der branchenüblichen Analysten wie Gartner oder Forrester. ARM ist eine Kombination aus Ressource Management, Kostenoptimierung und auch ein wenig Cloud Management. Daher findet man neben Produkten wie dem Cisco Workload Optimization Manager (CWOM) auch Cloud-Management-Plattformen wie Rightscale als direkte Konkurrenten. Wenn man das reine Ressource Management betrachtet, wäre auch VMware vRealize ein möglicher Kandidat.
Nimmt man CWOM genauer unter die Lupe – wir reden hier vom OEM-Produkt des Herstellers Turbonomic –, so deckt dieses Tool genau die drei genannten Bereiche ab. CWOM verwaltet den gesamten Anwendungsstack und stellt automatisch spezifische Aktionen zur Verfügung oder führt diese selbständig aus. Diese stellen sicher, dass Ihre Anwendungen immer die erforderlichen Ressourcen erhalten, die sie benötigen. Darüber hinaus werden mit CWOM die Optimierung der Kosten und Einhaltung der definierten Richtlinien umgesetzt.
Es gibt verschiedene Möglichkeiten, die zum Erfolg führen. Im optimalen Fall starten Sie aber nicht direkt mit der technischen Umsetzung, sondern analysieren im ersten Schritt, welche Services überwacht werden sollen. Es empfiehlt sich, nicht direkt alle Services gleichzeitig in das Monitoring aufzunehmen, sondern iterativ vorzugehen.
Im nächsten Schritt sollten Sie die für Sie infrage kommenden Tools auf Herz und Nieren prüfen. Dies verifizieren Sie am besten im Rahmen eines Proof of Concepts in Ihrer eigenen Umgebung.
Natürlich können APM und ARM separat voneinander eingeführt werden, da es sich, wie bereits erwähnt, um zwei separate Produkte handeln, die sich jedoch optimal ergänzen.
In allen angesprochenen Schritten kann Ihnen Computacenter als Partner zur Seite stehen. Wir unterstützen Sie bei der Analyse Ihrer Services und erstellen zum Beispiel Servicebeschreibungen. Aufgrund unserer Expertise zu verschiedenen Produkten im Bereich APM und ARM können wir Sie sowohl bei der Toolauswahl als auch bei der Implementierung mit unserem Know-how unterstützen und stehen bei Fragen an Ihrer Seite.

Die IT-Infrastrukturen in den Unternehmen werden immer komplexer und vielschichtiger. Mit jedem neu hinzugefügten Server steigt aber auch der Konfigurations- und Verwaltungsaufwand erheblich. Doch es gibt Abhilfe: Mit den Services von Computacenter lassen sich Infrastrukturen einfacher als je zuvor bereitstellen, betreiben und skalieren. Dabei spielt auch „Infrastructure as Code“ eine zentrale Rolle.
Bei Infrastructure as Code (IaC) handelt es sich um einen modernen Lösungsansatz, bei dem sämtliche benötigten Schritte zum Aufsetzen von Infrastruktur und zum Durchführen von Softwarebereitstellungen im Quellcode hinterlegt werden. Konfigurationsänderungen an Infrastrukturkomponenten wie Servern, Betriebssystemen und Netzwerkdiensten werden nicht mehr direkt auf den jeweiligen Systemen, sondern in der zentralen Konfigurationsdatei vorgenommen und anschließend über spezielle Automation Tools auf die Systeme übertragen. Somit lassen sich alle Systemkonfigurationen testen, versionieren und automatisiert auf alle Systeme replizieren. Dies hat den entscheidenden Vorteil, dass alle Systeme wirklich identisch und beispielsweise Testergebnisse deutlich besser von einer Systemumgebung auf die nächste (zum Beispiel Development, Test, Integration, Produktion) übertragbar sind. Im Bereich DevOps und in Cloud-ähnlichen Bereitstellungsmodellen wird Infrastructure as Code von den Nutzern vorausgesetzt.
Im Umfeld der Public Cloud kann Infrastructure as Code ohne größere Vorbereitungen genutzt werden, da hier der Cloud-Anbieter APIs für alle Infrastrukturkomponenten wie Server, Storage und Netzwerk zur Verfügung stellt und alle physischen Komponenten bereits vom Cloud-Anbieter in Betrieb genommen wurden. Betrachtet man aber On-Premises-Umgebungen, so ist eine entsprechende Vorbereitung unabdingbar. Die Komponenten müssen mehr oder weniger aufwendig im Rechenzentrum konfiguriert werden, bevor die Mechanismen von IaC überhaupt anwendbar sind.
