VMware Cloud on AWS

Mit VMware Cloud on AWS gelingt die Migration in die Public Cloud sicher und schnell, selbst Workloads lassen sich ohne großen Aufwand verschieben. In dieseraktuellen Ausgabe unseres Datacenter-Newsletters stellen wir Ihnen unser erprobtes 4-Phasen-Modell vor, mit dem auch Sie in kürzester Zeit von der Effizienz von VMware Cloud on AWS profitieren können.
Daten stammen in der heutigen Zeit aus den verschiedensten Quellen, gleichzeitig ist das Datenaufkommen sprunghaft angestiegen. Mit Splunk on AWS lässt sich dieser Schatz unkompliziert zugänglich und nutzbar machen – sodass Ihr Unternehmen daraus Antworten auf wichtige Geschäftsfragen ableiten und Planungsstrategien erhalten kann. Wir zeigen Ihnen, wie das funktioniert.
Lesen Sie außerdem, wie künstliche Intelligenz Sie bei Ihren Prozessen unterstützen kann und inwiefern AI at the Edge, also der Einsatz von künstlicher Intelligenz am Rande der IT-Infrastruktur, realisiert werden kann – und welche Vorteile sich ganz praktisch für Sie daraus ergeben.
Künstliche Intelligenz ist auch das Thema eines weiteren Artikels dieser Ausgabe, konkret geht es darin um Artificial Intelligence for IT Operations (AIOps). Damit lässt sich sicherstellen, dass auch bei den vielfältigen neuen Technologien, Infrastrukturen und Applikationen, die in den letzten Jahren in der Unternehmens-IT Einzug gehalten haben, die Betriebssicherheit, Kostentransparenz und Sicherheit gegeben sind.
In unserer aktuellen Backup-Kolumne erfahren Sie, welchen Nutzen Backup as a Service unter welchen Bedingungen hat. Und unsere Agile-IT-Kolumne zeigt auf, inwiefern GitOps Sie dabei unterstützen kann, Applikationen und die dafür notwendigen Infrastrukturen automatisiert einzurichten und zu betreiben.
Wie immer freuen wir uns über Ihr Feedback, damit wir die Schwerpunkte aufgreifen können, die für Sie von Interesse sind.
Herzliche Grüße
Markus Kunkel
Group Partner Management
Die Information Services Group (ISG) hat Computacenter für Deutschland und Großbritannien als Marktführer in den Kategorien Digital Workplace Consulting Services, Managed Workplace Services und Managed Mobility Services positioniert.
Weitere InfosComputacenter konnte seinen adjustierten Gewinn vor Steuern in Deutschland um 38,1 Prozent auf 125,7 Millionen Euro (2019: 91 Millionen Euro) steigern. Hingegen sank der Umsatz leicht um 2,5 Prozent auf 2,108 Milliarden Euro (2019: 2,161 Milliarden Euro).
Weitere Infos
Möchten Sie „mit einem Klick“ Ihre Reise in die Cloud starten, Applikationen migrieren und Ihre Infrastruktur in Sekunden erweitern können? VMware Cloud on Amazon Web Services (AWS) bringt die Software-definierten Rechenzentren von VMware in die AWS Cloud und ermöglicht all das. Wir zeigen Ihnen die Vorteile und die beste Vorgehensweise von der Analyse bis hin zur Migration.
Wollen Unternehmen ihr Rechenzentrum erweitern und Applikationen in die Cloud migrieren, benötigen sie eine sichere Plattform, die alle zugehörigen Schritte abbilden kann. VMware Cloud on AWS ermöglicht Kunden die Ausführung von Anwendungen in VMware-vSphere-basierten Umgebungen inklusive eines optimierten Zugriffs auf AWS-Services.
Einfache Migration: Die Migration in die Public Cloud ist schnell sowie effizient und mit einem geringen Risiko verbunden. Denn es werden dieselben Tools und Prozesse wie bei einer On-Premises-Umgebung genutzt, dasselbe gilt für das benötigte Know-how.
As-a-Service: VMware Cloud on AWS bringt die Software-Defined-Datacenter-Software von VMware in die AWS Cloud. So können Kunden Produktionsanwendungen auf privaten, öffentlichen und Hybrid-Cloud-Umgebungen, die auf VMware vSphere basieren, mit optimiertem Zugriff auf AWS-Services ausführen. Eine langfristige Planung und hohe Investitionen sind dazu nicht erforderlich, die Kosten berechnen sich nach der Nutzung.
Bekannte Technologie: Es wird durchgehend die gleiche VMware-Technologie wie im eigenen Rechenzentrum genutzt, angefangen von ESXi und vCenter bis hin zu vSAN und NSX-T.
Portierbarkeit: Workloads lassen sich einfach und ohne großen Aufwand verschieben, eine Neukonfiguration der VM ist nicht notwendig. Bei der Migration mit vMotion wird eine eingeschaltete VM von einem Host oder Datenspeicher zu einem anderen verschoben. Diese Art der Migration ist die beste Option, um eine kleine Anzahl von VMs zu migrieren, ohne dass es zu Ausfallzeiten kommt.
Wie startet man ein VMware-Cloud-on-AWS-Projekt? Computacenter folgt einem 4-Phasen-Modell zur Analyse, Beurteilung, Planung und Migration. Im Rahmen dieses Modells beginnen wir damit, den Ist-Zustand unserer Kunden genau unter die Lupe zu nehmen, um ihre Anforderungen optimal zu analysieren und umzusetzen. Mit unserer Erfahrung und unseren Tools können wir ihre Situation noch besser erfassen, um einen maßgeschneiderten Lösungsweg aufzuzeigen. Das Sprichwort „Gut geplant ist halb gewonnen“ spielt für eine reibungslose Migration eine besonders große Rolle. Während die Planung der Migration etwa 80 Prozent ausmacht, fließen in die spätere Umsetzung etwa 20 Prozent der Aufwände.
Der entscheidende Punkt für eine erfolgreiche Einführung von VMware Cloud on AWS ist ein Assessment der bestehenden VMware-Infrastruktur. Nur so lässt sich ermitteln, wie viele Ressourcen in der Cloud benötigt werden und welche Migrationsstrategien für den Kunden am besten geeignet sind. Unser Assessment dauert in der Regel nur wenige Tage.
Gemeinsam mit unserem Kunden erarbeiten wir auf Basis aller ausgewerteten Daten eine Migrationsstrategie. Diese beinhaltet konkrete Workflows für eine erfolgreiche Migration in die Cloud. Völlig unabhängig davon, welchen Einsatzzweck Sie mit VMware Cloud on AWS verfolgen, wir helfen Ihnen dabei, dass Ihre Migration ein Erfolg wird!
Schlussendlich werden Technologien und Architekturen immer daran gemessen, ob sie für einen bestimmten Einsatzzweck (Use Case) geeignet sind. Ist die Architektur für die Applikation von Vorteil? Zahlt sich die Technologie aus? Unterstützt sie meine IT-Strategie? Können wir damit die Betriebskosten senken? Im Rahmen der Analyse und Bewertung von VMware Cloud on AWS stellen wir viele Fragen, um diejenigen Use Cases zu erarbeiten, für die sich diese Architektur sinnvoll einsetzen lässt.
Wenn Sie den VMware Stack für die Virtualisierung in Ihrem Rechenzentrum einsetzen, lässt sich die vorhandene Infrastruktur sehr einfach und schnell mit VMware Cloud on AWS erweitern. Kapazitätsengpässe im Rechenzentrum, beispielsweise aufgrund einer zu geringen Stromzufuhr oder Kühlung, dringend benötigte zusätzliche Hardware für neue Anwendungen, Umbauarbeiten in Brandabschnitten, ein begrenztes IT-Investitionsbudget oder sehr stark schwankende Anforderungen an Test-Dev-Umgebungen sind beispielhafte Gründe für die Nutzung von VMware Cloud on AWS.
Weltweit wird VMware Cloud on AWS für Disaster Recovery (DR) genutzt. Ein DR-Rechenzentrum erfordert hohe Investitionen. Diese werden als „Versicherung“ angesehen, in der Hoffnung, sie niemals nutzen zu müssen. Die komplette Investition in ein DR-Rechenzentrum lässt sich jedoch in ein „DR-Rechenzentrum als Service“ umschichten. Damit werden Mittel für andere Investitionen frei, die das Geschäftsmodell voranbringen können.
Auch für die Migration in die Cloud kann der Einsatz von VMware Cloud on AWS sinnvoll sein. Die Migration einer Applikation von Ihrem Rechenzentrum (VMware Stack) zum AWS-Rechenzentrum (VMware Stack) erfordert nicht mehr als einen Mausklick im vSphere-Administrationsportal. Sie ist einfach, schnell und hat keinerlei Auswirkungen auf die Funktionalität der Applikation. Sogar die notwendigen Netzwerk-Parameter lassen sich automatisch anpassen, sodass die Anwendung in AWS sofort verfügbar ist. Einer der Treiber für dieses Szenario ist ein notwendiger Hardware-Tausch (Refresh).
Werden Applikationen auf VMware Cloud on AWS betrieben, ist die Integration weiterer originärer AWS-Services (oder Services des AWS Marketplace) sehr einfach. Damit wird die Erweiterung der Funktionalität von Applikationen, die Nutzung von künstlicher Intelligenz, Analytics Services oder die Umstellung auf eine neue Applikationsplattform vereinfacht. VMware Cloud on AWS bietet viele Vorteile für die Modernisierung von Anwendungen. Aufgrund der Integration von VMware Cloud on AWS in Ihr eigenes Rechenzentrum ist die Architektur von hybriden Applikationen möglich.