In der Vergangenheit betrachtete man die notwendigen Komponenten für den Betrieb von Rechenzentren in der Regel einzeln in Silos wie Server, Storage, Netzwerk und anderen Einteilungen. Der Trend der letzten Jahren ging zum Einsatz von konvergenten Infrastrukturangeboten mit Komponenten verschiedener Hersteller, die bereits aufeinander abgestimmt sind und für die es validierte Designdokumente gibt. Die bereitgestellten Dokumente reichen je nach Lösung bis hin zu vollständigen Installationsanleitungen.
Aber die Installation – hier spricht man von Day 1 Operations – dieser konvergenten Infrastrukturen ist trotz entsprechender Installationsanleitungen recht aufwendig. Für einige Hersteller gibt es proprietäre „Manager of Element Manager“-Lösungen, mit denen zwar gewisse Aufgaben erledigt werden können, jedoch eine Integration in eine umfassende Automatisierung nicht gelingt.
Im Rahmen eines Entwicklungsprojekts haben Consultants von Computacenter die Grundinstallation und Implementierung am Beispiel der Lösungen FlexPod (Cisco Server und Netzwerk mit NetApp Storage) sowie FlashStack (Cisco Server und Netzwerk mit Pure Storage) näher betrachtet. Die Basis hierfür bildete das jeweils aktuelle validierte Design der Hersteller für die Nutzung der Komponenten unter Einbeziehung der Cisco-Netzwerk-Virtualisierung mit Cisco ACI.
In einer ersten Analyse betrachteten die Consultants die Aufwände, die mit der Installation der Komponenten im Datacenter beginnen und bis zum Beginn der Installation des Betriebssystems entstehen. Für einen FlexPod sind es rund 700 Klicks beziehungsweise Eingaben, die aufgrund der verschiedenen Technologien in der Regel von Personen aus den verschiedenen Know-how-Bereichen durchgeführt werden müssen. Ähnliche Aufwände konnten bei der FlashStack-Architektur mit 542 Klicks festgehalten werden. Wichtig dabei sind weniger die reinen Aufwände in Zeiteinheiten, die theoretisch durch viel Übung der Mitarbeiter auf wenige Stunden reduziert werden können, sondern die schiere Menge an Fehlerquellen und potenziellen Abweichungen von der geplanten Konfiguration.
Zur Konfiguration dieser Infrastruktur wurden teilweise über die Hersteller spezifische Infrastruktur-Manager bereitgestellt. Diese reduzieren teilweise die nötigen Aufwände. Da diese Manager in der Regel aber eben herstellerspezifisch sind, bieten diese nur geringe Möglichkeiten der Einbindung von „Fremd“-Infrastruktur, wenn hierüber eine gesamtheitliche Automatisierung angestrebt werden soll.
Darüber hinaus müssen einige Systeme – bevor diese überhaupt mit einem Remote-Zugriff genutzt werden können – zunächst manuell mit einer IP-Adresse und weiteren Daten versehen werden. Hier spricht man von den sogenannten Day 0 Operations. Dies erfolgt auch in der heute schon gut automatisieren Welt der Rechenzentren nicht selten per serieller Verbindung und einem Laptop aufwendig im Rechenzentrum selbst direkt am System.
Computacenter hat es sich daher zur Aufgabe gemacht, genau diese Day 0 und Day 1 Operations ebenfalls zu automatisieren und damit On-Premises-Infrastrukturen optimal an IaC-Konzepte anzupassen, die die Basis-Implementierung der Hardware voraussetzen, beziehungsweise die Bereitstellung zu optimieren.