Jede AWS-Region hat ihre eigene Kostenstruktur und eigene Verfügbarkeitsanforderungen, so lassen sich die Kosten für jeden Use Case individuell bewerten. Dabei hat selbstverständlich jeder Kunde die freie Wahl, welche Services er nutzt. Die Kosten für VMware Cloud on AWS beinhalten:
Die wichtigste Stellschraube für die Kosten ist jedoch das richtige Sizing der Zielumgebung. Bei einer 1:1-Abbildung der aktuellen VMware-Umgebung, beispielsweise ein vSphere-Cluster mit 50 Applikationen, liegen die Kosten für VMware Cloud on AWS deutlich höher als bei einer On-Premises-Umgebung. Allerdings sollten Sie dabei berücksichtigen, dass es sich bei VMC on AWS um ein Full-Service-Angebot handelt. Dabei stellt AWS die Hardware und kümmert sich um diese, VMware ist für den Betrieb und die Updates der Infrastruktur verantwortlich. So muss sich der Kunde „nur“ noch um seine virtuellen Maschinen und Container kümmern, der Rest entfällt.
Die Einführung und Nutzung von VMware Cloud on AWS ist ein einfacher, schneller und effizienter Weg in die Cloud. Denn es ändert sich nichts zum traditionellen Betriebsmodell – der Service wird lediglich an einem anderen Ort und auf einer anderen Hardware erbracht. Die Cloud ist also nicht mehr als eine zusätzliche Lokation – und lässt sich mit den bewährten Tools für VMware verwalten.
Egal, welchen Use Case Sie mit VMware Cloud on AWS adressieren möchten, Computacenter ist der richtige Ansprechpartner dafür!

Machine Learning, Edge Computing, 5G, Cloud, Artificial Intelligence, Virtual Reality, Blockchain: In der heutigen Zeit können Daten viele Ursprünge und Gesichter haben. Die Nutzung von Splunk in der Cloud kann für Sie die optimale Lösung sein, um all diese unterschiedlichen Daten für Benutzer zugänglich und nutzbar zu machen. Dabei lässt sich Splunk durch eine Migration zu Amazon Web Services (AWS) einfach und beliebig skalieren.
Der Wechsel zu einer cloudbasierten Sicherheitsarchitektur bringt moderne Funktionen, bessere Skalierbarkeit und wirtschaftliche Vorteile mit sich und kann somit den Weg zu einem Cloud-zentrierten und für die digitale Transformation notwendigen Geschäftsmodell ebnen. Die Cloud wird dabei zur De-facto-Grundlage für eine digitale Infrastruktur.
Splunk Workloads sind für viele Unternehmen zu einem geschäftskritischen Service geworden, mit dem sie aus ihren Daten Antworten auf wichtige Geschäftsfragen ableiten und Planungsstrategien erhalten können. Die Transformation und Migration dieser Splunk Workloads kann aufgrund der zusätzlichen Funktionen in der Cloud, wie zum Beispiel Large-Scale-Analysen, einen besseren Return on Investment (ROI) erzielen.
Da immer mehr Anwendungen und Daten in die Cloud verlagert werden, steht die Migration von Workloads in die Cloud im Einklang mit übergeordneten Hybrid-Cloud- und modernen Sicherheitsstrategien. Workloads wie Splunk Enterprise Security oder IT Operations bilden wichtige Säulen in den Sicherheitsstrategien von Unternehmen, um schnell auf Sicherheitsvorfälle reagieren zu können und den Betrieb effizient zu gestalten. Damit sind sie das Herzstück eines Security Operations Center (SOC), Network Operations Center (NOC), eines IT Operations Center (OPC) oder eines Business Operation Center (BOC). Diese Workloads können jedoch komplex, datenintensiv und damit kostspielig werden.
Um wichtige Security- und Daten-Workloads wie von Splunk erfolgreich in der Public Cloud zu betreiben, sollten Unternehmen in die folgenden Bereiche investieren:
Darüber hinaus hat Splunk seine Data-to-Everything-Plattform durch neue Funktionen erweitert, um die Produktivität, Einblicke und Administration für verschiedene Bereiche wie IT-Operations, Security, DevOps und Business Analytics Teams zu verbessern. Um in der Ära der künstlichen Intelligenz und Analytik erfolgreich zu sein, müssen Unternehmen diese modernen, cloudnahen Funktionen schnell nutzen können, um geschäftliche Vorteile auszuschöpfen und gleichzeitig die Anforderungen einer Vielzahl von Personen zu erfüllen, ohne sich lange um Infrastrukturaufbau, Sizing und Basis-Betriebsaufgaben kümmern zu müssen. Insbesondere Manager mit Schwerpunkt auf Unternehmens- und Digitalstrategie, Betriebsleiter, Security-Verantwortliche und Center-of-Excellence-Teams sowie Technologieexperten profitieren von dieser Herangehensweise.