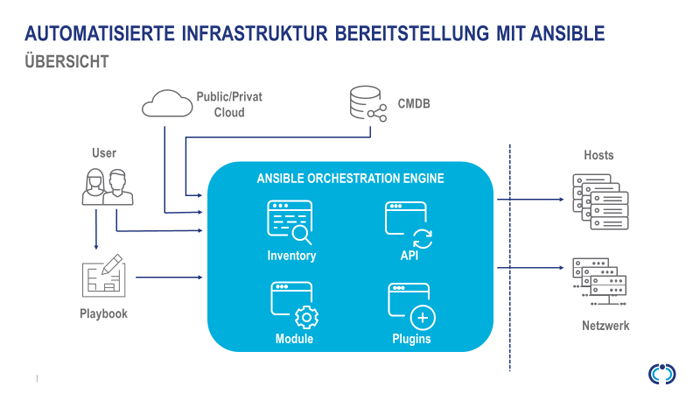
Nach einer entsprechenden Markterkundung der verschiedenen Lösungen, die aktuell am Markt verbreitet sind, und einer intensiven Abstimmung mit verschiedenen Hardwareherstellern favorisieren die Consultants von Computacenter nun die Nutzung von Red Hat Ansible. Diese Lösung bietet als Automation-Plattform eine Grundlage für die Entwicklung und Ausführung automatisierter Prozesse im gesamten Unternehmen. Die Plattform umfasst alle Tools, die zur Implementierung unternehmensweiter Automatisierungsprozesse in der IT erforderlich sind. Ansible ist ein Open-Source-Automatisierungswerkzeug und nutzt für die Verwaltung von Systemen die vorhandenen Möglichkeiten der Zielsysteme zur Remote-Administration – wie beispielsweise SSH – und erfordert keinerlei zusätzliche Software auf dem zu verwaltenden System. Zur Erweiterung von Ansible kommen Ansible-Module zum Einsatz, die eigenständig und in einer beliebigen Programmiersprache geschrieben sein können. Da sich Ansible in den letzten Jahren zum Quasi-Standard im Bereich der Infrastrukturautomatisierung entwickelt hat, werden diese Module oft direkt von den Herstellern der Zielsysteme selbst erstellt oder von der Open Source Community entwickelt und gepflegt. Dabei sollten die Module idempotent sein, was bedeutet, dass selbst wenn ein Vorgang mehrfach wiederholt wird – zum Beispiel bei der Wiederherstellung nach einem Ausfall –, das System immer in denselben Zustand versetzt wird.
Die eigentliche Konfiguration der Infrastruktur wird in sogenannten Playbooks beschrieben. Das Playbook-Format ist YAML. Neben den Playbooks und Modulen spielt das Inventar in Ansible eine wichtige Rolle. Dies beinhaltet alle Systeme in Gruppen, auf die ein Playbook angewandt werden soll. Wenn nun neue Systeme der Infrastruktur hinzugefügt werden, müssen diese lediglich ins Inventar aufgenommen werden. Beim nächsten Ausführen des Playbooks werden sie dann exakt wie alle anderen Systeme in der Gruppe konfiguriert.


Das Multi Cloud Management ist so vielfältig wie die Infrastrukturen, die Strategien und die damit verbundenen Aufgaben für die IT-Bereiche in den Unternehmen. Daher lassen sich nicht pauschal Werkzeuge empfehlen, die das Multi Cloud Management erleichtern können. Computacenter hilft Ihnen gern dabei, die speziell zu Ihren Bedürfnissen passenden Tools zu finden.
In einer vorhergehenden Ausgabe des Datacenter-Newsletters haben wir Ihnen die Rolle der IT-Bereiche als Cloud Service Broker oder Multi Cloud Provider vorgestellt. Damit sind zahlreiche Aufgaben verbunden, die allesamt das Ziel verfolgen, dass die Geschäftsbereiche Cloud Services schnell, einfach, sicher und den Unternehmensregeln entsprechend nutzen können. Um diese vielfältigen Aufgaben möglichst effektiv erfüllen zu können, bietet der Markt diverse Werkzeuge für das Multi Cloud Management. Welche davon optimal zu Ihnen und Ihrer IT-Umgebung passen, hängt wesentlich von den jeweiligen Aufgaben und von Ihrer Strategie ab.
Die Cloud-Strategien der Unternehmen lassen sich – in ihrer Reinform – in zwei Lager einteilen:
Die meisten Kunden von Computacenter fallen in die zweite Kategorie, das heißt, die Anwender sollen alle Möglichkeiten der Cloud Services nutzen können. In unzähligen Beratungsgesprächen hat sich gezeigt, dass es am besten ist, wenn die IT sich um das virtuelle Rechenzentrum kümmert und die Anwendungsentwickler die Bedarfe der Geschäftsbereiche nach bestimmten Anwendungen erfüllen.