Neugierig? Sprechen Sie uns einfach an und wir stellen Ihnen die Vorgehensweise und die Lösungen von Computacenter gern im Detail vor.
Sie können, wenn Sie mögen, auch im Vorfeld unser Partner Spotlight und unsere Broschüre zum Thema für weitere Informationen nutzen.
Schauen Sie auch gern bei unseren Cloud-Angeboten vorbei.

Selbstfahrende Autos, Personenerkennung und intelligente Maschinen – die Möglichkeiten von Artificial-Intelligence(AI)-Lösungen versprechen ein enormes Potenzial. Die erfolgreiche Implementierung birgt jedoch eine Reihe von Herausforderungen, insbesondere in den Bereichen Datenmanagement, Skalierbarkeit und kontinuierliches Deployment. In Partnerschaft mit NetApp hat Computacenter einen Use Case entwickelt, in dem ein vollintegrierter Produktzyklus der Berechnung und tausendfachen automatisierten Verteilung eines Modells zur Bilderkennung auf Geräten am Rand der IT-Infrastruktur, der sogenannten Edge, realisiert werden kann.
Das Zukunftsthema Artificial Intelligence (AI; auf Deutsch: künstliche Intelligenz) ist in aller Munde – es verspricht ein enormes Wertschöpfungspotenzial von global 16 Billionen US-Dollar bis 2030 mithilfe bisher nicht oder nur sehr kostenintensiv erfassbarer Daten. Für jede Branche existiert eine Fülle an gewinnbringenden Anwendungsszenarien für künstliche Intelligenz: Über die automatische Maskenerkennung und Alarmierung im Security-Umfeld, die Lokalisierung von Gütern und Qualitätssicherstellung in der Fertigung bis hin zu Laufweganalyse und -Tracking von Kunden im Einzelhandel. Mit dem Einsatz moderner AI-Methoden wie automatisierter Bilderkennung können Vorgänge an jedem Ort erfasst, gespeichert, gebündelt und in Zahlen überführt werden und anschließend als Grundlage für (automatisierte) Entscheidungsprozesse dienen. Erkenntnisse können dabei nahezu in Echtzeit generiert und visualisiert werden, sodass schnell auf Änderungen reagiert werden kann.
Allein in Deutschland liegt das prognostizierte Wirtschaftswachstum in diesem Jahrzehnt bei 430 Milliarden Euro. Artificial Intelligence ist dabei längst kein Randthema mehr: Bereits 2019 erreichte das Thema AI das sogenannte „Produktivitäts-Plateau“ des Gartner Hype Cycle. AI-Technologien sind nicht länger nur ein Trend, sondern ein robustes Werkzeug moderner IT-Applikationen. Die bisherigen Erfahrungen deutscher Unternehmen mit AI-Lösungen zeigen eine Amortisierung der getätigten Investitionen innerhalb von ein bis zwei Jahren – die Corona-Pandemie wirkt hierbei nicht als Bremse sondern als zusätzlicher Innovationstreiber für das Thema AI bei vielen Entscheidern.
Bei der Implementierung von Artificial-Intelligence-Anwendungen im Enterprise-Umfeld stehen meist sogenannte „Edge Devices“ besonders im Fokus. Der Begriff „Edge“ bezeichnet dabei die äußeren Ebenen einer IT-Umgebung, die über keine permanente Internetverbindung verfügen müssen. Das können Devices in einem Lager- oder Warenhaus, aber auch ganze Züge oder Maschinen auf einer Baustelle sein, die von der zentralen IT-Infrastruktur getrennt sind. Aufgrund zu langer Latenzzeiten für viele Anwendungsszenarien erfolgt die notwendige Berechnung für beispielsweise eine Bilderkennung dabei direkt auf dem jeweiligen Edge Device – dieser Vorgang wird „Edge Computing“ genannt.
Edge Devices sind dabei oftmals Endgeräte des Internets der Dinge (IoT), Gateways und Controller, die nur sehr begrenzte Rechenkapazitäten aufweisen. Damit AI-Modelle auf diesen Geräten zum Einsatz kommen können, müssen sie von leistungsstarken Maschinen vorberechnet werden. Einmal errechnet und transformiert können AI-Applikationen auf Edge Devices kontinuierlich und autonom betrieben werden.
Obwohl der potenzielle Nutzen von AI-Applikationen enorm ist, reagieren Unternehmen bei der Implementierung oft noch zögerlich. Nur 18 Prozent der befragten Unternehmen der PwC AI Predictions Survey 2020 haben bereits mehrere AI-Projekte implementiert, viele der Befragten scheuen dabei die als stark wahrgenommenen Risiken.
Zwei der größten Herausforderungen bei der Implementierung von AI-Projekten sind das Management der anfallenden großen Datenmengen sowie die hohen Hardwareanforderungen für die Berechnung von umfangreichen Artificial-Intelligence-Modellen. Die Erstellung eines Prototyps ist meist noch auf einfacher Hardware wie einem Laptop mit GPU oder mithilfe eines Workflows über die großen Cloud Provider möglich. Bei der Skalierung und dem Deployment eines errechneten AI-Modells kann es ohne ausreichende Planung jedoch schnell kompliziert und kostspielig werden.
Für die Implementierung von Bilderkennung müssen Modelle mithilfe von GPUs trainiert werden, damit sie auf Edge Devices mit geringer Rechenleistung eigenständig funktionieren und Berechnungen in Echtzeit liefern können. Spezielle Datacenter-GPUs wie beispielsweise die Karten der Tesla-Serie von Nvidia müssen hierbei in die Datenpipeline integriert und entsprechende Zugriffsberechtigungen festgelegt und überwacht werden.
Sollen passende Bild- und Videodaten für eine Optimierung der AI-Algorithmen gesammelt und gespeichert werden, gilt es, eine datenschutzkonforme Verarbeitung sicherzustellen. Je nach Anwendungsszenario können zudem schnell mehrere Terabyte an Material anfallen. Hierfür braucht es ein ganzheitliches Konzept für das verteilte Datenmanagement und den Aufbau eines Produkt-Lebenszyklus. Welche Daten sollen temporär, welche dauerhaft vorgehalten werden? An welchen Punkten der IT-Infrastruktur müssen Daten für den Zugriff bereitstehen und wie ist eine Integration mit Cloud Storage Providern möglich? Wie kann ein kontinuierliches Deployment sichergestellt und überwacht werden?
Für die Beantwortung all dieser Fragen bieten wir von Computacenter Ihnen gemeinsam mit unseren Partnern eine übergreifende und vollumfassende Lösung aus einer Hand – ganz nach Ihren individuellen Anforderungen und Vorstellungen. Anhand eines eigens entwickelten Use Cases in Zusammenarbeit mit unserem langjährigen Partner NetApp möchten wir Ihnen im Folgenden eine mögliche Implementierung einer AI-Anwendung mit Edge Devices und zentraler Modellberechnung vorstellen.
In unserem Use Case beschreiben wir die Implementierung eines Bilderkennungs-Algorithmus zur Sammlung und Analyse des Lauf- und Einkaufverhaltens von Kundinnen und Kunden in mehreren Supermarktfilialen. Hierbei implementieren wir einen vollumfänglichen IT-Produktzyklus, der eine kontinuierliche Erfassung auch im Falle einer Unterbrechung des Internetzugangs sicherstellt.

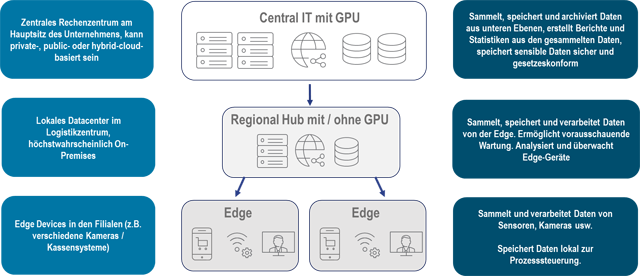
Zur Erstellung oder Optimierung der Bilderkennung können relevante Bilddaten aus den so entstehenden regionalen Data Lakes aller regionalen Rechenzentren in einen Unified Data Lake am Hauptfirmensitz verschoben werden und durch das Datenanalyse-Team verarbeitet werden. Für die Modellberechnung wird dort ein hochperformantes DGX-System von Nvidia eingesetzt, welches Computacenter als zertifizierter Reseller in Deutschland vertreibt. Das notwendige Rollenmanagement für die Nvidia-GPUs wird durch den Einsatz eines OpenShift-Clusters sichergestellt.