Die konkreten Aufgaben, die die IT-Bereiche für den Cloud-Betrieb übernehmen, variieren von Unternehmen zu Unternehmen – und damit auch die Werkzeuge für das Multi Cloud Management. Hinzu kommt, dass es für jede Aufgabe verschiedene Werkzeuge mit unterschiedlichen Funktionalitäten und Leistungsmerkmalen gibt, sodass die optimale Zusammenstellung der Werkzeuge sehr individuell ist. Einige Aufgaben und mögliche passende Werkzeuge sind beispielsweise:
Bitte beachten Sie, dass es sich hierbei nur um einige Beispiele handelt, nicht um Empfehlungen. Welche Werkzeuge tatsächlich geeignet sind, hängt von den konkreten Zielen und Aufgaben ab und kann stark variieren.
Möchten Sie herausfinden, wie Sie Ihr Cloud Management möglichst effektiv und kostengünstig betreiben können? Ihr Ansprechpartner bei Computacenter kennt die Werkzeuge, die Ihnen eine optimale Unterstützung bieten. Lassen Sie sich am besten gleich individuell beraten!

Seit Jahren wachsen die File Services exponentiell und erreichen mehrere Hundert Terabyte bis hin zu Petabyte an Daten. Abgelegt auf skalierbaren Network-Attached-Storage-Plattformen sind die Daten hochverfügbar und redundant abgelegt. Wie aber verhält es sich mit der Backup/Restore-Strategie? Wie können Petabyte an Daten gesichert und wiederhergestellt werden?
Anfang des Jahrtausends hat NetApp als Pionier eine Network-Attached-Storage-Plattform (NAS) auf Basis von OnTap auf den Markt gebracht. Heutzutage sind NAS-basierte Plattformen verschiedener Hersteller (beispielsweise auch Dell EMC Isilon und Hitachi NAS (HNAS)) für die zentralen File Services, aber auch für die Ablage von Forschungs- und Entwicklungsdaten etabliert. Mittlerweile liegen auf den NAS-Plattformen oft mehrere Hundert Terabyte bis Petabyte an Daten.
Selbstverständlich bieten die NAS-Plattformen eine hochverfügbare Konfiguration, bei der alle Daten redundant über mindestens zwei Brandbereiche verteilt und effizient gespeichert werden. Zusätzlich steht ein Snapshot-Modell für eine Absicherung und Versionierung der Daten an den primären File-Service-Plattformen zur Verfügung, mit denen Aufbewahrungsfristen (Versionierung) von oft 30 Tagen abgebildet werden.
Mit diesen Plattformen sind Unternehmen gerüstet, trotz des exponentiellen Datenwachstums die relevanten Daten effizient und sicher zu speichern. Ist also für NAS-Plattformen überhaupt eine Datensicherung nötig?
Eine Datensicherung ist per Definition eine von den Primärdaten brandtechnisch getrennte Kopie der Daten inklusive einer Versionierung gemäß den vereinbarten Aufbewahrungsfristen. Dabei wird eine Datenspiegelung als Datensicherungskopie durch das BSI explizit ausgeschlossen. Weiterhin dient die Datensicherung nicht nur als Schutz gegen unabsichtliche Löschung oder Beschädigung von Daten, sondern auch als Schutz gegen absichtliche Datenlöschung.
Ableitend daraus ergeben sich unter anderem die folgenden Anforderungen an eine Datensicherung:
Weitere Maßnahmen finden sich in den Umsetzungshinweisen zum Baustein CON.3 des Datensicherungskonzepts des BSI.
Wichtig ist, dass Begriffe wie Medienbruch oder eine Gleichsetzung von Medien mit Bandmedien nicht im Baustein CON.3 gefordert wird. Vielmehr werden bei der beispielhaften Benennung von Medien Festplatten mit aufgeführt.
Diese Anforderungen leiten zu der Schlussfolgerung, dass eine Datensicherung für NAS-Plattformen erforderlich ist. Und weder eine Snapshot-Historie an den primären NAS-Systemen noch eine Datenspiegelung über zwei Brandbereiche können die Datensicherung ersetzen.
Die Datenmengen sind eine Herausforderung, da ein Restore von getrennten Medien (Backup-to-Disk oder Backup-to-Tape) für Petabyte an Daten technisch bedingt einen zu langen Zeitraum beansprucht.