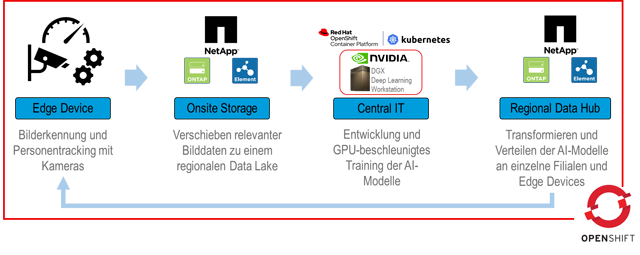
Erfasste Tracking-Daten aus der Bilderkennung werden über dieselbe Infrastruktur gespeichert und verteilt. Mithilfe eines Live-Dashboards können verschiedene Metriken wie beispielsweise die aktuelle Auslastung jeder Filiale oder ungewöhnliche Abweichungen im Kundenverhalten in Echtzeit analysiert und an jedem Ort angesehen werden – im jeweiligen Geschäft, in den regionalen Zweigstellen oder in der Firmenzentrale.
Über die langjährige Partnerschaft mit NetApp, Red Hat und Nvidia ist Computacenter der beste Partner für skalierbare containerbasierte Lösungen für jede Stufe der Datenverarbeitungspipeline. Für alle Schritte von der Konzeption über die Hardware- und Softwarebeschaffung bis hin zum Aufbau eines vollintegrierten und kontinuierlichen AI-Produktzyklus bieten wir Ihnen in enger Abstimmung mit unseren Partnern eine übergreifende und vollumfassende Lösung aus einer Hand – ganz nach Ihren individuellen Anforderungen und Vorstellungen.
Gern beraten wir Sie in einem individuellen Gespräch mit einer Live-Demonstration unserer Lösung. Sprechen Sie uns einfach an!

Multi Cloud ist die neue Normalität. Hybrid IT ebenso, hinzu kommt die Automation an allen Ecken und Enden! Damit begegnen Unternehmen den Anforderungen, die das Business stellt. Aber wie betreibt man all das, was in den letzten Jahren an neuen Technologien, Infrastrukturen und Applikationen in der Unternehmens-IT Einzug gehalten hat, so, dass die Betriebssicherheit, Kostentransparenz und Sicherheit gegeben sind?
Artificial Intelligence for IT Operations – oder kurz: AIOps – ist ein von Gartner im Jahr 2014 publizierter Ansatz, der bei den oben angerissenen Themen helfen kann.
Die von Gartner genutzte Definition lautet: „AIOps-Plattformen nutzen Big Data, Machine Learning und andere fortschrittliche Analysetechnologien, um IT-Operations-Funktionen (Überwachung, Automation und Service Desk) direkt und indirekt durch proaktive, persönliche und dynamische Erkenntnisse zu verbessern. AIOps-Plattformen ermöglichen die gleichzeitige Verwendung mehrerer Datenquellen, Datensammlungsmethoden, Analysetechnologien (in Echtzeit und tiefgreifend) sowie Präsentationstechnologien.“
New Relic hat in einer Studie Ende 2019 bei deutschen IT-Entscheidern festgestellt, dass zwar 88 Prozent künstliche Intelligenz als wichtig oder sehr wichtig für die digitalen Geschäftsprozesse ansehen, aber 49,6 Prozent nichts mit dem Begriff AIOps verbinden.
AIOps ist, wenn man es verkürzt betrachtet, nichts anderes als die Nutzung von Methoden der künstlichen Intelligenz zur Steuerung von IT.
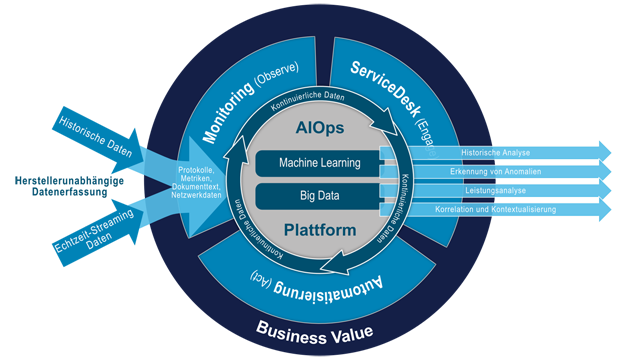
AIOps-Plattformen arbeiten vor allem in drei Bereichen:
Der Markt für AIOps-Werkzeuge hat sich in den letzten zwei Jahren deutlich vergrößert und man kann den Eindruck gewinnen, dass heute jeder Hersteller im Bereich des IT-Managements seine Produkte um AIOps-Funktionen angereichert hat.
Der Markt gliedert sich in vier Gruppen von Anbietern:
All die oben genannten Funktionen sind nicht ohne Weiteres erreichbar, denn neben Investitionen in entsprechende Plattformen sind auch Aufwände in der Anpassung der Arbeitsorganisation notwendig, um AIOps-Plattformen effektiv und effizient nutzen zu können. Insofern ist es wesentlich, vor einer Entscheidung eine Potenzialanalyse durchzuführen, um die notwendigen Maßnahmen und Aufwände beziffern zu können und den Wert der Investition greifbar und nachvollziehbar zu machen.
Die Einführung sollte nach der Potenzialanalyse in einem Phasenansatz geschehen. Dabei sollten Use Cases in den Vordergrund gerückt werden, bei denen aktuell durch die schon im Einsatz befindlichen Systeme nicht ausreichend Unterstützung des IT Operations Management vorhanden ist. Das sind häufig neue Applikationen wie Container- oder Cloud-Umgebungen.
Zum Start sollte man die Gesamtarchitektur (Big Picture) entwickeln, damit nicht nach der Umsetzung der ersten Use Cases Roadblocks das weitere Projekt behindern, die bei einer ganzheitlichen Betrachtung aufgefallen wären.
Computacenter hat in verschiedenen Projekten und mit verschiedenen Herstellern Erfahrungen in diesem Umfeld sammeln können. Wir haben einen Blueprint für die Architektur von IT-Servicemanagement- und IT-Operations-Management-Werkzeugen entwickelt, der beim Start in ein Projekt helfen kann. Bei Interesse freuen wir uns auf Ihre Rückmeldung.

Backup/Restore ist eine kritische und sensible Disziplin und Unternehmen müssen auf Grundlage der Regularien eine erfolgreiche Datensicherung nachweisen. Aber Backup/Restore stellt nur eine Absicherung der Daten bereit und liefert keinen konkreten Beitrag zum Erreichen der Unternehmensziele. Damit stellt sich die Frage, ob eine Backup-as-a-Service(BaaS)-Strategie sinnvoll ist. Dazu folgt hier der Versuch einer Einordnung von BaaS.
Um eine As-a-Service-Strategie zu definieren, sollten zuerst die Ziele und Aufgaben für diesen Service definiert werden.
Backup/Restore dient dem technischen Schutz der Unternehmensdaten vor Verlust, Beschädigung und Manipulation. Dazu sind die Daten regelmäßig zu sichern und in geeigneter Form aufzubewahren. Dazu ist zumindest eine brandtechnische Trennung der Backup-Daten von den produktiven Daten nötig. Mit Blick auf die technische Absicherung gilt eine Aufbewahrungsfrist der Daten im Backup von 14 bis 30 Tagen als angemessen. Längere Aufbewahrungen sollten dringend im Kontext der Datenschutz-Grundverordnung (EU-DSGVO) bewertet werden, da spezifische Gründe für die Aufbewahrung der jeweiligen Daten und Löschregeln zu definieren sind. Das kann nicht pauschal für alle Unternehmensdaten in der Datensicherung erfolgen. Zudem existieren für bestimmte Geschäftsunterlagen natürlich unterschiedliche gesetzliche Aufbewahrungsfristen, die individuell betrachtet und berücksichtigt werden müssen.
Unter diesen Prämissen lässt sich ein Backup/Restore anhand von einigen wenigen Kriterien definieren:
Unter diesen Prämissen kann ein BaaS unterschiedlich ausgeprägt sein.
Was bedeutet all das für einen sinnvollen Nutzen von BaaS in großen und global aufgestellten Unternehmen?
Zusammengefasst heißt das: BaaS erfordert, die Ziele und Erwartungen an eine Datensicherung zu schärfen und sie ebenso wie die Zuständigkeiten im Betrieb klar zu definieren. BaaS wird in großen Unternehmen und in der vorhandenen Applikationslandschaft keinen Ersatz aller bestehenden Backup-Workflows darstellen – aber für API-First-basierte Modelle kann es in Teilbereichen einen Nutzen bringen.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden für eine unternehmensweite Strategie zum Datenmanagement und zur Datensicherung – aber auch zu Desaster Recovery und Archivierung – zu informieren.

GitOps als Begriff findet sich im Kontext von Continuous Delivery und Automation für moderne, Cloud-native Applikationen. Ziel ist eine deklarative Beschreibung des gewünschten Zielzustands und deren automatisierte Umsetzung und Einhaltung. Aber was bedeuten diese Sätze in der Praxis?
Git und die verschiedenen Distributionen wie Gitlab, GitHub und BitBucket haben sich als Standard etabliert, um Code abzulegen und zu versionieren. In der Regel geschieht dies bei der Softwareentwicklung, das heißt, der Code für die entwickelte Software wird in einer Git-Distribution gespeichert.
GitOps setzt ebenfalls auf Git auf und legt zusätzlichen Code in Git ab, welcher die gewünschte Konfiguration, den Desired State, deklarativ beschreibt. Beispielsweise kann man hier festlegen, dass eine Datenbank in drei Brandbereichen oder Availability-Zonen verteilt laufen soll. Über einen GitOps-Controller wird diese Information aus Git bezogen, auf eine Zielumgebung angewendet und dieser gewünschte Zustand wird hergestellt.