Eine kleine Beispielrechnung illustriert diesen Punkt. Nehmen wir an, dass im Unternehmen eine über zwei Brandbereiche gespiegelte NAS-Plattform implementiert ist, die pro Rechenzentrum zwei Controller bereitstellt. Jeder dieser insgesamt 4 Controller kann Backup-Daten an die Datensicherungslösung senden und bei einem Restore entgegennehmen. Nehmen wir weiterhin an, dass optimistische 200 MB/s an Restore-Performance pro Controller erreicht werden. Damit werden pro Stunde rund 2,5 TB an Daten eingelesen. Somit liegt die Restore-Performance bei etwa 17 Tagen pro Petabyte. Zugegeben, die Eintrittswahrscheinlichkeit für einen kompletten Restore der NAS-Plattform ist nicht sehr hoch – aber es ist nicht auszuschließen. Dies ist analog zu einer Brandschutzversicherung zu sehen.
Welche alternativen Modelle gibt es – wenn ein Streaming-Backup/Restore, wie im Beispiel dargestellt, die geforderte RTO nicht erfüllt?
Der gängige Ansatz ist ein „Replicated Snapshot“. In diesem Modell wird eine separate NAS-Plattform dediziert für die Datensicherung etabliert und durch die Backup-Administration verwaltet (separate Rechte und Rollen für Primär- und Sekundärdaten). Auf dem primären NAS-System werden in regelmäßigen Abständen Snapshots generiert und anschließend werden die Daten, basierend auf den RPO-Vorgaben, auf das Backup-NAS basierend auf einem kontinuierlichen inkrementellen Modell übertragen.
Basierend auf diesem Modell steht eine getrennte Kopie der Primärdaten unter Kontrolle der Backup-Administration zur Verfügung. Da in Deutschland die meisten Unternehmen über zwei Rechenzentren (zwei Brandbereiche) verfügen und sich die Primärdaten meist symmetrisch auf beide Brandbereiche verteilen, muss für die erforderliche brandtechnische Trennung der Backup-Daten entweder eine dedizierte Backup-NAS-Plattform pro Rechenzentrum etabliert werden oder es wird ein separater Backup-Raum erforderlich.
Hierüber gehen die Meinungen in der Tat auseinander. Bei einer erfolgreichen Ransomware-Attacke werden die Unternehmensdaten beispielsweise verschlüsselt – und das gilt für die veränderbar abgelegten Daten. Und Backup-Daten, die auf einem Backup-NAS abgelegt werden, können grundsätzlich modifiziert werden.
Daraus leitet sich die Anforderung nach einem Immutable Storage ab. In diesem Modell werden die Backup-Daten unveränderlich (Read only) abgelegt. Hier ist konzeptionell genau zu betrachten, wie diese unveränderliche Speicherung umgesetzt ist. Im einfachsten Fall sind das Dateiattribute, die durch die Administration verändert werden können. Das wird durch ein von den Primärdaten getrenntes Administrationskonzept für die Datensicherung adressiert, aber nicht vollständig abgefangen. Hier sind weitergehende technische und organisatorische Modelle (Vier-Augen-Prinzip, technische Sicherstellung eines Immutable Storage) erforderlich.
Verschiedene Blogeinträge (beispielsweise dieser bei Security Boulevard) und Artikel (beispielsweise dieser bei Redmond) empfehlen die Verwendung von getrennten Medien, die auch offline (Air-Gap) vorgehalten werden. Letztendlich hängt die Entscheidung von der Risikobewertung für das jeweilige Unternehmen ab. Ein Medienbruch durch die Sicherung der NAS-Plattform unter Verwendung des Protokolls NDMP auf Backup-to-Disk, Cloud- oder Bandmedien ist technisch möglich und erfüllt die Anforderungen, einen Medienbruch sicherzustellen. Diese Backup-Kopie ist jedoch aufgrund der damit verbundenen RTO-Zeiten eine absolute Notfallkopie, während voraussichtlich 99 Prozent aller Restores aus dem trotzdem empfohlenen „Replicated Snapshot“ und den primären Snapshots bedient werden.