Dies erfolgt jedoch nicht einmalig, sondern wird kontinuierlich überwacht. Wenn beispielsweise eine manuelle Änderung erfolgt, dann wird diese unmittelbar zurückgesetzt. Das bedeutet, jede Änderung einer Konfiguration muss in Code und damit im Git erfolgen.
Das hat mehrere Vorteile. Jede Konfigurationsänderung ist dokumentiert, da Git die Versionen verwaltet, und daher vollständig nachvollziehbar, beispielsweise auch im Rahmen eines Audits. Durch geeignete Freigabemodelle können auch Anforderungen eines Vier-Augen-Prinzips (Peer Review) erfüllt werden und die Freigabe durch eine oder mehrere Review-Rollen erfolgen. Und sollte sich eine Konfigurationsänderung in der Praxis nicht bewähren, kann dies in Git zurückgesetzt werden.
Das kann man sich ähnlich wie Datenbanken und ein Point-in-Time-Restore vorstellen – alle Änderungen in Git sind Transaktionen, die durch den GitOps-Controller ausgerollt werden. Und diese Änderungen können auf einen gewünschten Zeitpunkt zurückgesetzt werden.
Basierend auf diesen Eigenschaften kann GitOps als eine Strategie verstanden werden, um Applikationen und die dafür notwendigen Infrastrukturen automatisiert einzurichten und zu betreiben. Gerade für moderne Applikationen und Infrastrukturen wie Cloud Provider oder Kubernetes, die auf solche Automationsmodelle ausgelegt sind, etabliert sich GitOps als das verbreitete Modell zur Automation und zu einer Continuous Delivery.
Moderne Applikationen unterliegen zunehmend auch den Anforderungen nach einer kontinuierlichen Verfügbarkeit – 365 Tage im Jahr, 24 Stunden am Tag. Wenn GitOps der Grundbaustein des Betriebsmodells wird und alle Änderungen – vornehmlich als Standard-Changes, die sofort ausgerollt werden können – über Änderungen in der Git-Registry erfolgen, dann muss die Komponente Git bezüglich der Service- und Betriebszeiten den operativen Anforderungen genügen. Sie muss also den Vorgaben des Business Continuity Management unterliegen und beispielsweise hochverfügbar und sicher bis hin zu geo-redundant sein.
Neben den technischen und betrieblichen Aspekten müssen aber auch die Betriebsabläufe und die Arbeitsweise der Menschen im Unternehmen angepasst werden. Änderungen – und deren Nachvollziehbarkeit – beginnen in Git und manuelle Änderungen oder das Verwenden von Management-Tools direkt auf den mittels GitOps verwalteten Objekten müssen ausgeschlossen sein.
Weiterhin sind auch die Sicherheitsvorgaben anzupassen und auf das neue Modell auszulegen. Fragen wie „Wer hat wann welche Änderung ausgeführt?“ werden über die Auditierung und Versionierung in Git beantwortet und – je nach implementiertem GitOps-Modell – erweitert über Continuous-Delivery-Werkzeuge wie Jenkins, Tekton und andere.
GitOps ist im Vergleich zu klassischen Methoden für den Betrieb disruptiv zu sehen, es ändert viele Prozesse und Abläufe. Trotzdem ist GitOps attraktiv, da die einzelnen Applikationsteams wie auch die Plattformteams (Kubernetes beziehungsweise Cloud-native Application Plattform und Cloud Center of Excellence) ihre jeweilige Umgebung über GitOps deklarativ beschreiben und dies in ein Deployment überführen können. Das bringt eine Reihe von Vorteilen mit sich:
GitOps allein ist nicht die vollständige Antwort. Es muss erweitert werden um weitere Konstrukte wie Continuous-Delivery- und Deployment-Pipelines. Konstrukte wie Kubernetes Operator für eine applikationsspezifische Betriebsautomation, eine Teststrategie und Automation bis hin zu Monitoring-Lösungen für eine Ende-zu-Ende-Sichtbarkeit sind für das Gesamtkonzept notwendig – wie auch eine auf DevSecOps ausgelegte Kultur und Methodik.
Aber GitOps ist ein wichtiger Bestandteil und es empfiehlt sich, sich die Möglichkeiten von GitOps für das eigene Unternehmen genauer anzuschauen und zu bewerten.
Computacenter nutzt GitOps als einen Baustein im Aufbau und Betrieb von modernen Plattformen für Cloud-native Applikationen, für den Betrieb von cloudbasierten Plattformen und für Applikationen. Damit ist GitOps ein fester Bestandteil in unserem Beratungs-, Erbringungs- und Betriebsmodell.
Vereinbaren Sie gern einen Termin, um sich weitergehend über Erfahrungswerte und Methoden zu informieren.