Um bei den sehr großen Datenmengen eine schnelle Datensicherung – zumindest bezogen auf das Backup – sicherzustellen, wird der Einsatz von sogenannten Accelerator-Technologien empfohlen. Accelerator liefern zwei wesentliche Funktionen:
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren. Rufen Sie am besten gleich an.

Bei der Mehrzahl der Unternehmen und unserer Kunden befinden sich Container-basierte Plattformen auf Basis von Kubernetes im Aufbau oder bereits in der Produktion. Softwareentwickler und DevOps-Teams verwenden diese Plattformen, um moderne Applikationen zu entwickeln, die aus mehreren Micro Services bestehen. Die Grundlage dazu bilden Build- und Release-Pipelines für Continuous Integration und Delivery (CI/CD). Aber wie „Cloud-native“ sind diese Pipelines?
Vor knapp 20 Jahren haben sich CI-Lösungen in der Softwareentwicklung etabliert und es wurden – und werden – dedizierte Plattformen für einen meist zentralen CI/CD-Service aufgebaut. Eine der bekanntesten Technologien ist Jenkins, womit sich komplexe Pipelines und CI/CD-Prozesse realisieren lassen. Dies umfasst oft größere und sehr schnell komplexe Umgebungen mit einer Vielzahl von virtuellen Maschinen und definierten Release-Prozessen, die grafisch über eine Web-Oberfläche implementiert und gesteuert werden.
In den Unternehmen sind Experten-Teams dafür verantwortlich, den CI/CD-Service zu betreiben und diesen den verschiedenen Developer-Teams zur Verfügung zu stellen. Die CI/CD-Services selbst fokussieren sich primär auf den Bau der Applikationen und verbunden damit der Binaries und Artefakte – der Übergang in die Produktion ist häufig ein nachgelagerter Schritt, der oft noch einen Übergabeprozess an eine Betriebsmannschaft beinhaltet.
Die Softwareentwickler transformieren sich zu DevOps-Teams, die eine Ende-zu-Ende-Verantwortung für den jeweils verantworteten Micro Service haben. Das bedeutet, die DevOps-Teams müssen sicherstellen, dass bei Code-Änderungen und -Erweiterungen diese neuen Funktionen durchgängig bis in die Produktion umgesetzt und deployed werden. Dazu werden CI/CD-Pipelines verwendet, die mit den Cloud-native Application Platforms auf der Basis von Containern und Kubernetes verheiratet werden müssen.
Grundsätzlich kann hierzu eine Integration mit zentralen CI/CD-Services erfolgen. Allerdings wurden die CI/CD-Tools entwickelt, als es noch keine Container und Plattformen wie Kubernetes gab. Daher werden heutzutage noch viele Funktionen separat in der CI/CD-Plattform implementiert, die sich in einer modernen Architektur durch die Cloud-native Application Platform implementieren ließen.
Zur Definition von Micro Services gehört die Unabhängigkeit dieser Services von anderen Tools, Komponenten und Bausteinen. Dafür spricht auch eine Unabhängigkeit von zentralen CI/CD-Services.
Typische Anforderungen moderner CI/CD-Services in Verbindung mit einer Cloud-native Platform sind zum Beispiel:
Als Open Source Community für die Entwicklung und Vermarktung von nativen CI/CD-Lösungen für die Cloud-native Application Platform hat sich die CD Foundation gebildet, die verschiedene Projekte wie Tekton und Jenkins X vorantreibt, welche das Ziel von Kubernetes-nativen CI/CD-Lösungen verfolgen.
Während die Lösungen heutzutage noch keinen vollständigen Ersatz für bestehende CI/CD-Plattformen darstellen, können jedoch in Kombination mit weiteren bestehenden Lösungen Cloud-native Modelle geplant und implementiert werden.
Computacenter hat die verschiedenen Lösungen im Solution Center implementiert und kann sie in einer Live-Demonstration zeigen sowie Best Practices benennen, wie moderne CI/CD-Services in Verbindung mit Kubernetes für die Softwareentwickler und DevOps-Teams implementiert und genutzt werden können. Das reicht hin bis zu einem CI/CD as a Service basierend auf Cloud-native Application Platforms.
Computacenter steht Ihnen gern jederzeit bei Fragen und auch für eine Live-Demo zu den neuen Technologien und Best Practices zur Verfügung. Wenden Sie sich bei Interesse einfach an Ihren Ansprechpartner bei Computacenter.